Attention : le post qui suit est un véritable pavé, prenez votre temps pour le lire. Merci de ne pas commenter sur un point sans avoir lu l’ensemble du document, vu que des problèmes apparaissent et sont résolus ensuite. Cependant si vous voyez un problème qui n’est pas résolu dans la suite du document, n’hésitez pas à en parler, et surtout n’hésitez pas à dire ce que vous en pensez. Merci de votre attention et bonne lecture.
Définition d’UTXO : sortie d’une transaction qui n’a pas encore été dépensée (Unspent Transaction Output)
L’ensemble des UTXOs est une structure de donnée qui va croitre au cours du temps, qui a besoin d’être stockée continuellement en mémoire par tous les noeuds, même ceux qui ne calculent pas.
Je propose une utilisation des Merkle-tree qui permettrait aux noeuds de ne pas garder en mémoire la base des UTXOs, et qui donnerais un nouveau rôle interessant aux noeuds mirroirs tout en diminuant leur cout.
Structure de stockage des UTXOs dans RFC5
Actuellement dans la RFC5 la liste des UTXO est triée par le hash de chaque UTXO et rangée dans un Merkle-tree.
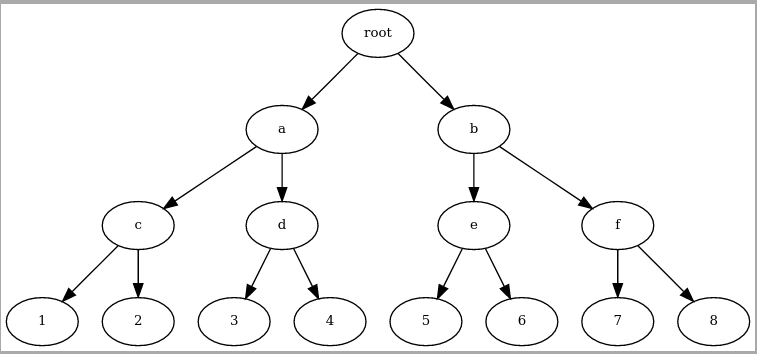
Ici 1, 2, 3, ... sont les UTXOs triées par leur hash, et a, b, c, ... sont des branches de Merkle. A chaque modification de l’ensemble des UTXOs, cet arbre est recalculé intégralement, et cet ensemble doit être stocké sur le disque et en mémoire.
Nouvelle structure proposée
La nouvelle structure insère les UTXOs dans leur ordre d’insertion, et pour 8 UTXOs le schema elle le même qu’avant sauf que les UTXOs sont numérotés par ordre d’insertion et ne sont pas triées par leur hash. La profondeur de l’arbre est fixée, et les nouvelles UTXO sont toujours ajoutées au plus profond de l’arbre. Il est donc construit comme ceçi :
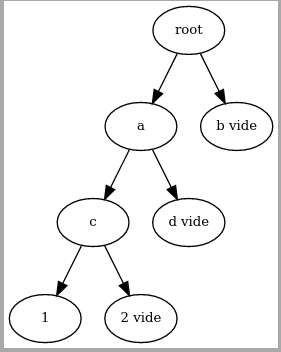
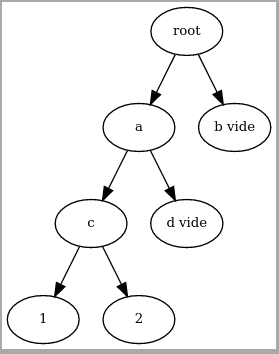
Les noeuds vides sont tous identiques et pourraient avoir un hash de
000000...pour être facilement identifiable
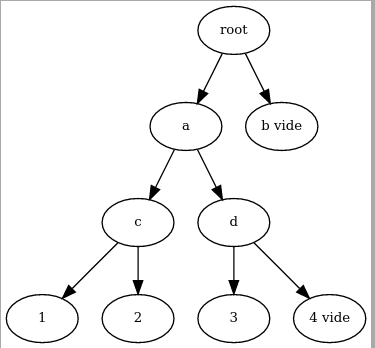
Et ainsi de suite. Quand cette arbre (appelé ici epoch) est entièrement rempli, on en commence un nouveau et on les attache ensemble :
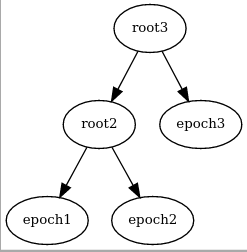
Quand un UTXO est consommée, on la remplace par un noeud vide.
L’arbre est recalculé à chaque changement et la nouvelle racine de Merkle représente l’intégralité de l’ensemble des UTXOs.
Fonctionnement
A partir de maintenant, les noeuds oublient complètement le contenu de l’arbre et ne stockent que :
- la liste des
rootXetepochX - le strict nécéssaire dans l’arbre en cours de remplissage (ici
epoch3) pour ajouter de nouvelles entrées. Dans le dernier graphe qui montrait l’insertion de3, il stockera alors3,c,ace qui lui permettra d’insérer4et de recalculer la racine, puis de recommencer.
Quand un utilisateur veut faire une transaction en utilisant des UTXOs, il va donner la preuve de Merkle que l’UXTO qu’il utilise est bien dans l’arbre jusqu’a un rootX ou epoch1. S’il utilise l’UTXO 4 maintenant insérée, il fournira alors comme preuve 3,c,b vide et le noeud aura bien la preuve que l’UXTO existe bien sans l’avoir stockée.
Si la transaction est valide, il va ajouter les nouvelles sorties à la fin de l’ensemble, et remplacer les UTXOs utilisées par une valeur vide. Grace à la preuve de Merkle donnée par l’utilisateur, il peut recalculer le nouvel arbre sans avoir besoin des autres informations. La preuve de Merkle permet donc de vérifier et de modifier l’arbre.
Vu que la transaction peut être réaliser à un moment t et qu’au moment de sa publication t + 1 l’epoch peut avoir augmenté, il fourni avec sa preuve jusqu’a quel epoch il remonte, et le noeud peux bien vérifier que cet epoch correspond. (cette information ne sera plus nécéssaire plus tard)
On peut rajouter que les preuves de chaque UTXO peuvent être regroupées en combinant les parties communes.
Mise à jour de la preuve des transactions suivante
Cette technique ne fonctionne pour l’instant qu’une seule fois. En effet dès que l’arbre est mis à jour avec les UTXOs supprimée et ajoutées, la preuve contenue dans une autre transaction n’est plus valide. La solution est qu’a chaque mise à jour de l’abre, on met à jour la preuve des autres transactions en corrigeant un hash qui vient d’être modifié. Si avec la transaction le hash A d’une branche deviens B, alors toute occurence de A dans les autres preuves stockées sont remplacées par B. Les nouvelles preuves sont alors valides avec la derniere version de l’arbre.
Stockage des preuves
Il est maintenant évidant que la preuve de la présence d’une UTXO est une information vitale, et que si elle disparait complètement cette UTXO est maintenant perdue et indépensable. Il faut donc qu’il y ai toujours des noeuds ou clients qui stocke cette information.
- Des noeuds d’achives peuvent stocker tout l’ensemble des UTXO, et les clients peuvent leur demander la preuve. C’est pratique mais demande de stocker tout l’ensemble ce qui ne sera pas faisable par tout le monde au vu de la taille qu’il pourra prendre, et du coup amène un problème de confiance que les noeuds voudront bien coopérer et donner ces preuves.
- L’utilisateur (ou un ensemble d’utilisateur qui se font confiance) peuvent faire tourner un noeud (mirroir ou calculant, peu importe) qui va stocker les preuves des UTXOs concernant ces utilisateurs. Cela permet au client de ne pas stocker les preuves, mais aussi de mettre à jour la preuve à chaque mise à jour de l’arbre.
Un client n’est pas connecté h24 au réseau, et ne peux donc pas assurer cette mise à jour. Un noeud peut le faire, mais une interruption de son service rendrait les preuves obsolètes. La solution pour les clients est d’avoir un ensemble assez grand de noeuds qui stockent leurs UTXOs pour que la probabilité qu’ils soient tous hors service au même moment soit faible. Un noeud qui serait relancé pourrait par la synchronisation pas à pas de la chaine mettre à jour les preuves. Tout ce qu’il faut, ce que tous les noeuds stockant les preuves n’arrêtent tous pas de fonctionner plus longtemps que la fenetre de fork, sinon ils ne pourront plus se synchroniser pas a pas et donc mettre à jour les preuves.
On note donc qu’un noeud ne va stocker uniquement l’ensemble de preuves de ses utilisateurs, ce qui est ridiculeusement petit comparé au stockage de l’ensemble des UTXOs. De ce fait les conditions matérielles pour faire tourner un noeud sont très petite, et n’importe qui avec une connection internet un (mini)ordinateur peut faire tourner un noeud qui stockera les preuves. Il peut aussi demander à des personnes de confiance et des services “altruistes” de stocker eux aussi les preuves pour qu’elle ne puissent pas être perdues.
Ce système impose alors une limite importante : un débit maximum d’informations insérées dans la blockchain pour que la très grande majorité des utilisateurs puissent faire tourner un noeud chez eux, avoir le temps télécharger les nouveaux blocs et d’appliquer les mise à jour de preuve. C’est cette limite que l’on devra définir “acceptable” qui définira le nombre maximum de transactions/seconde que Duniter sera capable de gérer. Cette limite pourrait bien évidement être un paramètre du système et être mis à jour au fur et à mesure que le débit augmente dans les foyers. Duniter sera alors largement plus scalable que les autres cryptomonnaies actuelles.
En résumé : impact sur l’écosystème
- Faire tourner un noeud (calculateur ou mirroir) est beaucoup moins gourmant en espace de stockage et en mémoire, et donc plus de personnes peuvent le faire, ce qui diminue encore plus le risque d’une preuve soit perdue
- Les noeuds peuvent stocker les preuves à la demande de clients et les mettre à jour. Ca pourrait être configurable pour qu’un noeud accepte de stocker les preuvent que de certains utilisateurs (stockage privé) ou avec un processus d’inscription (stockage public).
- Un noeud calculateur peut valider des transactions et écrire des blocs sans jamais stocker les UTXOs ni les preuves autres que celles de la piscine. Il peut servir de noeud de stockage de preuves s’il le souhaite, mais rien de l’y oblige.
- Les logiciels clients permettent de se connecter à différents noeuds de stockage (via un login ou une signature) et peuvent leur demander de stocker et de fournir plus tard les preuves.
- Rend beaucoup plus difficile de voir “les comptes” des autres utilisateurs et de tracer d’où vient l’argent, ce qui améliore l’anonymité et la fongibilité de la monnaie.
Voila voila. C’est une longue explication pour un fonctionnement qu’il me semble reste plutôt simple quand on a compris l’idée, et qui permettrait de rendre l’execution de noeuds abordable pour n’importe quelle machine avec un petit peu de stockage (les preuvent sont très légères et demandent 2log2(n) hashes par UTXO, avec n le nombre d’UXTO depuis le lancement de la blockchain. Cependant les parties communes des preuves peuvent être stockées une seule fois, réduisant encore drastiquement la taille des preuves.
Merci d’avoir eu le courage de lire cette explication, et j’attends avec impacience votre avis.

 Juste une couche par dessus.
Juste une couche par dessus.