C’est à peu près ce que j’essaye d’exprimer oui, je vais le reformuler :
Je pars du principe (possiblement erroné, ça reste à confirmer) que, bien que toute écriture de donnée impacte le Storage (la BDD, en gros) et notamment le Merkle Root du bloc courant, toute écriture ne va pas forcément impacter le Merkle Root des blocs suivants.
Autrement dit : que quand un bloc est traité et accepté, il va construire son propre arbre de Merkle dont certaines branches vont “reprendre” tout ou partie des données de l’état au bloc précédent, mais que certaines autres branches seront purement et simplement écrasées.
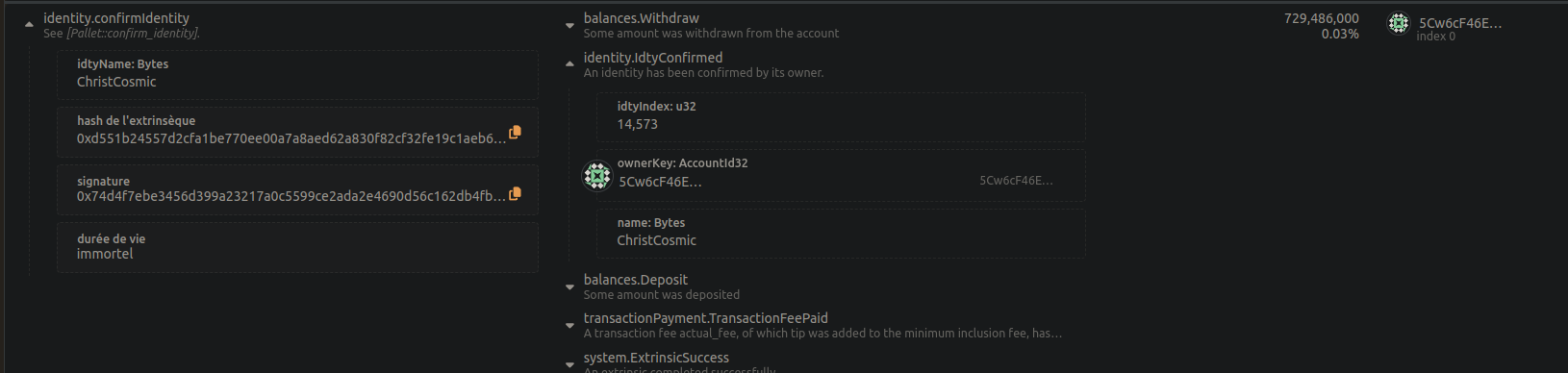
Je prétends que les évènements font partie de ces données systématiquement écrasées en intégralité par chaque bloc, et que donc par définition ce type de donnée n’impacte pas les blocs suivants et que forcément, à l’élagage du bloc, la donnée disparaît et ne vient jamais “gonfler” la BDD contrairement à des données “métier” (les comptes, les transactions, etc.).
Voilà pourquoi les évènements me semblent une très bonne façon d’indexer les hash de commentaires.
Et c’est également pour cela que je dis que stocker ces hash comme une donnée “métier” viendrait au contraire créer une donnée stockée par tout nœud (archive ou pas) et créerait même une donnée à stocker de façon historisée pour un nœud archive (en gros = stocker tous les évènements de tous les blocs).
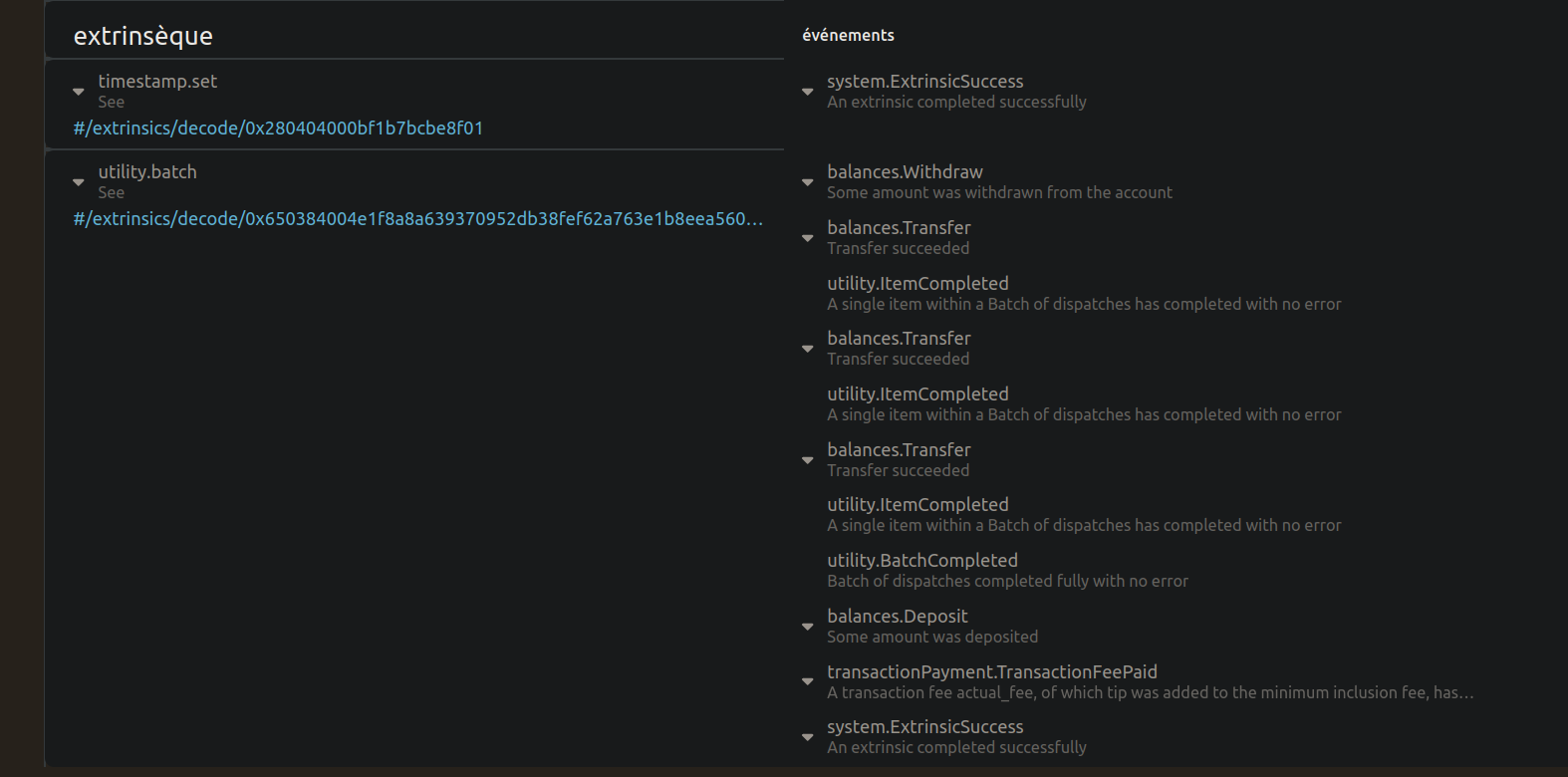
edit : tiens bah je suis allé vérifier sur la documentation Substrate, c’est bien comme ça que ça se passe :
This function places the event in the System pallet’s runtime storage for that block. At the beginning of a new block, the System pallet automatically removes all events that were stored from the previous block.