Deux nouvelles requêtes et une nouvelle souscription dans GVA :
Subscription newBlock
Il est désormais possible de recevoir les nouveaux blocs par websocket via les souscriptions newBlock et newBlockMeta :

newBlockMeta donne accès uniquement aux méta-données du bloc mais est mieux optimisée ![]()
Donc désormais entre l’export json de la blockchain avec dex et la souscription GVA newBlock il est possible pour tout programme tiers d’accéder à l’intégralité de la blockchain et de mettre à jour ses données en temps réel, alors heureux ? ![]()
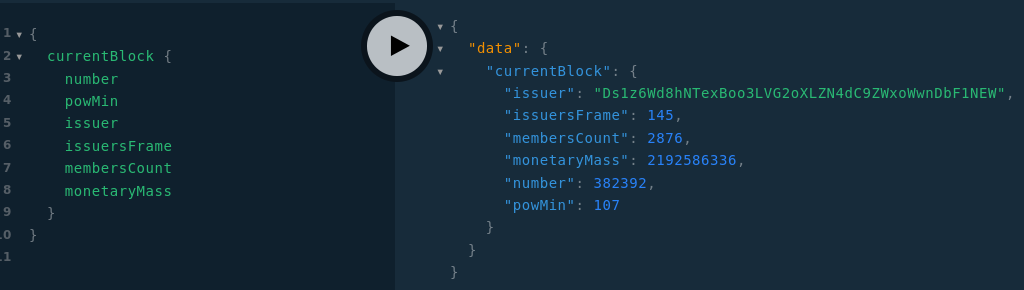
Query currentBlock
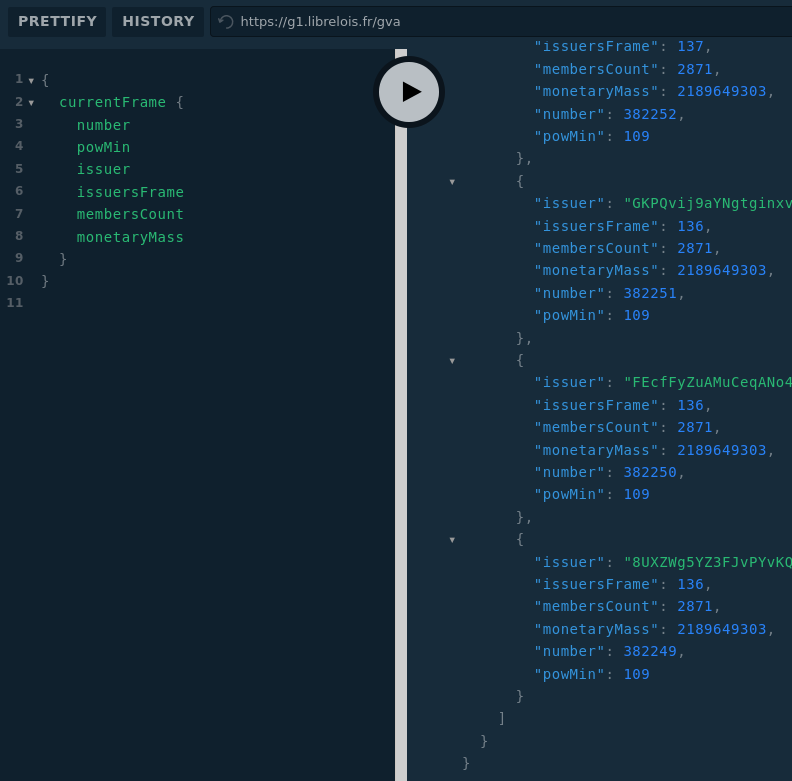
Query currentFrame
Fourni les issuersFrame dernier blocs. Permet de faire des stats sur la fenêtre courante (comme la diff. perso. de chaque membre forgeron par exemple).