Aujourd’hui j’ai travaillé sur :
- La configurabilité de GVA (uniquement via le fichier
conf.jsonpour le moment) - La création de la doc de configuration de gva
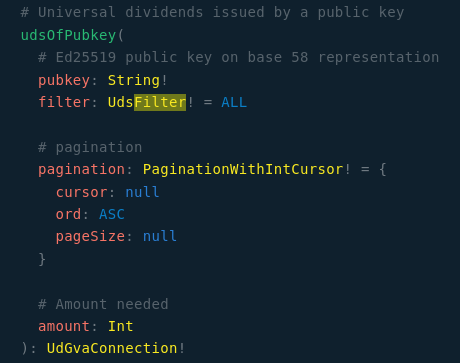
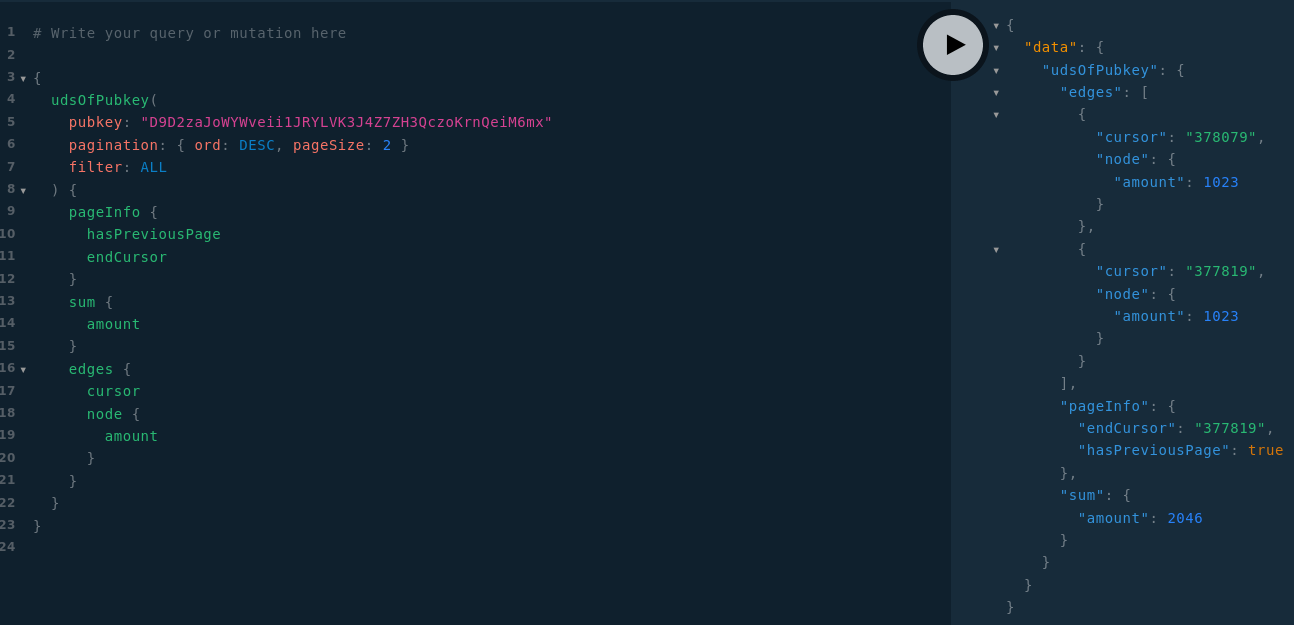
- La génération des endpoint GVA et leur ajout dans la fiche de peer
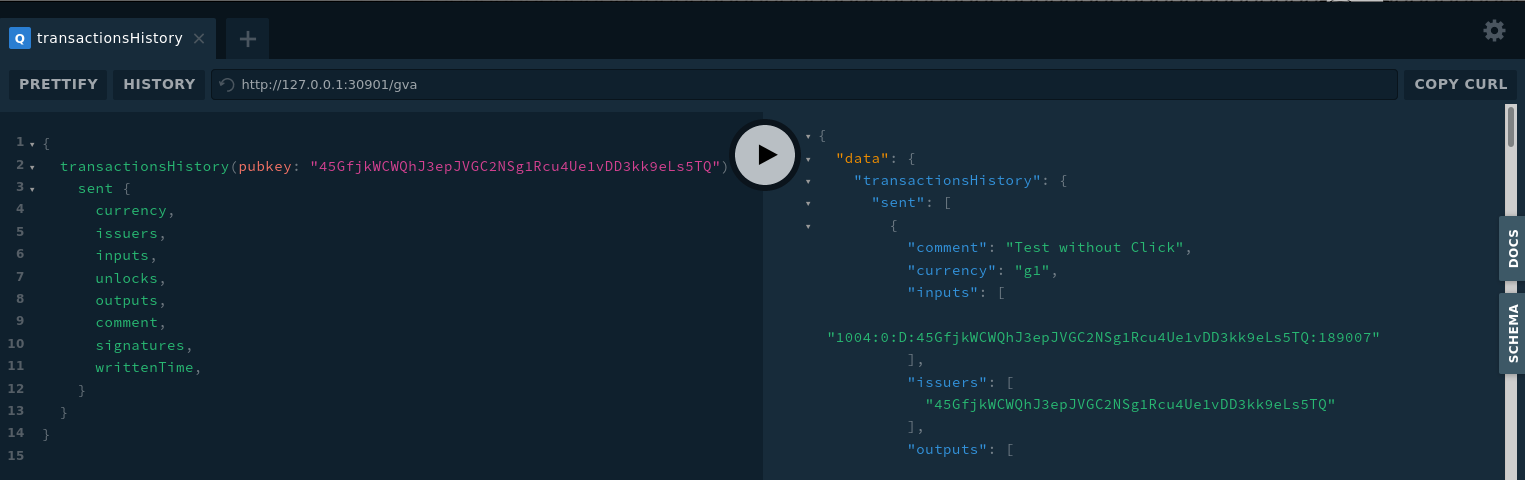
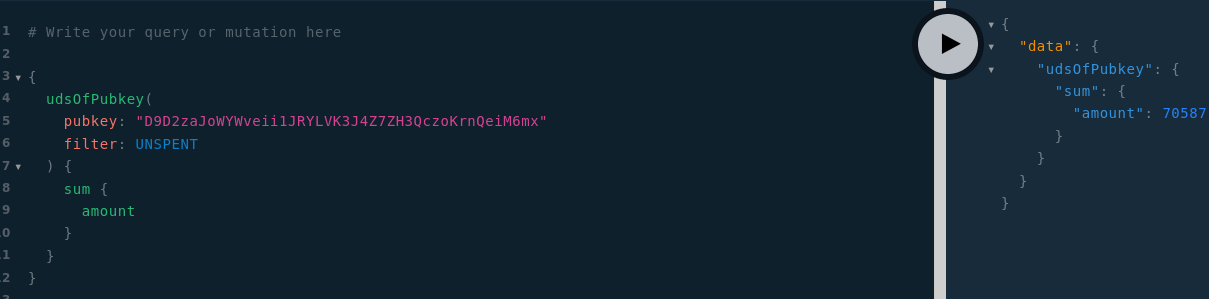
- La récupération de la fiche de peer du nœud via GVA:

J’ai gardé les mêmes conventions que pour les autres types d’endpoint à une différence près : la couche TLS est explicitée par un S. Cela permettra à ceux qui le souhaitent de pouvoir fournir un endpoint sécurisé sur un autre port que 443 (via l’option remoteTls, voir doc).
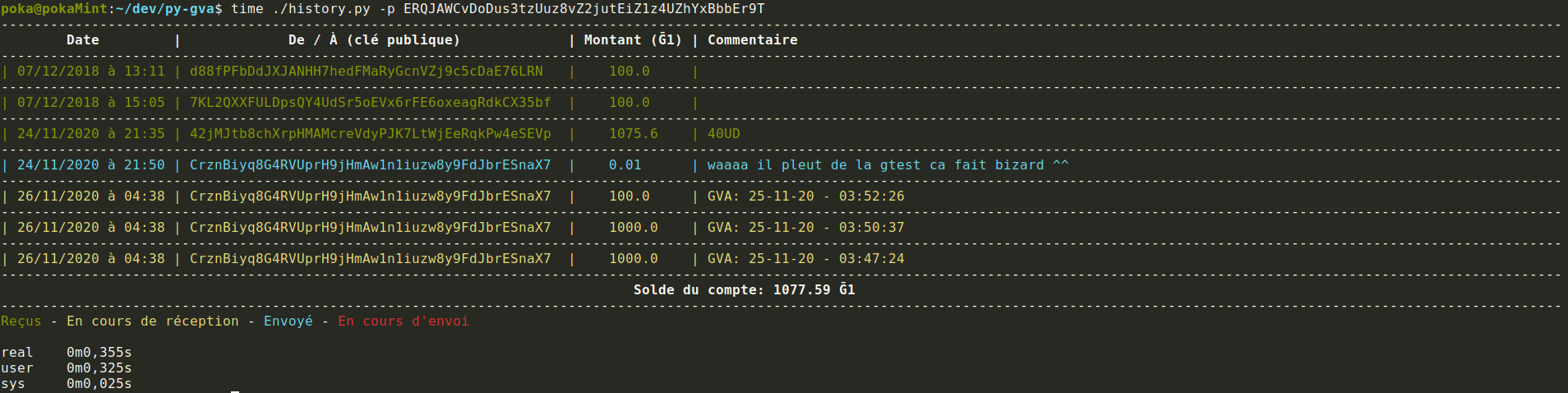
Maintenant j’aurais besoin qu’un ou deux d’entre vous essayent de mettre en place un serveur GVA, voici comment faire :
-
Compilez manuellement Duniter sur la branche
gva-proto-2 - Indexez la db de GVA, 2 méthodes possibles :
A. Avec la commandedex migrate(nécessite de compiler le binaire dex au préalable). L’indexation prend environ 2 minutes ce qui est bien plus rapide que de resynchroniser Duniter, donc même en comptant le temps de compilation de dex cette méthode devrait rester plus rapide.
B. Vous pouvez aussi resynchroniser Duniter avec l’option--gva(duniter sync --gva g1.duniter.org) mais cette méthode est plus longue forcément - Configurez GVA en modifiant directement le fichier conf.json, voici ma conf par exemple :
{
...,
"gva": {
"host": "localhost",
"port": 30901,
"path": "gva",
"subscriptionsPath": "gva-sub",
"remoteHost": "g1.librelois.fr",
"remotePort": 443
}
}
- Lancez votre nœud duniter avec l’option
--gva(nécessaire car gva est encore désactivée par défaut) :duniter start --gva - Ouvrez l’url
http://localhost:30901/gvadans votre navigateur (ou l’url adaptée a votre configuration le cas échéant). - Faite moi un retour
Merci