Tu vois d’autres poblèmes du coup ? J’ai d’autres idées à rajouter à ça mais je vais attendre qu’on ai réglé toutes les questions en cours.
1 Like
Ben si on part sur une source unique UUD0 par membre il faut comptabiliser le montant sans base, sinon on est obliger de stocker séparément les couches de chaque base. Ou alors il faut rouler la base ainsi :
→ Arrivée d’un bloc DU avec un unitBase +1
→ Recalcul du UUDO unique de chaque membre → nouveau montant
→ Traitement des tx, refus de certaines dans les cas limites (le montant total de DU dépensable ayant varié)
Après il y a sans doute de nombreux autres problème qu’on ne voient pas maintenant et qu’on ne verra qu’en faisant ![]() (je parle de tout le protocole en général la).
(je parle de tout le protocole en général la).
Dans ce cas là le montant des inputs UD doivent être en (amount, base), sinon il pourrait arriver qu’une personne envoi par erreur 10x fois plus que prévus a quelqu’un, ce qui n’est clairement pas acceptable.
Mais sinon oui ce montant UUD est sans base (il utilise la base commune définie dans le block), et est recalculé à chaque changement de unitBase.
1 Like
Oui le client doit écrire dans son doc tx les inputs DU en (amount, base) sinon son montant peut etre réinterprété en effet ![]()
Nous sommes d’accord ![]()
1 Like
Y a plus qu’a écrire ce point dans la RFC avant qu’on oublie 
Parfait !
Si c’est okay pour partir dans cette approche d’état alors je vais modifier ma RFC. Ca semble ok pour tout le monde ? @elois @Inso @cgeek (d’autres personnes que j’ai oublié ![]() ?)
?)
Dernier point il me semble : je voudrais aborder “sauvegarde du consensus”. Vu que l’on stocke l’état au fur et à mesure, il est possible d’oublier des états anciens après la période de résolution de fork. Cependant, il doit toujours être possible de prouver que la chaine ne sort pas de nul part et qu’elle hérite bien du genesis (on pourrait par convention définir le hash du bloc précédent au genesis à 00000…).
Tout d’abord, très simple, il suffit de stocker la première couche (previous_root, signed et signature) de chaque block et avec ça il est possible de remonter toute la chaine de preuve jusqu’au HEAD actuel.
On peut ensuite par dessus ça utiliser un Merkle tree pour garder ce lien avec le genesis sans devoir retenir tous les blocs intermédiaires.
Voila un exemple pour un HEAD compris entre 8 et 15.
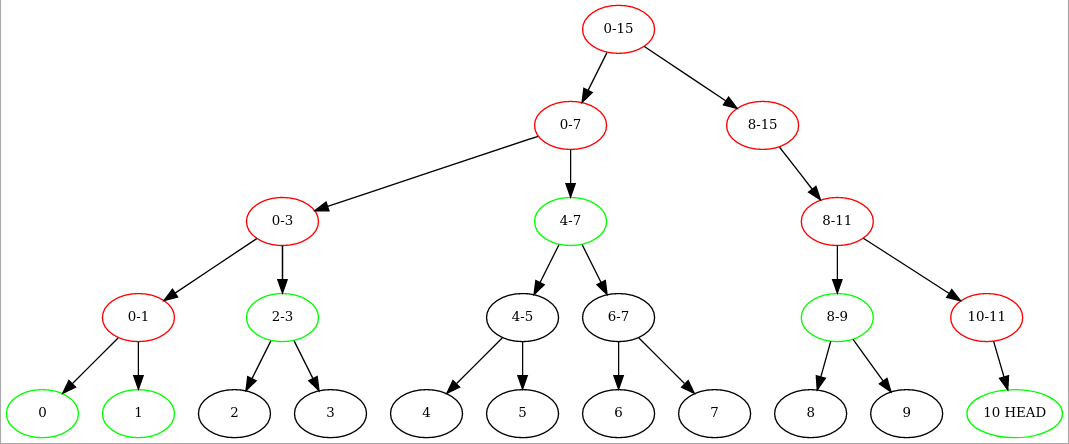
Seuls les informations en vert sont à garder et permettent de recomposer les rouge. On applique ensuite la meme construction pour plus de blocs. Ainsi pour garder la preuve qu’on est n blocs après le genesis il nous suffit de moins de 2log2(n) hashs. Cette information pourraient être conservée dans le Merkle tree de chaque bloc et être vérifie par chaque noeud. Ca ne rajoute pas grand chose en complexité mais permet de très clairement gagner de la place tout en gardant la même sécurité pour montrer qu’on dessend bien du bloc genesis.
Edit : nouveau schema qui montre mieux comment se comporte le HEAD. Bien evidement pour ce nombre de blocs on les stockerais tous pour gérer les forks, mais avec un plus grand nombre de blocs (je ne ferais pas de schema hein ![]() ) ça permettrait “d’oublier” les anciens blocs sans oublier la preuve de travail.
) ça permettrait “d’oublier” les anciens blocs sans oublier la preuve de travail.
Note : si vous avez d’autres idées pour améliorer ce système, n’hésitez pas ![]()
Le block précédent du block genesis a comme hash le hash d’une chaine vide ![]()
E3B0C44298FC1C149AFBF4C8996FB92427AE41E4649B934CA495991B7852B855
Si je comprends bien ton algo :
- Au bloc 0, le blockchain_merkle_root vaut
empty_hash - Au bloc 1, le blockchain_merkle_root vaut
hash(empty_hash, hash(0)) - Au bloc 2, le blockchain_merkle_root vaut
hash(bloc(1), blockchain_merkle_root(1)) - Au bloc 3, le blockchain_merkle_root vaut
hash(bloc(2), blockchain_merkle_root(2))
Sinon de manière générale, ton fonctionnement est intéressant pour les noeuds légers (Raspberry etc). Ca leur permettra de participer à l’avancée de la chaine sans consommer trop de ressources.
- Lorsqu’un noeud léger se synchronise pour la première fois, il ne télécharge que les éléments nécessaires sur le chemin de merkle lui permettant de reconstituer la preuve de merkle.
- Il télécharge tous les arbres des états de la chaine et vérifie avec des arbres de merkle que l’état est cohérent avec ce qu’il a téléchargé
- Le noeud léger ne télécharge donc plus la blockchain complète. La synchronisation est beaucoup plus rapide.
Il faudrait cependant garder le fonctionnement “full sync” actuel permettant de plug des API clients, de l’historisation etc.
3 Likes
Quand on fonctionne avec des chaînes de caractères ![]() Je pense que ça serait pratique d’avoir un hash(bloc -1) = 0, ça se voit direct (un hash de 0 ça ne se voit pas tous les jours), aucune valeur magique à calculer.
Je pense que ça serait pratique d’avoir un hash(bloc -1) = 0, ça se voit direct (un hash de 0 ça ne se voit pas tous les jours), aucune valeur magique à calculer.
Au bloc un on a hash(bloc(0), bloc(0)), sinon le reste est bon. A chaque bloc on a alors la preuve que c’est la suite du block précédent, et ensuite qu’il hérite bien du genesis sans avoir à garder tout l’historique.
Certaines personnes pourront le garder si elle veulent garder l’historique oui, et il devrait donc être possible de se déclarer “full-history” sur le réseau.
On pourrait se mettre d’accord sur des termes du coup ?
- Full node/nœud complet : possède l’intégralité de la blockchain
- Light node/noeud léger (pruned node) : possède la fin de la blockchain (fenetre de fork) plus la preuve pour remonter à genesis.
- Client : se connecte à un nœud léger/complet pour demander des infos, et ne stocke que ce qui l’intéresse (id des transactions, certifications, etc). Suivant s’il se connecte à un nœud léger/complet, il aura plus ou moins de fonctionnalité (avec un light node, il n’aura pas l’historique complet, mais seulement les UTXO et celles dépensées récemment).
Si c’est bon pour cette partie là, des remarques sur la structure générale ? Des parties floues, ou des trucs manquants ? Si tout est bon je vais l’intégrer à la RFC, et après review on adoptera cette structure pour Duniter 2.0 ![]()
Je pense qu’il va falloir patienter un peu pour avoir une relecture de @cgeek et @elois de toute manière (ils ont l’air bien occupé avec leurs releases).
Je pense que ça vaut le coup de formaliser nos discussions dans la RFC, ça sera plus simple pour eux pour rattraper le fil de nos pensées.
1 Like
Je vais faire ça du coup.
1 Like
Du coup pour les sets de documents (UTXO, membre) tu penses qu’il vaut mieux utiliser les radix tries ou de simple binary tries ? Vu qu’on a toujours un document qui stocke la liste des données (pour empecher les omissions), on peut obliger qu’elle soit triée et s’en servir pour distribuer les documents dans un binary tree, et ainsi éviter toute la construction du radix tree, tout en ayant une structure qui requiert en moyenne des preuves avec moins de hashes qu’avec les radix.
Je te ferais un schema tout à l’heure si tu ne vois pas ce que je veux dire.
Edit : un peu comme le schema pour les Merkle roots, on les trie et les disposent sur la dernière couche, et en ayant le nombre d’élément et l’index de l’élément on sait quelle branche suivre. Et vu qu’on cherche à minimiser la taille de la preuve de Merkle, il me semble que ça soit la solution la plus opti (et qui reste très simple à mettre en place et à utiliser).
1 Like
Remarques rapides :
Cette information est extrêmement coûteuse, en fait c’est la plus coûteuse de toutes dans Duniter. Il suffit de consulter g1-monit/willMembers pour s’en rendre compte qui n’effectue pourtant qu’une centaine de calculs.
Alors, stocker cet état à chaque bloc, potentiellement pour plusieurs dizaines de milliers de membres, pour l’instant c’est clairement infaisable. J’avais bien cette problématique en tête depuis le début de uCoin et c’est pour cela que ce calcul n’est effectué qu’à la soumission d’une adhésion.
J’avais soutenu qu’au mieux, à 1.000.000 de membres et 1 renouvellement par an (c’est optimiste, on pourrait tabler sur 2), alors on aurait en moyenne 9 calculs de distance par bloc. Ce qui est déjà délicat, mais acceptable.
De manière générale dans nos raisonnements il faut veiller à ce point. En soi, le calcul Merkle ne coûte pas vraiment cher. Par contre la donnée sous-jacente le peut.
Non ça ne marche pas. Exemple : un compte C1 possède 1,01 G1. Il envoit 1,00 G1 à C2, il reste 0,01 G1 sur l’ancien compte. Sans vidage de compte, la base de données est polluée.
Quid des dossiers-feuilles, comme Inso et Insoleet ?
L’idée est très intéressante, et quitte à utiliser cette idée pour les DU, autant le faire aussi pour les comptes TX : car pour le vidage des comptes à moins de 1,00 G1, on définit la notion de compte = 1 condition de sortie. Par exemple il existe le compte :
(SIG(HgTTJLAQ5sqfknMq7yLPZbehtuLSsKj9CxWN7k8QvYJd) && XHX(309BC5E644F797F53E5A2065EAF38A173437F2E6))
Bon sur le coup j’ai trouvé l’idée géniale (et en fait assez naturelle), néanmoins comme @elois j’ai quelques doutes. Notamment Bitcoin n’a pas choisi ce mode de fonctionnement, je me demande pourquoi. Je vais y réfléchir, je vous invite à faire de même ![]()
le but ici n’est ps d’empêcher que des comptes trainent des centimes, mais d’empêcher de créer des milliers de portefeuilles facilement. Ce qui compte c’est de se protéger contre le spam de portefeuille, pas d’un solde particulier.
Si j’ai 1000g1 je ne pourrait spammer que 100 portefeuille dans les 2 cas, et le cas sans destruction de monnaie est considérablement plus simple a gérer !
L’information “outdistanced” qui est dans l’url requirements est calculée à quel moment ?
La transaction peut être interdite justement (une adresse en output se retrouve avec 0.01, et est donc interdite).
J’imagine que ce n’est pas compatible avec le fonctionnement par adresse puisqu’elle ne révèle pas quelle pubkey possède la monnaie ![]() Ca marche pour les DU puisque la monnaie est directement associée à la pubkey.
Ca marche pour les DU puisque la monnaie est directement associée à la pubkey.
1 Like
Je suis tout à fait d’accord, il faudrait voir comment ça pourrait s’intégrer (ou pas). Ce qui est interessant avec cette approche c’est qu’on pourra facilement rajouter de nouvelles choses dans l’arbre de Merkle et de l’activer via vote, ce qui empêchera tout fork.
Les “comptes” n’existent pas, et dans la RFC les sorties doivent être explicites et la somme des inputs doit être strictement égale à la somme des outputs.
Je viens d’avoir une potentielle idée (edit: @cgeek je n’avais pas tout à fait compris ton idée, qui s’est avéré être la même que j’ai eu après. Parfait, on est sur de se comprendre comme ça ![]() ). Toutes les UTXO qui possèdent le même output script peuvent être accumulées dans la même entrée, et on défini comme input le “script hash” sur lequel on veut puiser. Ça prend en compte n’importe quel “compte” classique ainsi que les multi-sigs par exemple
). Toutes les UTXO qui possèdent le même output script peuvent être accumulées dans la même entrée, et on défini comme input le “script hash” sur lequel on veut puiser. Ça prend en compte n’importe quel “compte” classique ainsi que les multi-sigs par exemple
Le seul point qui me gène pour cette option là c’est que j’ai ajouté un opcode FetchOutputAmount qui permet de récupérer de mettre des conditions sur comment va être consommée cette source en terme de valeurs. Hors si 2 transactions ayant cette même condition se regroupent, et que tous les outputs ont une valeur obligatoire, alors l’argent pourrait être blocké. Ceci-dis, si on fonctionne avec ce système d’agrégation alors ça ne devrait pas poser de problème, on dit combien on prend sur l’adresse et le surplus reste dans le script hash originel. Il faudrait réfléchir sur ce genre de cas (et avec les opcodes que j’ai défini) mais ça me semble faisable.
Avec cette technique là on évite alors un grand nombre de spams de transactions, et on défini qu’un “script hash” ne peut pas contenir moins de 1 G1, sinon cette monnaie est détruite. Il suffit alors d’avoir au moins 1 G1 sur son compte pour accepter autant de paiements de 0.01 G1 (ou n’importe quoi en dessous de 1 G1) que l’on veut.
Bitcoin est la première blockchain et elle loin d’être parfaite. Tu noteras que je me suis inspiré de structures de données d’Ethereum pour pondre ça ![]() Après si ça vous semble bon on pourra implémenter une version de test et essayer de l’attaquer.
Après si ça vous semble bon on pourra implémenter une version de test et essayer de l’attaquer.
Tu te trompes. Avec 1000 Ğ1 tu peux créer 1000*100 - 1 comptes.
edit : ah non je retire, l’argument donné par Inso m’a convaincu. Si l’on raisonne en sources effectivement ça semble marcher.
1 Like
Une “adresse” n’existe pas, c’est simplement un lock script, qui peut définir des multi-sig ou des trucs plus complexes. Mais on pourrait généraliser cette association “adresse” ↔ “lock script” et stocker directement les balances comme suggéré par cgeek.
Note : dans la RFC je défini des opérateurs pour gérérer des “adresses” qui masquent la clé publique tant qu’elle n’est pas consommée.
Sur appel. Ce qui est une belle connerie car ça plombe énormément le noeud appelé !
Bof, tu peux très bien dire 1 compte = 1 adresse. Tiens bah d’ailleurs @nanocryk semble partir sur cette voie ![]()
1 Like
Oui c’est vrai. Ce que vous voulez dire, c’est associer un montant à un hash de lock script plus générique (qui peut contenir autant de contrat que l’on souhaite). Et que donc 2 transactions vers le même lock script mettrait à jour le même montant ?
Ca me semble pas mal, surtout que ça économise beaucoup de place tout en réduisant les risques de fork (moins de situation “collision”).
2 Likes
A noter qu’il doit être possible assez facilement de conserver la logique de chaînage des transactions, par un moyen dont je n’ai pas encore idée mais qui me semble tout à fait possible.
1 Like