A noter que je ne prendrai pas le risque de vous annoncer qu’il s’agissait de la dernière, je me suis déjà fait avoir sur la version précédente ! Toutefois, ce ne sera pas pire qu’en v1.2.4.
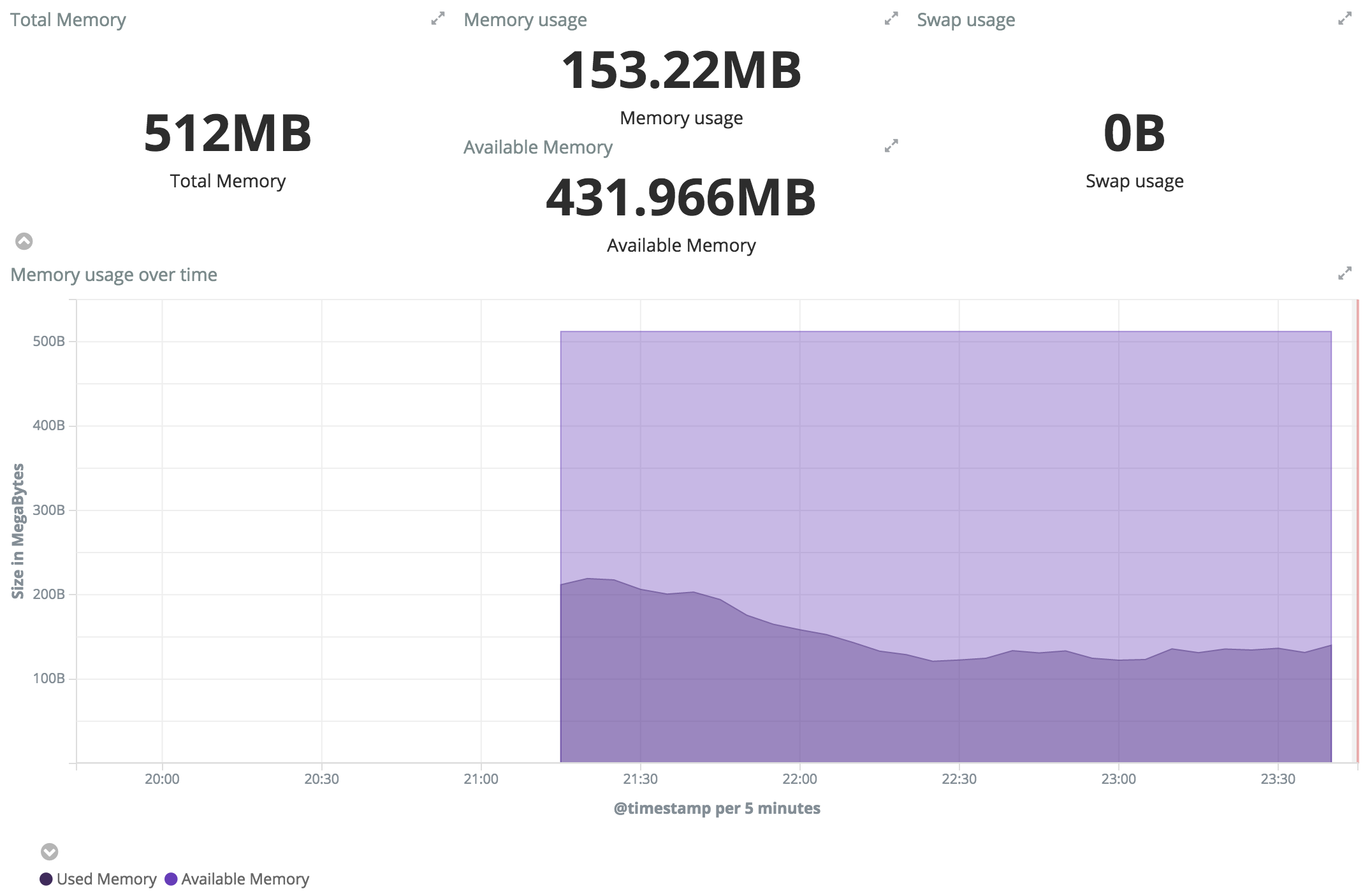
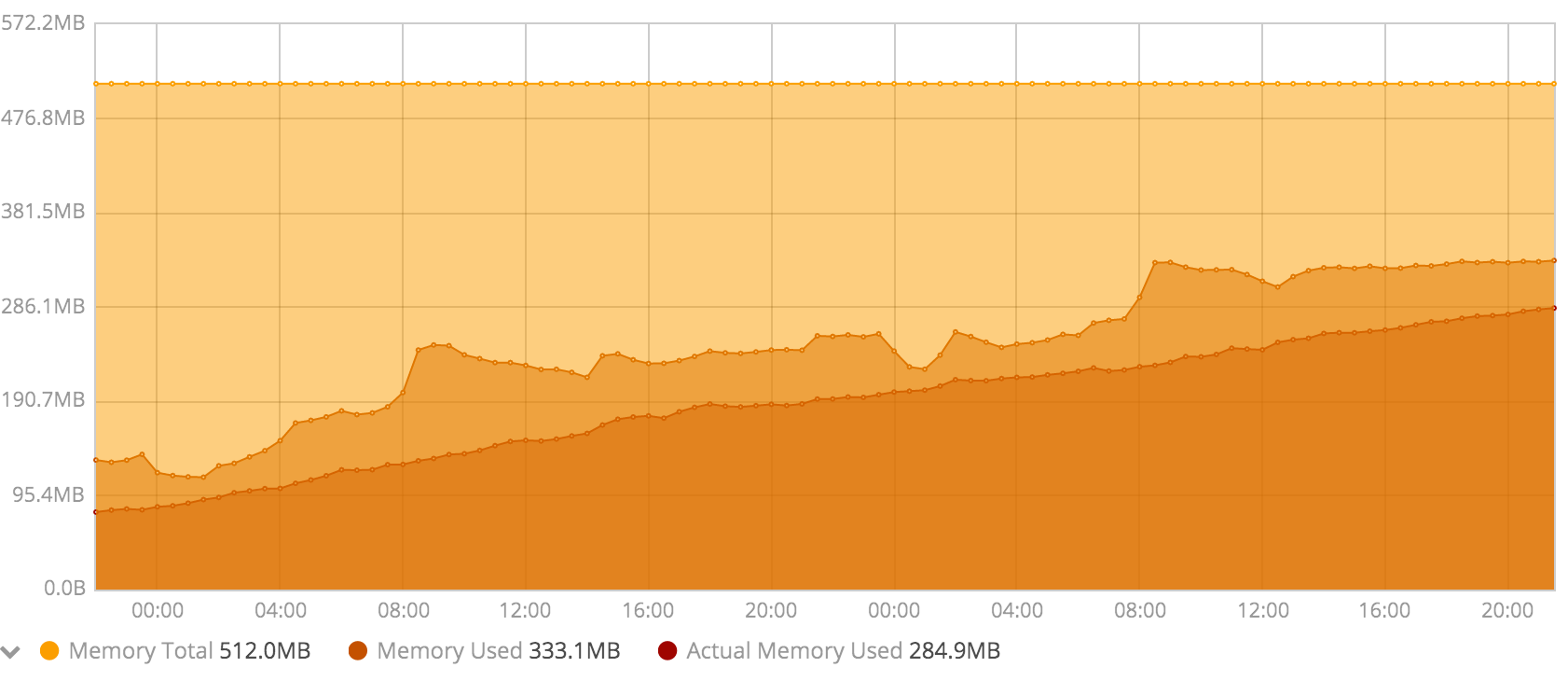
N’hésitez pas à me faire des retours sur la conso mémoire après quelques jours de tests !
pour info :
toujours avec une debian 32 bits, il a fallu que je purge $HOME/.duniter pour installer la nouvelle version.
Sauf erreur de ma part les deux liens “mettre à jour sa version” in fine pointe sur le même document.
J’ai utilisé la commande : curl -kL https://raw.githubusercontent.com/duniter/duniter/master/install.sh | bash
et en ne purgeant pas $HOME/.duniter je restais en v1.2.4 et j’avais des erreurs de "node-pre-gyp ERR! "
Voilà. Donc purge de “$HOME/.duniter” et : ~$ duniter -V
1.2.5
Merci
D’accord, en effet il peut y avoir des conflits avec cette méthode. Je conseille plutôt l’installation en téléchargeant simplement le fichier .deb et en l’installant sur son système.
@cgeek Bien, j’ai créé un petit cluster ES one node avec authentification. Si tu veux (ou si d’autres veulent) que je leur crée un compte pour tracer la consommation de leur instance duniter, c’est possible.
ça passe par l’utilisation d’un petit agent appelé metricbeat, je vous expliquerai la conf. En désactivant une sonde (process), on obtient des données peu intrusives. Je vous expliquerai tout ça si quelqu’un est intéressé.
en adaptant monpseudo et monpassword.
Puis pour le lancer systemctl start metricbeat
Pour ARM, il faut compiler soit-même. Je peux détailler si nécessaire, mais c’est un peu chiant à faire.
Comme je suis pas un monstre, je vous propose un build à moi ci-dessous :
par contre il n’est pas packagé debian du coup par de fichier service ni rien.
Une fois téléchargé et détargzé il suffit d’entrer dans le dossier metricbeat, adapter le fichier de configuration metricbeat.yml puis lancer
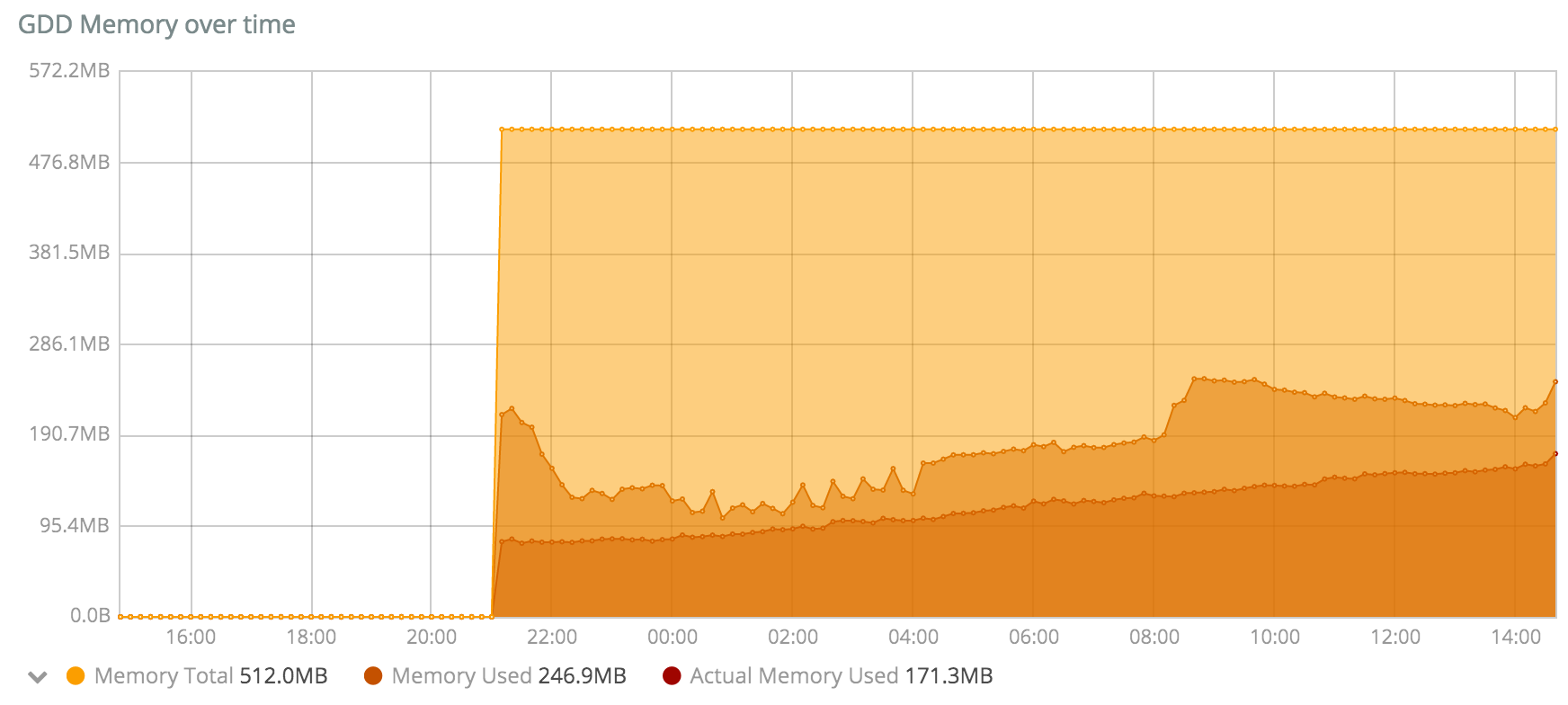
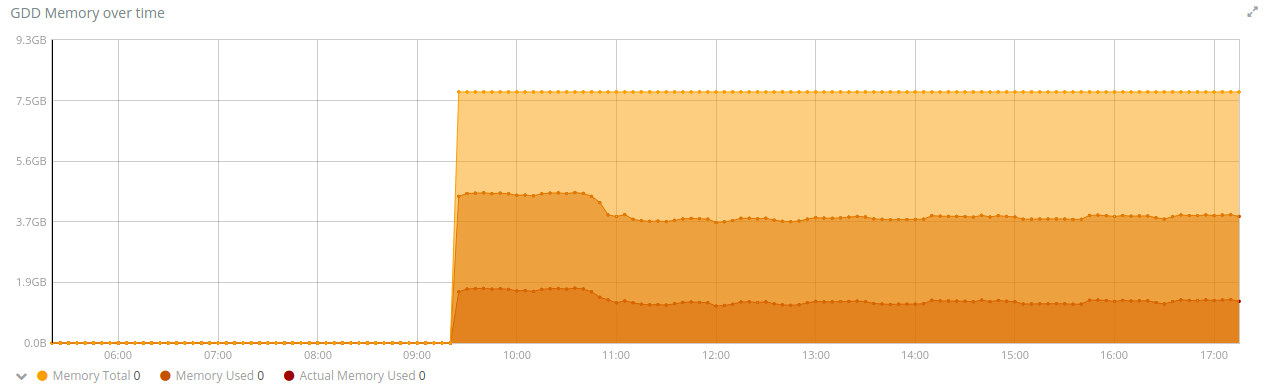
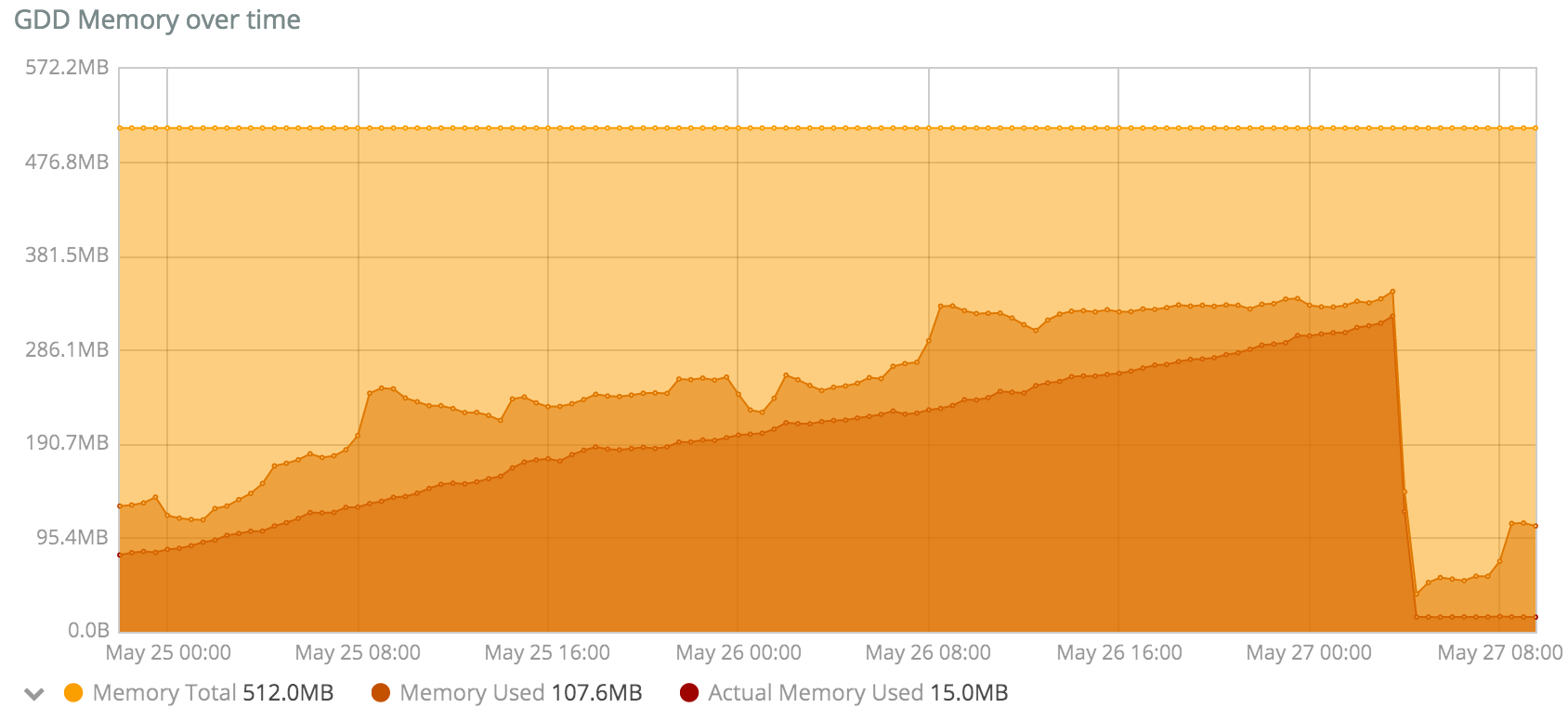
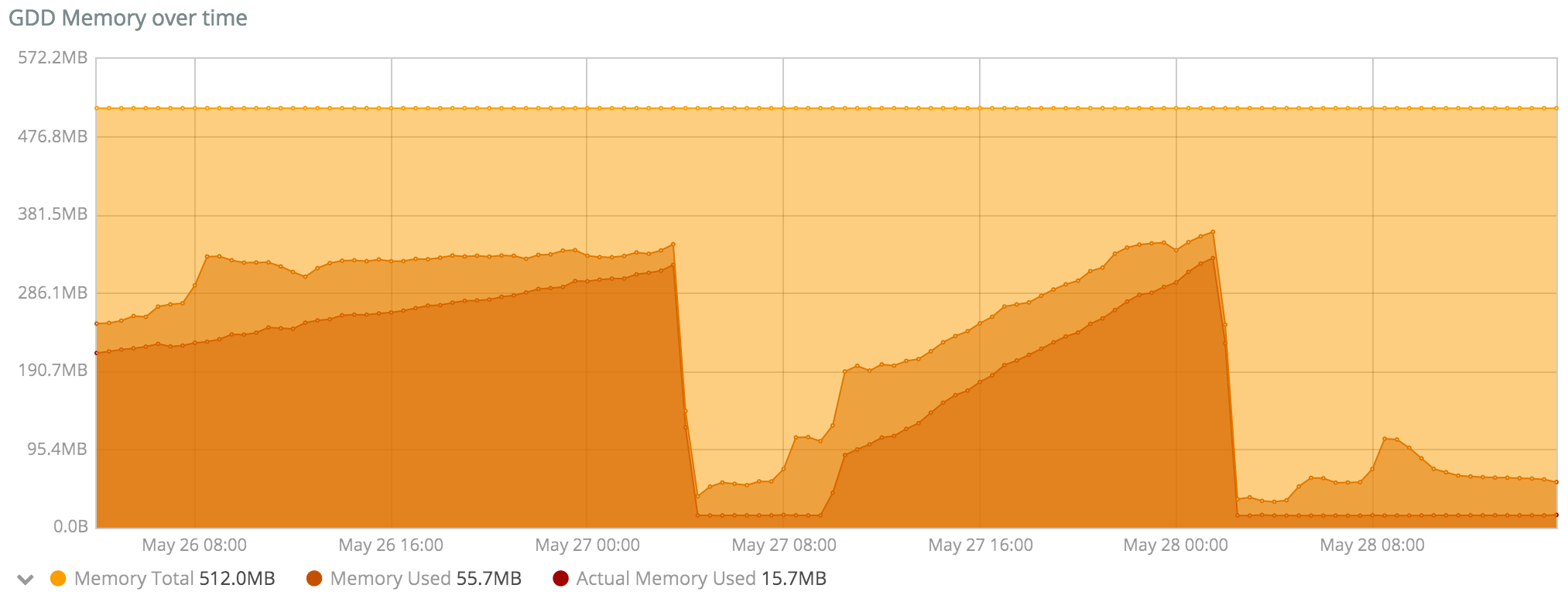
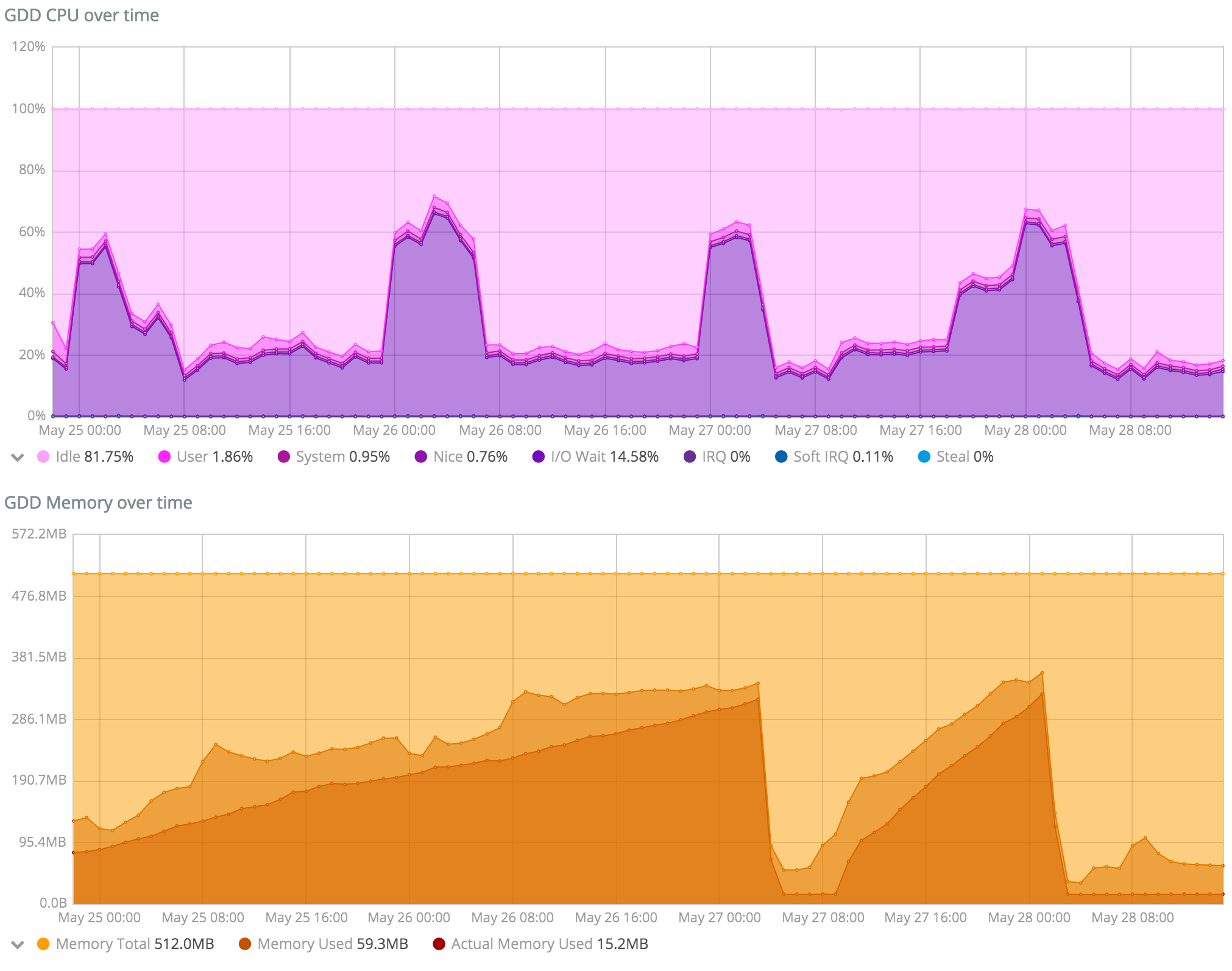
@florck, @d0p1 : il me semble que l’on devrait faire des tests autorisant 1 Go de RAM pour Duniter, pour ne pas s’arrêter sur des observations locales, mais essayer d’avoir une tendance longue.
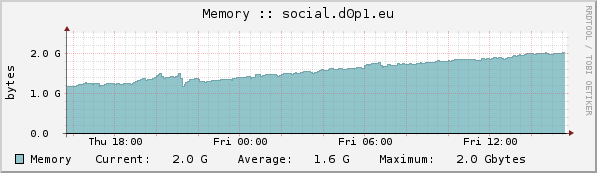
Notamment car quand j’observe mon serveur qui pourtant fait tourner 3 nœuds, donc avec des effets potentiellement 3 fois plus sensibles que sur un serveur avec 1 seul nœud, voici ce que j’observe :
Certes, la quantité de RAM consommée a augmenté continuellement de 1.2 Go le 25 mai 12h00 à 2.0 Go le 28 mai à 8h00 soit une augmentation de 800 Mo globale, soit une moyenne de 266 Mo d’augmentation par nœud en presque 3 jours, ce qui semble correspondre à l’augmentation constatée par florck. Par contre, c’est assez éloigné des +700 Mo en 12 heures de d0p1.
Mais je vais tenter de voir un peu plus loin avant de réellement conclure à la fuite. Je devrais vite avoir des résultats.
Dès ce soir en rentrant, je remonte la ram de ma machine. Si tu veux émettre des infos dans un fichier à intervalle régulier et qu’on les inclus dans Elastic après tu me diras.
Pas besoin de resynchroniser.