Super ! Merci de venir en renfort, on manquait vraiment de gens, c’était compliqué d’être sur tous les chantiers à la fois, et l’indexeur occupe une place centrale nécessaire à plusieurs avancées (dont certaines de @guenoel pour son stage par exemple).
C’est normal que cet événement ne contienne qu’un Identity Index. Tout le reste comme
doit provenir d’ailleurs. Par exemple le blockIndex, c’est juste le numéro de bloc dans lequel est l’événement, donc ça doit être disponible pour tous les événements via l’api. Pour created_at, c’est quelque chose qui doit être déjà mémorisé dans l’indexeur, Duniter n’a pas vocation à garder dans le state le bloc de création de chaque identité. Signer, c’est pas forcément pertinent, une identité peut être retirée dans plusieurs cas de figure comme la révocation explicite par l’utilisateur ou le retrait automatique suite à la perte d’adhésion.
Je pense qu’il nous faudrait aussi une visio pour échanger sur les fonctionnalités de Duniter, je te propose dès que j’ai un peu de visibilité sur mon emploi du temps, probablement vers mi-avril.
Pour ce qui est de docker et gitlab, on pourra voir ensemble parce que je ne comprends pas vraiment le problème.
Pensez-vous qu’une solution hybride composée de l’agrégation dans Hasura des deux API GraphQL de l’indexer générique Subsquid et de l’indexer Duniter est possible et souhaitable ?
Ainsi, l’indexer Duniter n’aurait qu’à compléter les manques de Subsquid avec les spécificités de la June.
Et les devs des clients n’auraient qu’un seul endpoint GraphQL à interroger.
On pourrait agréger les API pour diminuer le nombre de endpoints, mais ça risque de mener à confusion, par exemple si l’un des deux services est désynchronisé.
De plus, l’indexeur générique subsquid est utile pour débugger, mais il n’indexe que les événements eux-mêmes, pas leurs conséquences. Donc pour l’utiliser, je cherche le numéro de bloc d’un événement, et je vais demander le contenu de ce bloc à un nœud archive. On peut reproduire ce schéma dans les applis dans un premier temps, mais à mon avis ce serait une solution temporaire en attendant qu’on implémente ce qu’il faut dans l’indexeur.
@HugoTrentesaux ça te dit une d’organiser une petit atelier Subsquid en partage d’écran sur jitsi, qu’on regarde ça ensemble pour ceux que ça intéresse ?
Au niveau de l’indexer v2s, est-ce qu’il ne serait pas possible de récupérer directement le schéma de tous les événements via un call avec tous leurs arguments ? Parce-que c’est assez fastidieux de reproduire chaque événement avec des tests pour les décortiquer dans les logs, puis d’appliquer la bonne requête correspondante.
Merci @ManUtopiK ,
Ca fait toujours plaisir de savoir que ce que j’ai fait est utile
Le dernier fichier où il reste des erreur est GraphiQL.vue. Il y a des erreurs principalement sur l’objet window et je me demande comment les traiter, manquant de compétence en Vue.js (il me semble que pour injecter des paramètres, il est préférable d’utiliser l’objet window.global ?!)
Pour l’erreur dans ma branche, ça y’est, c’est corrigé. Merci beaucoup du tuyau. @poka ==> peut être que ça résout ton problème ?!?
Pour gitlab, je suis preneur de conseil pour savoir comment mettre à jour ma branche avec les commit d’autres branches. Apparement, ça devrait arriver dans une prochaine version
Grâce à @ManUtopiK et @poka , j’ai pu bien comprendre comment fonctionne l’indexeur et je me suis donc permis d’améliorer la documentation pour les prochains qui passeraient par là
Je vais essayer de comprendre comment fonctionne les événements…
Et effectivement, une visio serait la bienvenue, quand tu pourras.
Enfin, je suis également partant pour en apprendre plus sur Subsquid
Oui effectivement, c’est difficile d’assurer une synchro parfaite de plusieurs sources.
En fait on a les informations de la blockchain sous des formes plus ou moins complètes :
Nœud sans archive : événements bruts éparpillés dans les blocs, 1 état minimum dans le dernier bloc (ex: derniers soldes).
Nœud archive : événements bruts éparpillés dans les blocs, tous les états dans chaque bloc (ex : historique des soldes).
Subsquid : liste des événements. Pas d’états visiblement.
Indexer V2S : les événements et états nécessaires aux clients selon nos besoins.
Ce qui m’intrigue encore c’est qu’un nœud archive contenant tous les états peut se construire à partir d’un nœud sans archive. C’est donc une indexation des états.
Il serait donc possible pour un indexer maison de retrouver les mêmes infos depuis un nœud sans archive ?
Gdev indexer a-t-il besoin d’un nœud archive ?
J’ai essayé d’ajouter l’événement identity.IdtyRemoved, sans succès.
Je reçois correctement l’événément dans Polkadot.js mais quand j’essaie de le capter dans l’indexer, ce dernier passe à côté…
Pensant que c’était moi qui m’y prenait incorrectement, j’ai donc tenté de capter un événément “transaction” déjà présent dans l’app. Et même phénomène, l’événement apparaît dans Polkadot.js mais l’app ignore complètement l’événément (et donc il est absent de la base de données).
C’est sûrement un petit détail qui m’échappe… pourtant, je suis tout proche de la solution.
Si une âme charitable venait à passer par là
C’est super que tu commences à prendre tes marques sur cet environnement !
@flodef on peut se refaire une session de peer programming (ou extrem programming comme tu dis aha) demain aprem vers 14h ou 15h si tu veux, sur ton écran cette fois ci pour voir ce que tu as commencé à faire ? Ou tu préfères Samedi ?
Ouuuuuuuuuuuui, je suis super partant pour Samedi 14h !!
En fait, le “pair” (peer, c’est la poire ) programming, c’est une seule des particularité de l’eXtreme Programming. Il y en a plusieurs autres comme les méthodes de tests, les feedbacks, les itérations courtes…
De ce que ce vois, j’ai l’impression que l’équipe dev fonctionne déjà un peu comme ça
Sinon, pour celles et ceux qui veulent découvrir, je vous recommande le lien wikipédia qui explique tout ça
Subsquid est un framework pour développer un indexeur. Pour l’instant il n’y a que les états dans le mien, car je n’ai rien implémenté, juste pris ce qui était disponible de manière générique pour substrate.
Ce que l’'indexeur fournit, plus que la donnée elle-même (tout est en blockchain), c’est une manière pratique d’y accéder en fonction de nos besoins. Par exemple, pour avoir la liste des transactions d’un compte, il faut parcourir tous les blocs, regarder les événements transactions, et regarder s’ils concernent ce compte. Pour avoir l’historique des soldes d’un compte, il faut parcourir tous les blocs et regarder la valeur du chain state pour ce compte.
Par rapport à l’idée d’un indexeur maison qui retrouve les mêmes infos, le problème est qu’il doit prendre tout en compte parce que d’autres choses que les transactions peuvent faire varier le solde d’un compte : réclamation des DU, frais d’extrinsics (y compris hors transaction), votes de trésorerie, offences… Donc quitte à implémenter les transformations d’états à partir des blocs (transitions d’états), autant prendre le logiciel qui le fait, à savoir Duniter !! Donc un indexeur se branche généralement à un nœud d’archive local pour accéder rapidement à la donnée dont il a besoin.
Une curiosité que j’arrive pas à expliquer depuis le début sur cet indexer: Il m’est impossible de récupérer plus de 100 items par requête sur l’API relay, même de manière paginé.
C’est à dire que l’API renvoi hasNextPage false une fois qu’on atteint 100 item au total depuis le début, même avec des pages de 20 items par exemple.
Curieusement, au travers le console hasura directement, je n’ai pas le même comportement, j’arrive bien à récupérer tous les items jusqu’au dernier, que ce soit de manière paginé ou non d’ailleurs.
(avec ce curseur: eyJjcmVhdGVkX2F0IiA6ICIyMDIzLTAzLTA5VDE2OjA1OjEyLjAwMSswMDowMCIsICJpZCIgOiAyNDM5, et pensez à bien cocher “API relay”)
Via graphiql, on obtient qu’un seul élément, quelque soit ce qu’on met en first., et le bool hasNextPage à false. Même comportement sur Gecko web.
Mais si vous essayez sur la console hasura de la même instance (mot de passe: your_secret), vous aurez bien l’ensemble de la page et hasNextPage à true, car vous êtes admin.
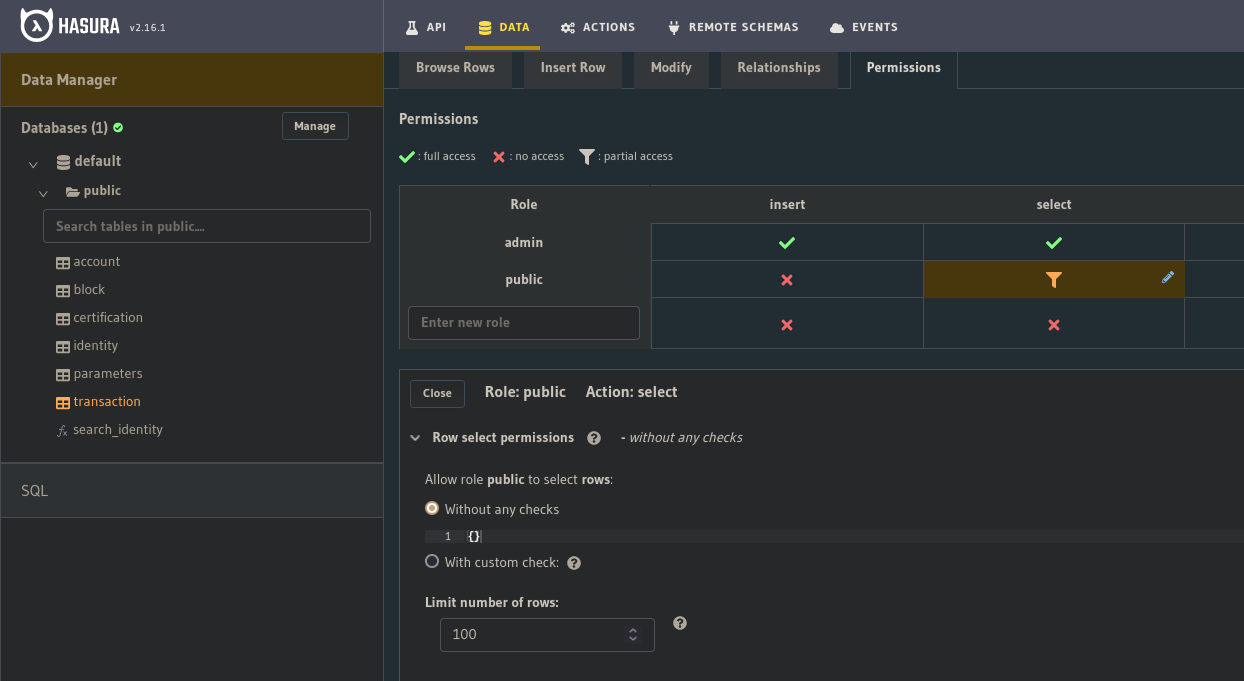
Ca correspond donc aux limitation inscrites côté hasura sur la table transaction:
igraphql était mal configuré (url en localhost interdisant d’obtenir la complétion et l’aide du schéma) quand je m’y intéressais. C’est peut-être toujours le cas et ce problème aurait sa cause dans une erreur de config aussi. Je dis ça pour aider… mais j’en sais rien hein
En effet je ne sais pas pk le container indexer était coupé, je viens de le redémarré. Le soucis de localhost a été reglé.
Si vous avez l’erreur field 'transaction_connection' not found in type: 'query_root' lors de l’execution de la requête proposé, pensez à activer le switch API relay.
Le problème que je soulève se traduit par la limitation aux 100 premiers éléments en scrollant dans les encarts présents en page d’accueil de gecko web (videz votre cache), ainsi que dans l’historique des transactions de chaque adresse, sur web ou mobile.
Pour moi ce comportement est anormal, j’ai donc ouvert une issue, car je ne trouve aucune information à ce sujet.
$ gcli indexer check
wss://gdev.p2p.legal:443/ws and https://hasura.gdev.coinduf.eu/v1/graphql have the same genesis hash: 0xf9bb…0dfc
$ gcli indexer latest-block
latest block indexed by https://hasura.gdev.coinduf.eu/v1/graphql is: 0
Gcli arrive bien à contacter mon indexeur, qui lui répond qu’il a le même genesis hash que le noeud Duniter de @poka et dit qu’il est toujours en train d’indexer le bloc 0.
[edit] ça y est, il a fini le genesis !
gcli indexer latest-block
latest block indexed by https://hasura.gdev.coinduf.eu/v1/graphql is: 68298
(par contre, toujours pas de smith, il va falloir que je débugge ça)
J’ai débuggé, c’était encore un problème de format entre le genesis de dev et de prod : Duniter était trop permissif sur le format, et l’indexeur ne savait pas au quel se fier. Donc pour la suite il faudra vraiment se caler sur le format du genesis gtest pour l’indexeur. Tant pis si on perd la compatibilité avec le genesis gdev dont l’utilité est principalement la flexibilité pour les tests d’intégration.
Par contre, il y a toujours un problème de schéma détecté par le playground : la console hasura sait très bien faire la requête, mais le playground retourne une erreur.
L’indexeur est en train d’indexer, il a dépassé le bloc 100 000. Par contre, il y a quelques erreurs d’indexation, il faudra surveiller ça. Peut-être des incohérences des données.
résoudre le schéma détecté par le playground (pas de smith dans pnpm schema)
observer et comprendre l’origine des erreurs rencontrées lors de l’indexation
Hello,
Dites moi si je dois mettre ceci dans un nouveau sujet dans le forum:
Je constate que les certifications de Pini reçues par Vit sont en double et que le “validated_at” est à “null”
Par ailleurs dans polkadot.js.org/app le “smithsMembership.membership” de vit est à <none> . Parce qu’il n’a pas encore effectué le claimMembership() ?