Ah d’acc.
Mais si les calculs sont faits avec les données en piscines, on peut avoir par la même occasion des données valides quand elles entrent en bloc, non ?
Ah d’acc.
Mais si les calculs sont faits avec les données en piscines, on peut avoir par la même occasion des données valides quand elles entrent en bloc, non ?
Non il faut nécessairement refaire le calcul de distance au moment de l’écriture du bloc car il est possible que dans certains cas une très légère variation fasse basculer outdistanced de false a true.
Et ce calcul est trop complèxe pour être fait une fois à la fin de chaque bloc contenant un changement de certification ?
Oui, pour l’instant ça va encore mais avec N qui grandi le temps de calcul va croitre selon exp(N), il est impensable que chaque noeud duniter fasse ce calcul pour l’intégralité des membres a chaque bloc contenant un évènement wot !
EDIT : Attention il faut bien différencier deux types de calcul différents :
En effet je comprends mieux. Va pour pour des nœuds spécialisés.
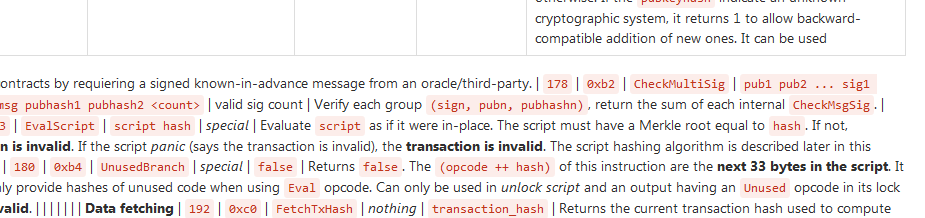
Sinon j’ai renommé CheckSig et CheckMultiSig en CheckDocSig et CheckDocMultiSig, et j’ai rajouté 2 nouveaux opcodes CheckMsgSig et CheckMsgMultiSig. Ces 2 derniers pourraient permettre la conceptions de contrats intelligents plus avancés à base d’oracles/tiers : on défini un contrat basé sur le résultat d’un événement : “Quelle équipe va gagner un match ?”, “Est-ce le vol va être annulé ?”. Les différentes réponses sont connues à l’avance et stockées dans le script, et seule la bonne réponse sera signée par l’oracle/tiers ce qui permettra de d’exécuter la partie correspondante du contrat.
Je vais rajouter un opérateur pour découper une valeur (split à telle position), on pourrait alors avoir dans le message une information unique (pour éviter la réutilisation hors contexte, le timestamp et un nonce par exemple) et des valeurs numériques, par exemple pour exprimer “Si telle valeur est supérieure à X”.
J’essaie de calculer plus précisément la complexité de ce calcul. Il y a plusieurs algorithmes possibles, j’étudie celui que j’utilise.
Définitions :
Nombre de membres : N
Nombre de référents : S <= N
Calcul et tri des référents [o(N log^2(N))], à faire une seule fois :
Calcul du nombre de référents atteints par un membre ou nouveau venu m [o(N^2 log^2(N))] :
Calcul du nombre de référents atteints pour tous les membres [o(N^3 log^2(N))] :
La complexité du calcul est donc majorée par o(N^2 log^2(N)) pour un membre ou nouveau venu et par o(N^3 log^2(N)) pour l’ensemble des membres (la complexité du calcul des référents est négligeable dans les deux cas).
Ce sont des valeurs qui grossissent rapidement avec N, mais qui ne sont pas exponentielles, simplement algébriques.
merci @gerard94, oui j’ai dit que ça évoluai exponentiellement sans avoir vérifier vraiment, ce que je voulais dire, c’est que c’est a mon avis trop couteux pour être fait par tout les nœuds !
Je trouvais que les idées étaient un peu floues autour de ce calcul (pas que pour toi). J’ai simplement voulu aider en précisant les choses. Au final, ce n’est pas un calcul inaccessible, mais effectivement coûteux.
J’aimerais ajouter un point annexe sur l’étude précédente. Pour construire des ensembles d’éléments, j’utilise des arbres de recherche, dans lesquels l’insertion, la suppression et la recherche d’un élément parmi N est en o(log(N)). J’utilise cet outil car c’est un vrai couteau Suisse informatique, permettant la création d’ensembles de façon efficace, mais qui, en plus, les maintient en permanence triés (ou non, au choix) sans coût supplémentaire. On peut aussi concaténer deux arbres, couper un arbre en deux, trouver le rang d’un élément, etc… de façon très efficace.
Mais dans le cas étudié, on a juste besoin d’ensembles, sans plus. On peut alors utiliser, pour la recherche et l’insertion, des clés de hachage avec un temps de calcul en o(1) (en général). Cela permet d’éliminer les log des formules précédentes et rendre le calcul (un peu) plus rapide.
J’ai modifié quelques op codes et rajouté des événements.
A part les événements manquants et la plan de déploiement, le document me semble plutôt complet. Est-ce que vous voyez des éléments à rajouter ?
Est-ce qu’on intègre les clés déléguées au calcul, ou en tout cas leur stockage sans pour autant permettre de les changer ?
De même, où en est la réflexion du changement de la preuve de travail ?
J’ai un problème de rendu sur le gitlab :
Je pense qu’il faudra traiter ça plus tard.
Ce serait bien de traiter la correction de la PoW dans la V11 par contre oui.
Corrigé.
Dac, par contre je vois mal comment le gérer en soft-fork.
Il faudra probablement une première temporaire ou les 2 modes seront compatibles et une seconde période pour seul le nouveau mode sera accepté…
En fait je m’égare un peu, au niveau des scripts c’est possible d’assurer des soft-forks, mais pour des changements de fonctionnement de la preuve de travail ça me semble plus compliqué et surtout inutile.
On pourra faire ce changement plus tard oui, après ça ne me semble pas vraiment hyper compliqué et on pourrait profiter de ce gros hard-fork pour l’ajouter.
Oui, il faut corriger la PoW dans la V11. C’est le meilleur moment vu le hardfork que ça va être… 
Alors il y a au moins 4 choses a intégrer en v11 selon moi pour la pow :
@nanocryk voilà comme tu me l’a demandé j’ai ajouté les évènements de type “toile de confiance”
Il manque encore les event de type V10 pour la transition, je les ferai un autre jours 
j’ai aussi supprimer un champ dans l’état : il n’est pas nécessaire de sauvegarder le blockstamp de révocation, cette info n’est aujourd’hui pas sauvegardée et n’est d’aucune utilité pour appliquer correctement le protocole. Elle n’est utile qu’a des fin de statistiques détaillés et sera de toute façon connue des noeuds d’archives qui eux garderont en mémoire toutes les transformations des “ev” dernières années a minima.
Autre subtilité : j’ai essayer de respecter le principe de réversibilité de chaque événement à lui seul, c’est a dire qu’il n’y a pas d’événements liés comme c’est actuellement le cas en v10.
C’est pourquoi l’événement joiner synthétise a la fois l’identité, l’adhésion ET les primo-certifications.
C’est également pourquoi j’ai conçu un événement a part pour l’expiration d’une certification qui causerait l’exclusion.
Il y a un point qui n’est pas clair pour moi et que je te laisse clarifier toi même : sous quel format doivent être enregistrez les clés publiques dans l’état ? Il me semble que tu a défini un format générique indépendant de tout algo mais entre tes généric key, compact key, hash key & co je ne m’y retrouve pas !
Il suffirait de définir la difficulté comme un entier tel que le merkle root > difficulté. Je vais regarder comment marche exactement la difficulté dans Bitcoin, l’avantage c’est qu’elle reste exponentielle.
Genial, je vais regarder ça.
On peut stocker sa date pour pouvoir l’oublier après une longue periode. Ca permettrait de réutiliser les pseudos et d’élaguer les anciennes identitées. Avec une durée assez longue on peut admètre que le risque d’usurpassion est assez bas.
Au moins c’est atomique, je regarde ça et je te fais un retour.
Toujours le format décrit au début, qui est lié a une monnaie, a un checksum et stocke le type de clé (algo de crypto, hash ou brut). A part dans cette partie explicative du format de clé, toutes les clés sont dans ce format.
Cool, c’est le seul des 4 points que je ne maitrise pas, du coup si tu peut t’en charger et nous faire une proposition de spec c’est parfait ![]()
Autant pour moi je n’avais pas pensé a cette feature, en effet il faut donc remettre ce champ dsl. je pense qu’il durée convenable serait de l’ordre d’une demi-vie, après tout ça correspond au temps “d’oubli” des différences a la moyenne, je trouverai élégant de prendre aussi 40 ans pour l’oubli d’une révocation du coup ![]()
Ok du coup comment nomme tu ce format ? J’ai besoin de nommer chaque concept pour m’y retrouver !
Je vais regarder ça oui.
Ca me semble cohérent. Il faudrait par contre réfléchir au changement de clé sans condamner un pseudo pour 40 ans.
This format (called an address) is structured as
Après ce format permet aussi de stocker un script complet/script hash pour pouvoir directement payer dessus, c’est donc pour ça que je parle uniquement de clé dans les scripts. Mais c’est des clés au format adresses, qui contiennent l’algo de crypto.
Tu remarquera qu’il est maintenant obligatoire de passer par une pubkeyhash pour gérer en soft-fork de nouveaux algos.