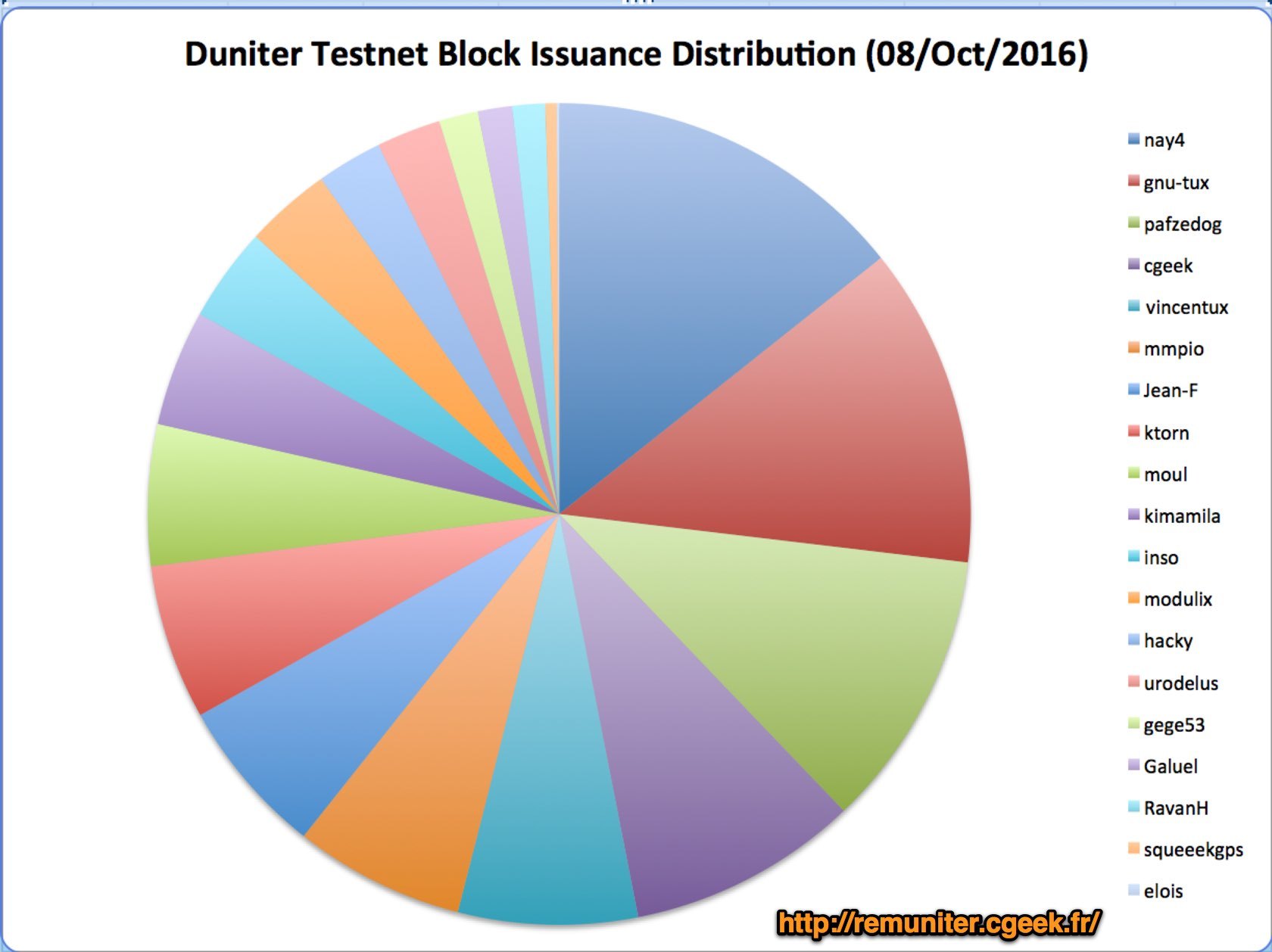
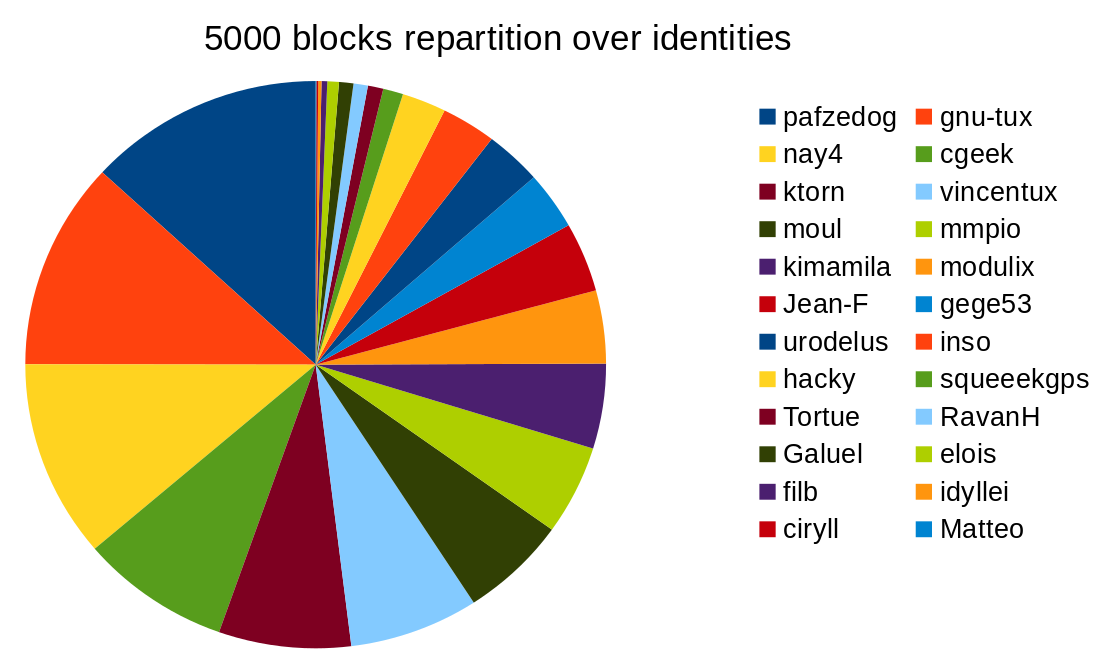
J’ai sorti les données en graphe sur la fenêtre courante ce matin :
C’est en effet clairement moins équitablement réparti que dans la précédente version.
J’ai déjà réfléchi à cette observation ce week-end, et j’ai été tenté de modifier la formule pour que le handicap soit exponentiel de la façon suivante :
Rappel de la formule DUP 0.5 :
PERSONAL_DIFF = PoWMin + PERSONAL_HANDICAP
Sachant que PERSONAL_HANDICAP > 0 dès lors que l’on dépasse la médiane de nombre de blocs émis par membre dans la fenêtre courante. Ainsi l’on a, pour une médiane à 6 blocs :
- un handicap de 0 pour le prochain bloc si l’on a émis 5 blocs
- un handicap de 1 pour le prochain bloc si l’on a émis 6 blocs (+19% de difficulté)
- un handicap de 2 pour le prochain bloc si l’on a émis 7 blocs (+41%)
- etc.
J’ai donc été tenté, pour un hypothétique DUP 0.6, de faire :
PERSONAL_DIFF = PoWMin + FLOOR(EXP(PERSONAL_HANDICAP))
Ce qui aurait donné :
- un handicap de 0 pour le prochain bloc si l’on a émis 5 blocs
- un handicap de 2 pour le prochain bloc si l’on a émis 6 blocs (+41% de difficulté)
- un handicap de 7 pour le prochain bloc si l’on a émis 7 blocs (+235%, ça gratte un peu)
- un handicap de 20 pour le prochain bloc si l’on a émis 8 blocs (+3088%, ça commence à piquer)
- un handicap de 54 pour le prochain bloc si l’on a émis 9 blocs (+1 147 578%, c’est punitif)
- etc.
Alors, comme ça, on se dit “chouette, ça roxxe, c’est plus équitable”. Oui mais ce n’est pas sans conséquence : on en revient plus ou moins à la situation DUP 0.4, où une partie des calculateurs est purement et simplement exclue du calcul au bout de quelques blocs émis au-dessus de la médiane. Ce n’était pas le but recherché avec la 0.5.
Après, je dois dire que ça ne me gêne pas d’implémenter cette logique, si vous jugez que cela est préférable à la 0.5 actuelle. Au final, DUP 0.5 et 0.6 auront simplement lissé le comportement de la 0.4, qui était infiniment plus punitive : dès que l’on calculait un bloc, on se voyait exclu du calcul tant que suffisamment d’autres membres n’avaient pas eux-mêmes calculé de blocs.
A noter quand même que la situation actuelle est toujours un rapport de puissance personnelle sur la puissance totale, et donc plus le nombre de participants augmente, plus cet écart est faible.
C’est comme vous le souhaitez.