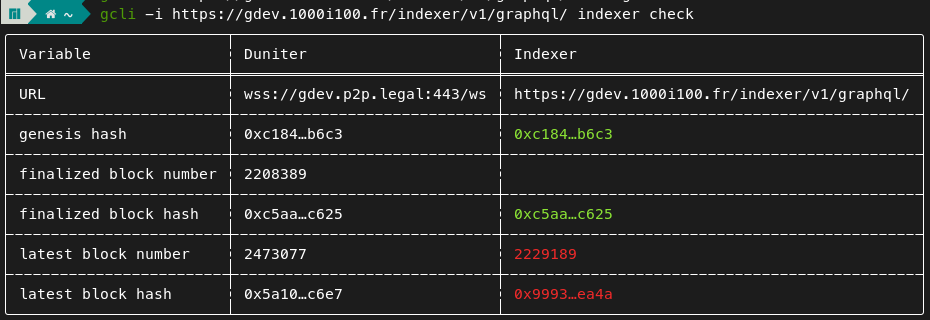
Et bloqué au bloc 2229189 visiblement :
Hello, j’ai installé un noeud archive et un squid avec hasura disponible sur le lien https://hasura.sleoconnect.fr/v1/graphql ![]()
5 Likes
Super ! Tu peux maintenant utiliser les variables DUNITER_PUBLIC_RPC et DUNITER_PUBLIC_SQUID indiquées ici : Duniter | Configure your node (Docker) pour partager tes endpoints publics sur le réseau, ce qui permettra aux clients de les découvrir automatiquement ! Ce n’est pas encore ajouté à la doc générale, mais ça fait partie des choses que j’ai à faire ![]()
1 Like
Heu, question bête : j’ajoute ces variables dans le stack (docker-compose sur portainer) de mon noeud mirroir ?
Oui exactement, voici mon docker compose de mon noeud duniter mirroir (et archive) par exemple:
services:
# duniter mirror archive node
duniter-archive:
# image: duniter/duniter-v2s-gdev-800:latest
image: duniter/duniter-v2s-gdev-800:900-0.10.1
restart: unless-stopped
ports:
- "9944:9944"
- "30333:30333"
- "9615:9615"
volumes:
- data-archive:/var/lib/duniter/ # this data can be large and takes time to be fully archived
environment:
- DUNITER_CHAIN_NAME=gdev
- DUNITER_PUBLIC_ADDR=/dns/gdev.p2p.legal/tcp/30333/ws
- DUNITER_PUBLIC_RPC=wss://gdev.p2p.legal/ws
- DUNITER_PUBLIC_SQUID=https://gdev-squid.axiom-team.fr
- DUNITER_NODE_NAME=poka-archive
- DUNITER_PRUNING_PROFILE=archive
volumes:
data-archive:
1 Like
ok top merci @poka !
Voici mon stack pour mémoire
services:
duniter-mirror:
image: duniter/duniter-v2s-gdev-800:900-0.10.1
restart: unless-stopped
ports:
# Prometheus
- 9616:9615
# RPC via http
- 9933:9933
# RPC API
- 9945:9944
# p2p
- 30333:30333
volumes:
- data-mirror:/var/lib/duniter/
environment:
- DUNITER_CHAIN_NAME=gdev
- DUNITER_NODE_NAME=Bulmananabelle-Docker-OMV-Gdev-Mirror
#- DUNITER_PRUNING_PROFILE=archive
- DUNITER_PUBLIC_ADDR=/dns/sleoconnect.fr/tcp/30333
- DUNITER_LISTEN_ADDR=/ip4/0.0.0.0/tcp/30333
- DUNITER_PUBLIC_RPC=wss://ws.bulmagdev.sleoconnect.fr/ws
- DUNITER_PUBLIC_SQUID=https://hasura.sleoconnect.fr/v1/graphql
volumes:
data-mirror:
Au cas où Hugo passe sur squid entre temps, j’ai fais une branche gtest où j’ai fais les premier changements pour la gtest, mais il me manque des artefacts en input que je n’arrive pas encore à récupérer, et py-g1-migrator ne veux plus se lancer en local sur macos.
Pour le moment squid est pensé mono réseau, il faudra le concevoir multi réseau à terme.
3 Likes
Pense-bête pour celui qui s’en charge en premier : il y a un souci dans Squid avec l’historique de DU par adresse. Déjà, il y a plusieurs requêtes qui semblent avoir la même finalité par des moyens différents, dont une qui attend un objet scalar identity en paramètre, ce qui n’est pas normal du tout. Mais surtout, aucune de ces méthodes ne retourne de DU : liste vide pour tous (gdev comme gtest).
Étonnant qu’on ne s’en soit pas rendu compte avant.
Je pense que getUdHistory est un computed field de udHistory que j’ai dû mal faire il y a longtemps, et qui ne semble même pas fini.
edit : Ok, j’ai dû relire le code de Squid pour comprendre, cette requête fonctionne :
{
identity(where: {accountId: {_eq: "g1LMJqNA37E3wZj1EEqHxzBDMnuaowr9Ftht713fYjVgqtffS"}}) {
name
udHistory {
amount
blockNumber
timestamp
}
}
}
→
{
"data": {
"identity": [
{
"name": "HugoTrentesaux",
"udHistory": [
{
"amount": 1000,
"blockNumber": 14402,
"timestamp": "2025-07-10T19:13:06+00:00"
}
]
}
]
}
}
C’est un computed field qui appelle get_ud_history(), lequel les calcule à la volée à partir des DU de universal_dividend et filtre avec les périodes de membership. C’est moi qui ai fait ça en plus, ça me revient…
La requête getUdHistory est visible dans le schéma GraphQL par effet de bord uniquement ; elle n’est pas faite pour être utilisée directement côté client. Je n’avais pas trouvé de moyen de la masquer du schéma.
udHistoryByPk ne fonctionne pas car il cherche dans une table ud_history qui n’existe pas dans Squid.
C’est un travail non fini mais qui se retrouve visiblement sur master. My bad.
Il faudra nettoyer, le plus simple étant de se passer des computed fields pour indexer chaque création de DU dans une vraie table directement.
Mais en tout cas, ce n’est pas bloquant : ça fonctionne en passant par identity → udHistory.
Dites moi ce que vous en pensez (indexer tous les DU par identité dans une vraie table vs continuer en computed field à la volée), en fonction je pourrais m’en charger.
4 Likes
On a décidé de les calculer à la volée volontairement, sinon ça ne passe pas à l’échelle. C’est pour cette même raison qu’on les calcule aussi à la volée côté Duniter.
3 Likes