This is what it is looking like today, approx. 22 hours after 0.40 started to be used:
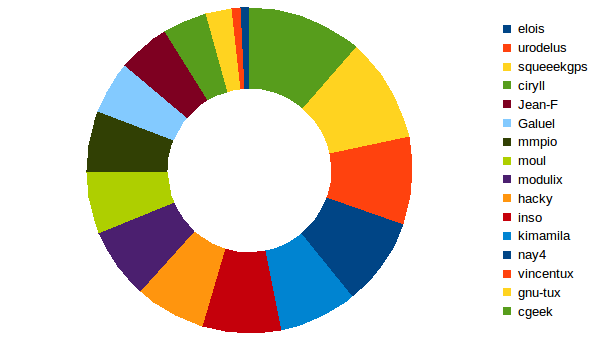
I bet this will be even more homogeneous in few days.
This diagrams represents the last 115 blocks of TestNet. A full day is made up of 288 blocks (60’ x 24 / 5’ = 288), so the data only reflects the new usage in a limited period of time, excluding the issuers of the last 24H which were still using v0.3 protocol at that time.