Suit au sujet Supression du UserID?, je souhaite relancer la discussion sur le format du UserID.
Actuellement dans Duniter v1 : app/lib/common-libs/constants.ts · e6505694b88207523745f3dec764faa7296d307a · nodes / typescript / duniter · GitLab
const USER_ID = "[A-Za-z0-9_-]{2,100}";
Actuellement dans Duniter v2 : primitives/duniter/src/lib.rs · 5c458eed2e83bcc3e8347b1bde0291ecd20deb61 · nodes / rust / Duniter v2S · GitLab (sur une branche dans laquelle j’ai ajouté des commentaires)
/// Rules for valid identity names are defined below
/// - Bound length to 64
/// - forbid trailing or double spaces
/// - accept only ascii alphanumeric or punctuation or space
pub fn validate_idty_name(idty_name: &[u8]) -> bool {
idty_name.len() >= 3
&& idty_name.len() <= 64 // length smaller than 64
&& idty_name[0] != 32 // does not start with space
&& idty_name[idty_name.len() - 1] != 32 // does not end with space
// all characters are alphanumeric or punctuation or space
&& idty_name
.iter()
.all(|c| c.is_ascii_alphanumeric() || c.is_ascii_punctuation() || *c == 32)
// disallow two consecutive spaces
&& idty_name
.iter()
.zip(idty_name.iter().skip(1))
.all(|(c1, c2)| *c1 != 32 || *c2 != 32)
}
Je donne mon avis ici, c’est bien sûr pour en discuter.
Longueur du pseudo :
Voici la répartition de la longueur du pseudo dans la Ğ1 actuellement :
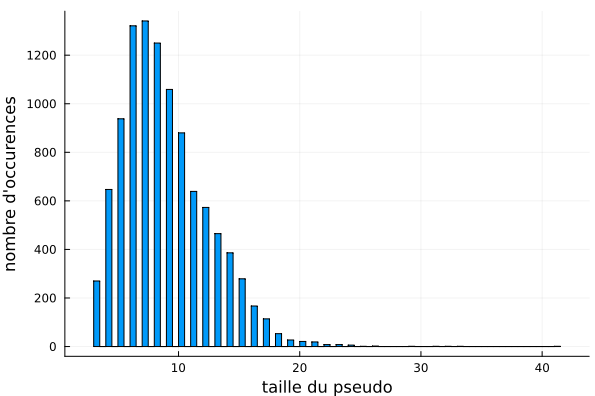
La grande majorité est en dessous de 20 caractères. Le plus long étant de taille 41 : BenoitDoutreleau-avec-un-chapeau-sur-le-i
Donc je propose de limiter à 42 (pourquoi pas).
Caractères autorisés
Voici le nombre d’occurrence des 64 caractères (tous utilisés) :
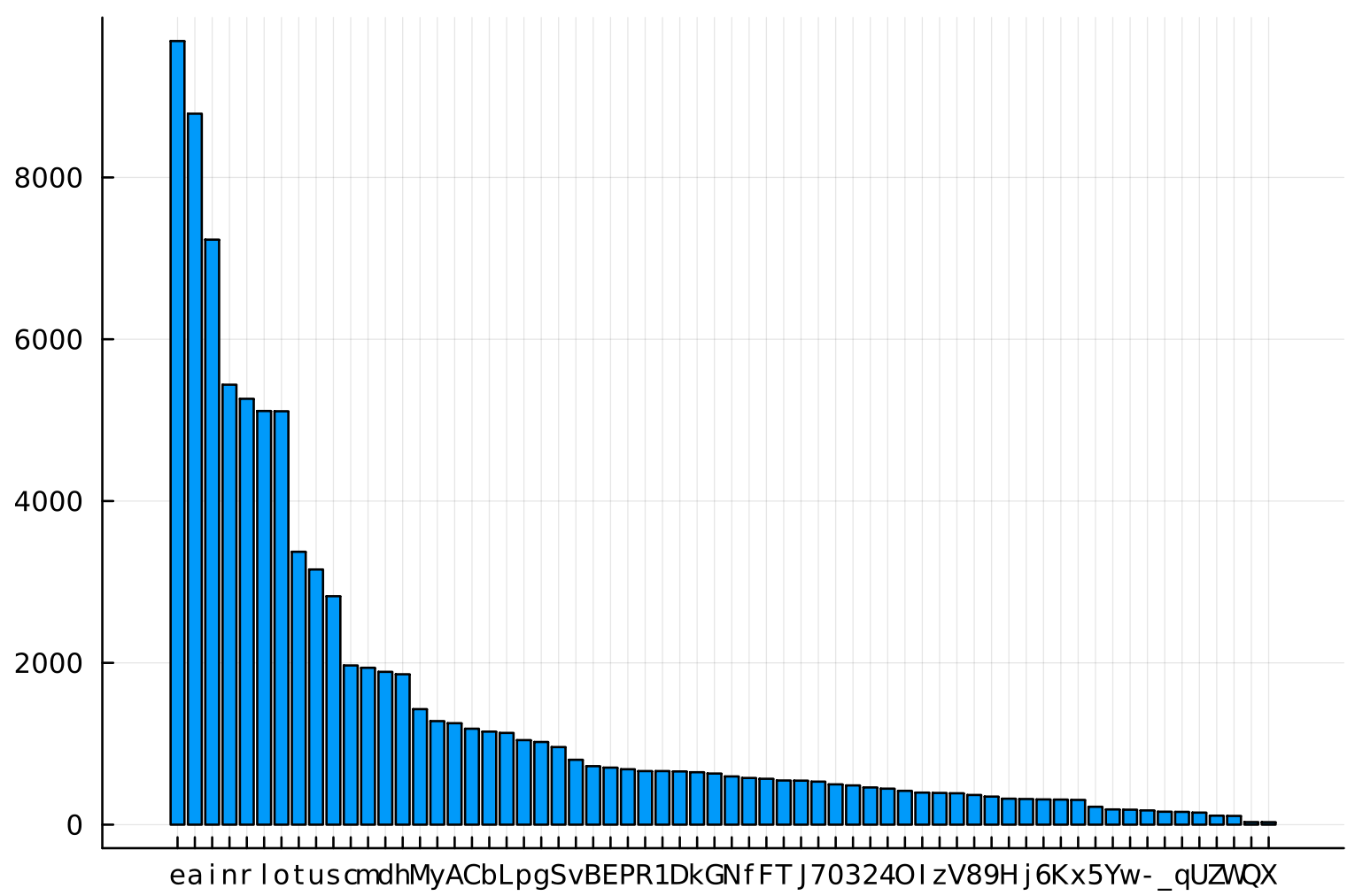
On peut éventuellement ajouter le point ou l’espace, mais je suis contre l’ajout d’autres ponctuations, et pour encadrer strictement leur usage. Il n’y a aucune occurrence de -- ou __ dans les pseudos actuels, les seuls pseudos qui commencent ou finissent par _ ou - sont :
_Wapetoooooooo__tbrt__vg_nicod_Marine_Sandrine-Charly-
Donc je suis pour :
- interdire deux caractères non alphanumériques successifs
- interdire des espaces au début ou à la fin
Normalisation
On commence à voir apparaître des problèmes avec des pseudos similaires, par ex le cas zazou / Zazou : RENOUYVELLER mon ADESIO - #32 par kalimheros - Outils - Support utilisateur - Forum Monnaie Libre
Je suis pour au minimum décourager ça dans les clients, et peut-être même l’interdire en dur pour éviter les attaques par typosquatting.
Pour implémenter ça, on pourrait avoir une version normalisée :
- lowercase
- sans ponctuation
et que cette version serve de base pour interdire la création d’un nouveau pseudo trop proche. Voici les exemples des 18 collisions triples actuellement (il y a 202 collisions doubles que je vous épargne) :
neoNeoNEOFredfredFREDliliLILILiliMichaelMicha_ElmichaelsabineSabineSABineMarie-bmariebMarieB
Ça fait 18 pseudos pour seulement 6 versions normalisées
neofredlilimichaelsabinemarieb
À débattre et méditer…