A tu une doc qui explique à quoi doivent correspondre les champs distinct_on, order_by et where ?
Dans le cas de GVA je peux répondre : c’est élément le plus proche dans le sens demandé qui sera fourni.
A tu une doc qui explique à quoi doivent correspondre les champs distinct_on, order_by et where ?
Dans le cas de GVA je peux répondre : c’est élément le plus proche dans le sens demandé qui sera fourni.
En fait, ce n’est pas spécifique à leur api relay, mais plutôt sur la façon dont ils construisent les requêtes pour postgreSQL en fonction du schema graphQL demandé.
Ça peut donner une idée. Mais j’ai l’impression que c’est certainement overkill et ne correspond pas à Duniter…
Merci, mais c’est surtout des concepts très liés à SQL qui n’existe pas en stockage clé-valeur, donc ça me semble pas faisable et pas utile ![]()
Je ne trouve pas.
Normal le code de GVA a été mergé sur la branche dev depuis. Il est dans le dossier rust-libs/modules/gva ![]()
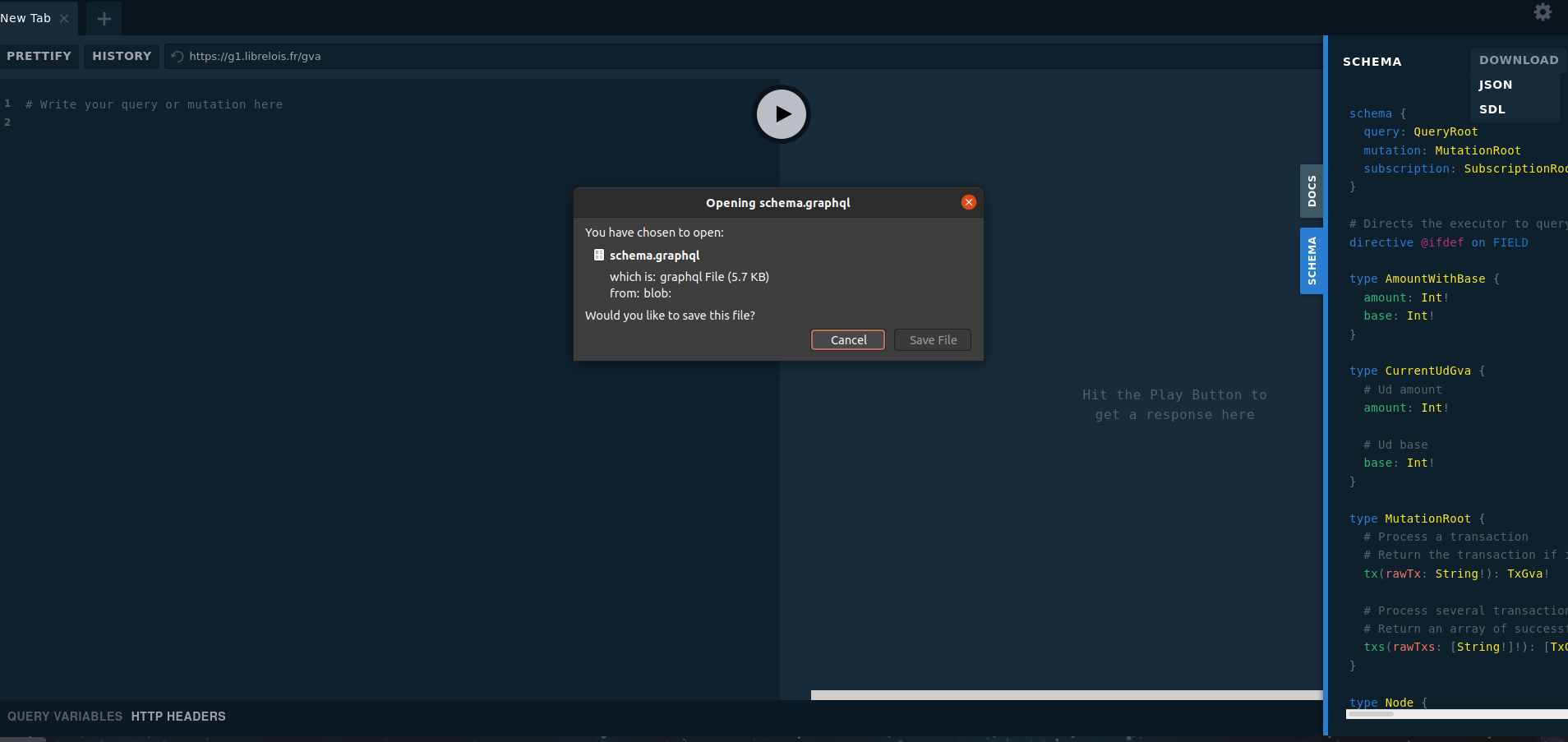
Mais le schéma te sera plus utile que le code. Sur le playground tu peux visualiser et télécharger le schéma complet* : https://g1.librelois.fr/gva
*schéma qui va encore beaucoup évoluer bien entendu
As-tu prévu de faire la pagination pour transactionsHistory aussi ? ![]()
C’est justement ce sur quoi je travaille ce week-end ![]()
Mais ça va demander de casser l’API, je vous expliquerai ![]()
Je n’avais pas réalisé ce travail de fonds pour l’historique des transactions, je présentais que ce serait plus compliqué.
J’avais stocké l’historique des transactions de manière naïve pour avoir un 1er prototype rapidement, sachant pertinemment que ça n’allait pas et qu’il me faudrait refondre ça plus tard.
Ma façon «naïve» de stocker l’historique des transactions posait 3 problèmes :
Dans GVA, concevoir la manière de structurer les données en base est de loin la partie la plus difficile, une fois que c’est fait le reste c’est des formalités à côté ![]()
Il y a plusieurs contraintes contradictoires à respecter, par ordre de priorité :
Il est impossible d’optimiser toutes ces contraintes aussi bien, il y a nécessairement des compromis à faire. Pour le moment, j’ai choisi de faire des compromis sur l’espace disque, car je considère que le non-respect de cette contrainte est moins gênant que le non-respect des autres.
Ce week-end, je me suis principalement attelé à refondre la manière de stocker l’historique des transactions pour respecter toutes ces contraintes, et ça m’a pris plus de temps que prévu.
Je n’ai donc pas encore commencé la pagination en tant que tel, mais j’ai réalisé tous les «préparatifs» la permettant. La pagination devrait donc être pliée en une soirée (demain soir j’espère).
Entre-temps j’ai ré-indexé et mis à jours mon nœud GVA avec la nouvelle structure, qui casse donc l’API existante.
Désormais il y a 2 requêtes séparées pour les transactions en blockchain et en mempool, cela permet de rendre plus lisible l’origine de la donnée, ça va dans le sens d’une demande de @vit.
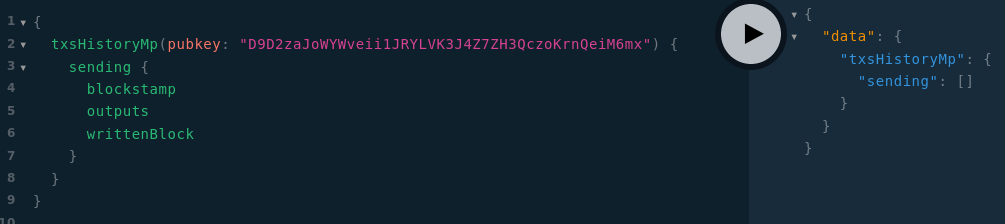
Pour récupérer les transactions en mempool :
Je ne prévois pas de pagination pour les transactions en mempool, car leur nombre est par nature très réduit.
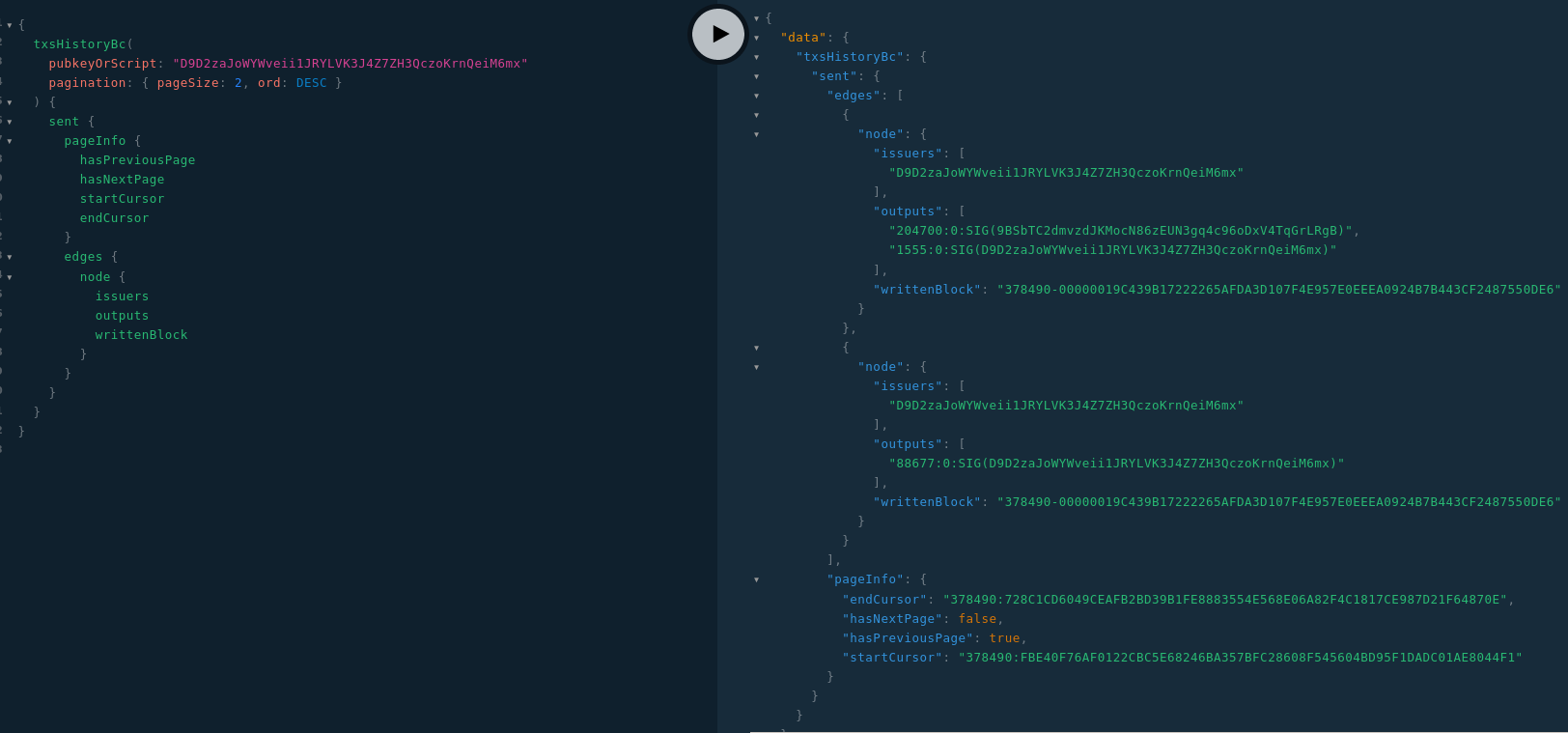
Pour récupérer les transactions en blockchain :
C’est cette requête qui va bientôt changer, car elle va être paginée.
Super !
J’étais justement en train de tester des requêtes d’historique avec GVA hier soir jusqu’à d’un coup j’ai un bug que je ne comprends pas pendant 1/2h (« catch mieux tes erreurs! »), puis je me suis rendu compte que j’étais sur ton nœud de dev et que tu avais changé la requête history 
Vous l’attendiez tous, voici la pagination de l’historique des transactions :
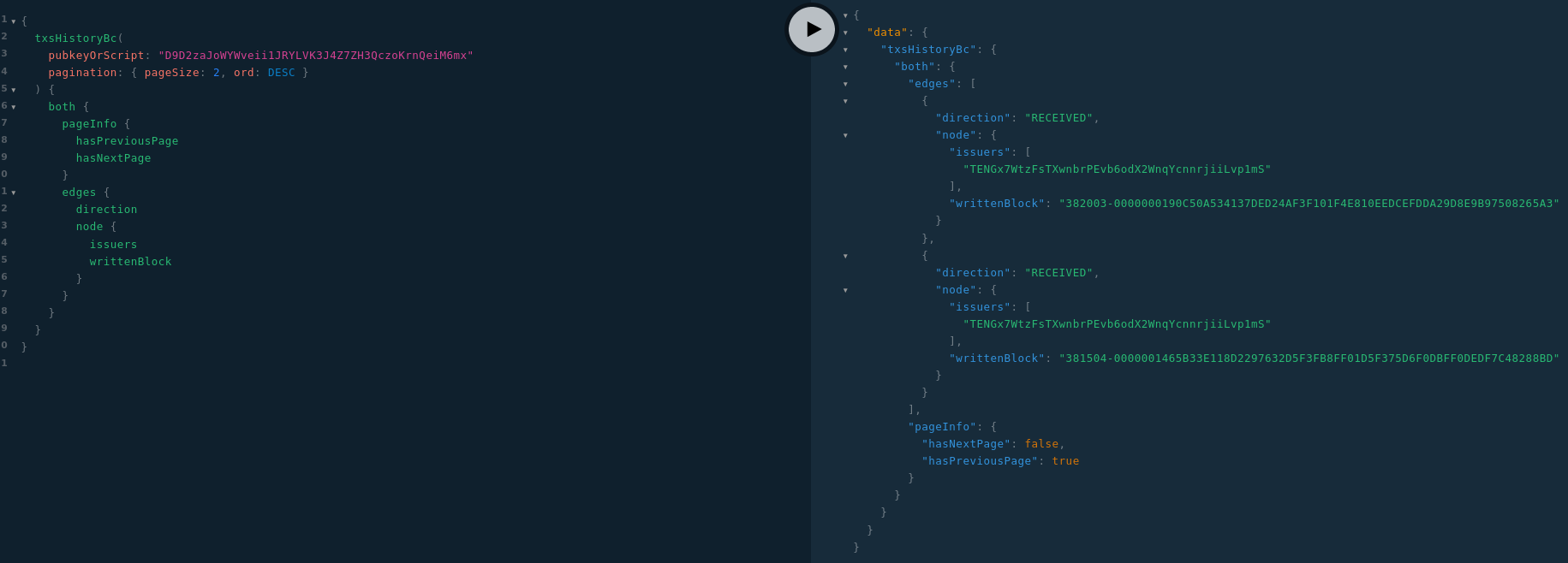
En outre, j’ai également rajouté le champ both permettant de paginer à la fois les tx émises et reçues dans une même liste :
Dans la pratique, les logiciels clients utiliseront le champ both pour présenter à l’utilisateur l’historique de son compte. Les champs sent et received ne servent que dans les cas d’usage où l’on ne souhaite QUE les transactions émises ou QUE les transactions reçues.
Le sens d’une transaction (SENT or RECEIVED) n’est pas dans nodes car ce n’est pas une donnée en base, c’est une méta-donnée qui n’a de sens que par rapport à un observateur (ici c’est par rapport à la valeur du champ pubkeyOrScript).
Aussi l’input pubkey deviens pubkeyOrScript car il est désormais possible de demander l’historique des transactions d’un compte complexe ![]()
EDIT : @poka je vois plein d’erreurs dans mes logs demandant l’historique de ta clé de l’ancienne façon ![]()
Et oui ce coup ci j’ai mis en doute plus tôt la version de GVA sur ton noeud qu’un problème dans mon code ^^
Super je vais voir tout ça!
Ca change complètement ma façon de parser l’historique.
Je vais d’abords le faire en python sur jaklis avant de mettre à jour Gecko.
Je te dirais si tout se passe bien.
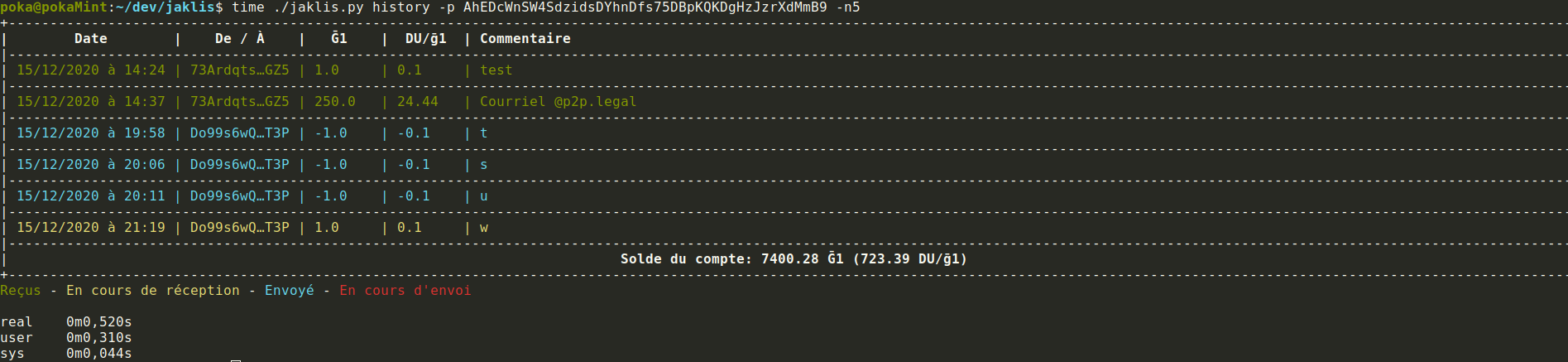
Voilà normalement l’historique paginé fonctionne avec jaklis:
Cependant j’ai du mal à voir de gain de temps en sélectionnant 1 ou 1000 transaction.
J’ai l’impression que charger tout l’historique d’un coup est plus long qu’avant, c’est le cas ?
Si tel est le cas ce n’est pas bien grave, dans un client lambda pas besoin de charger toute l’historique d’un coup tous les 4 matins.
Mais c’est peut être dû a mon implémentation en python.
Je vous dirais ce qu’il en est en Dart.
Normal 10, 100 ou 1000 éléments c’est du pareil au même car la majeure partie des traitements ne dépendent pas du nombre d’éléments, il te faut beaucoup plus d’éléments pour sentir une différence notable ![]()
Je pense que ce n’est qu’une impression. Il y a des milliers de facteurs qui influence le temps de réponse d’un serveur. Pour pouvoir comparer il faut faire la même requête beaucoup de fois et dans les mêmes conditions réseau et dans les mêmes conditions de charge serveur. (donc de pref sur un serveur local).
Il y a autre chose: la différence entre 1 ou 1000 transactions ne viens pas tant du serveur que du client. Si le client à une mauvaise connexion internet (ce qui peut être souvent le cas sur mobile en déplacement), alors là la différence peut être significative ![]()
C’est pour cela qu’une pagination avec des pages de petite taille me semble indispensable sur mobile ![]()
Oui tu as raison, on sens bien la différence entre 1000 et 10 transactions en fait:
Pour 1000:
$ while true; do time ./jaklis.py history -n1000 > /dev/null; sleep 0.1; done
real 0m2,745s
real 0m2,665s
real 0m2,753s
real 0m4,911s
real 0m2,186s
real 0m2,172s
real 0m2,116s
real 0m2,290s
real 0m2,058s
real 0m2,925s
real 0m2,760s
real 0m2,428s
Pour 10:
$ while true; do time ./jaklis.py history -n10 > /dev/null; sleep 0.1; done
real 0m0,557s
real 0m0,508s
real 0m0,508s
real 0m0,504s
real 0m0,498s
real 0m0,496s
real 0m0,500s
real 0m0,483s
real 0m0,493s
real 0m0,493s
real 0m0,501s
5x plus rapide pour un rapport de 1 à 100 !
Bon il me restera à gérer les pages suivantes/précédentes, mais je compte pas le faire en python.
Deux nouvelles requêtes et une nouvelle souscription dans GVA :
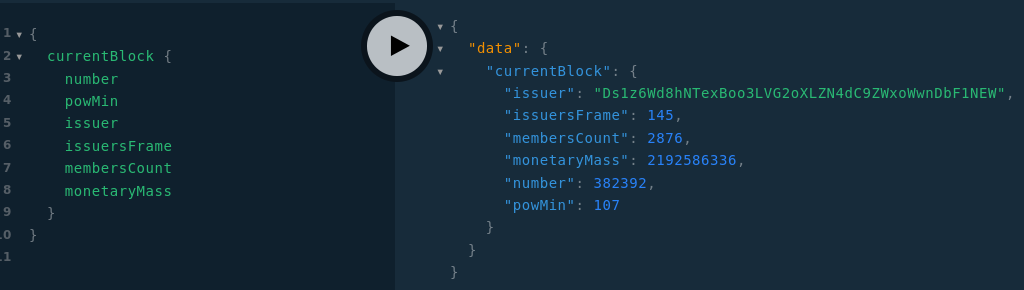
Il est désormais possible de recevoir les nouveaux blocs par websocket via les souscriptions newBlock et newBlockMeta :
newBlockMeta donne accès uniquement aux méta-données du bloc mais est mieux optimisée ![]()
Donc désormais entre l’export json de la blockchain avec dex et la souscription GVA newBlock il est possible pour tout programme tiers d’accéder à l’intégralité de la blockchain et de mettre à jour ses données en temps réel, alors heureux ? ![]()
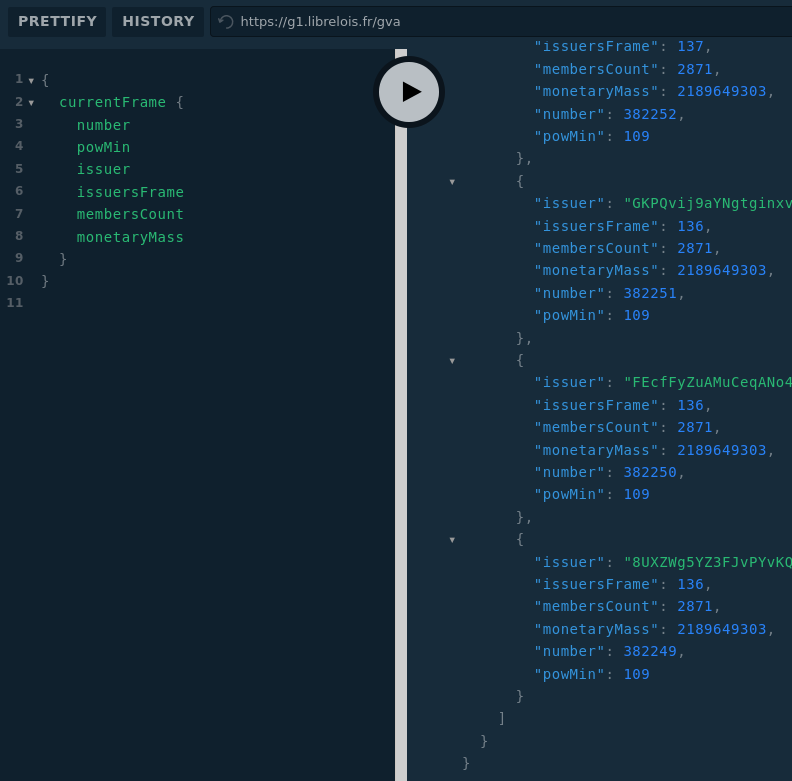
Fourni les issuersFrame dernier blocs. Permet de faire des stats sur la fenêtre courante (comme la diff. perso. de chaque membre forgeron par exemple).
Il commence à y avoir pas mal de nouvelles requêtes et de souscriptions. Est-il possible d’avoir un document similaire à celui de BMA qui documente GVA. Je sais qu’il est possible de récupérer le schéma GVA directement via une requête. Mais documenter les choses c’est encore mieux et plus agréable à lire.
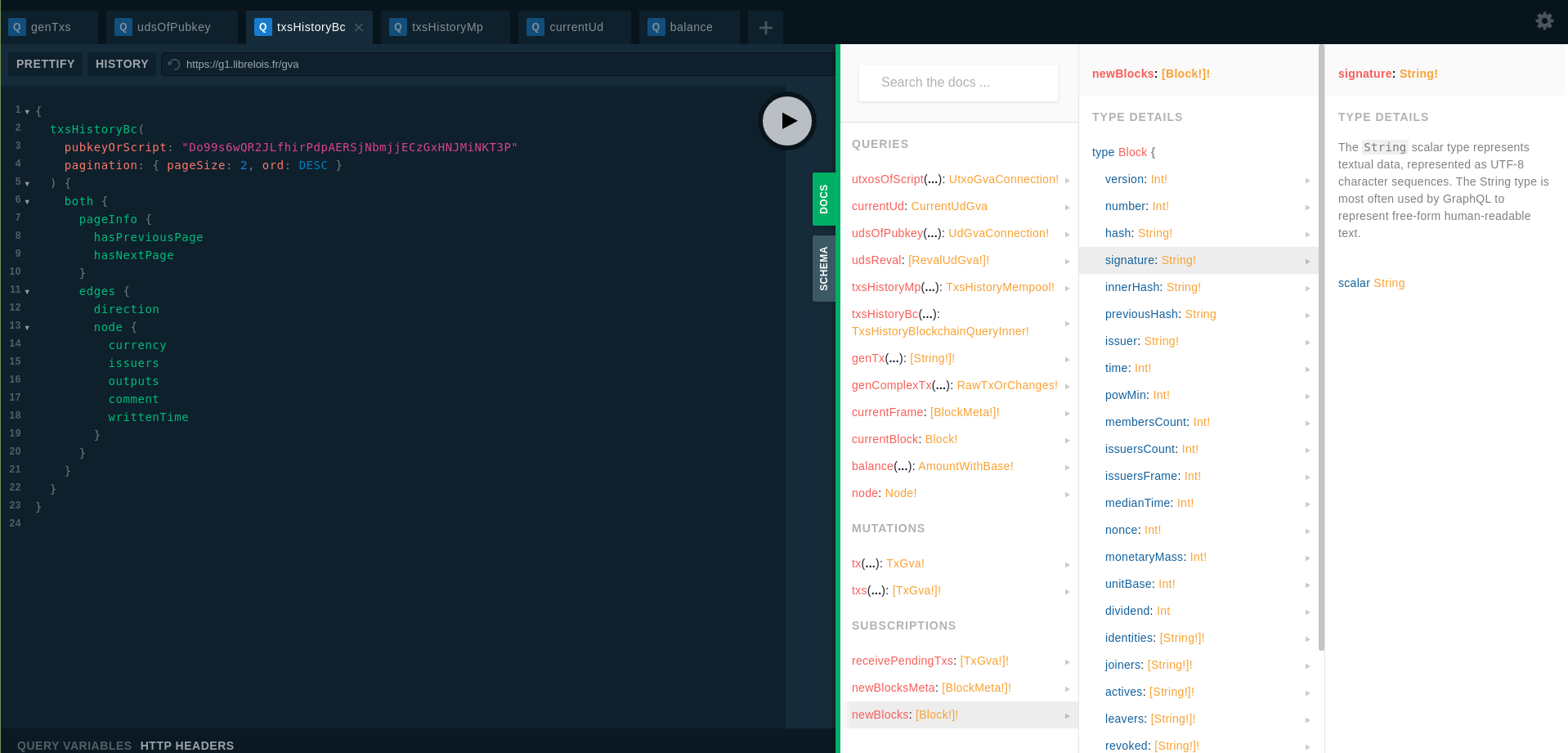
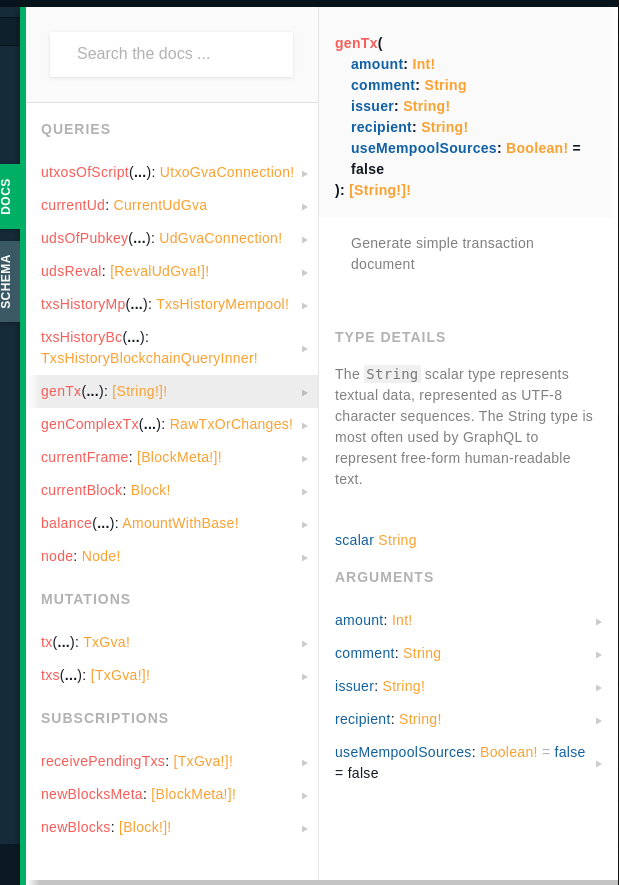
En fait la doc existe déjà elle est généré automatiquement et accessible via chaque noeud GVA:
![]()
Je la trouve très pratique, c’est grâce à ça que j’implémente GVA sans soucis.
Et au moins on est sûr qu’elle est à jours, à chaque nouvelle version de GVA, tu refresh la page et la doc est strictement à jour!
Edit:
Il y a même une zone de description custom qui je suppose est écrite par Elois, ici “Generate simple transaction document”. Je suppose que ces descriptions pourraient être plus explicites à l’avenir pour expliqué plus en détail à quoi peut servir la requête si ce n’est pas assez clair.
Perso je trouve les noms de queries et mutations choisis par Elois déjà assez clair intuitivement, mais si on veut chipoter, le top du top serait qu’en cliquant sur une queries dans la doc, cela pré-remplisse un exemple exhaustif dans graphql playground pour l’exécuter en un clique. Mais là c’est plus de l’ordre du luxe, je sais pas si graphql playground permet ça.
Je sais que d’autres outils permettent de le faire, comme ici.