Du nouveau sur GVA, le fruit des dev de la semaine :
1. Pagination
La pagination était en place sur utxosOfScript seulement mais elle était factice, le serveur récupérait toutes les UTXO en base puis renvoyait la page demandée.
J’ai réalisé un gros travail de fond pour mettre en place un vrai système de pagination qui s’applique au plus près de la base de donnée. C’est à dire que désormais seule la page demandée sera récupérée en base, ce qui devrait permettre de réduire les traitements à chaque requête et donc de les accélérer.
Cela à également nécessité un changement dans la manière de stocker les données, une réindexation est donc indispensable !
J’ai aussi modifié les inputs gérant la pagination, c’est désormais un «objet» Pagination qu’il faut renseigner avec les 3 champs suivant :
cursor: position de départ (ou de fin si ordre décroissant)ord: ordre croissant (ASC) ou décroissant (DESC). Par défaut l’ordre est ASC. On parle aussi d’ordre normal pour ASC et d’ordre inverse pour DESC.pageSize: ai-je vraiment besoin d’expliquer ce champ ?
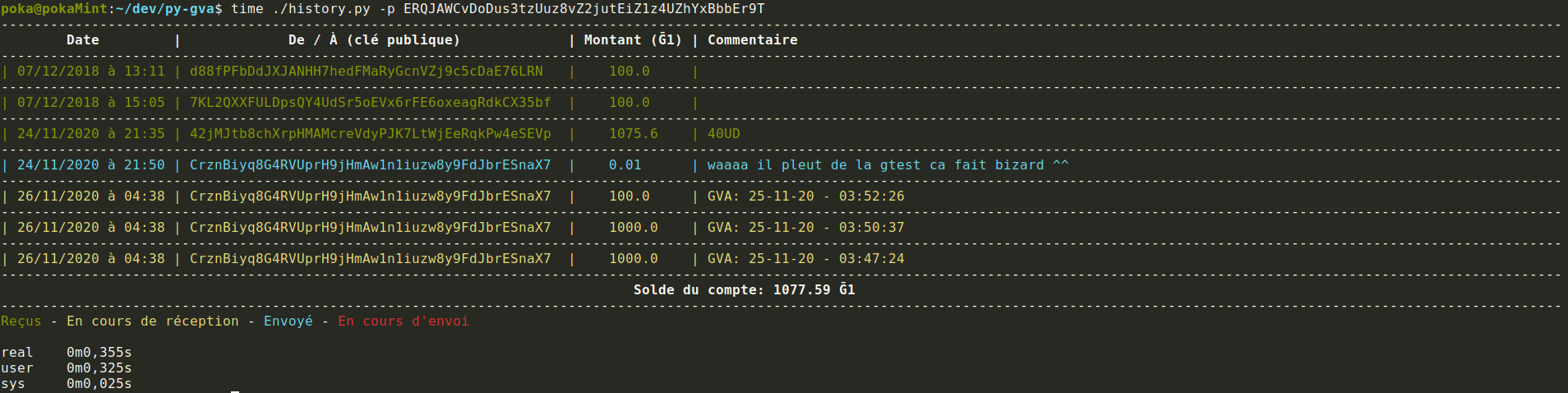
2. Historique des DU créé
Suite à une demande de @vit j’ai implémenté une requête fournissant l’historique de tous les DU créé (consommés ou non).
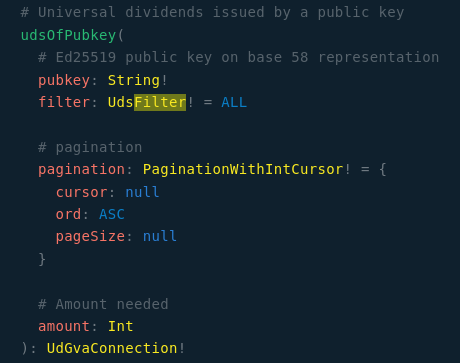
Dans le schéma c’est la requête existante udsOfPubkey qui fourni désormais au choix tous les DU ou les DU non-consommés via le paramètre d’entrée filter de type UdsFilter :
enum UdsFilter {
ALL
UNSPENT
}
Si filter n’est pas renseigné il vaut ALL par défaut, c’est indiqué dans le schéma :
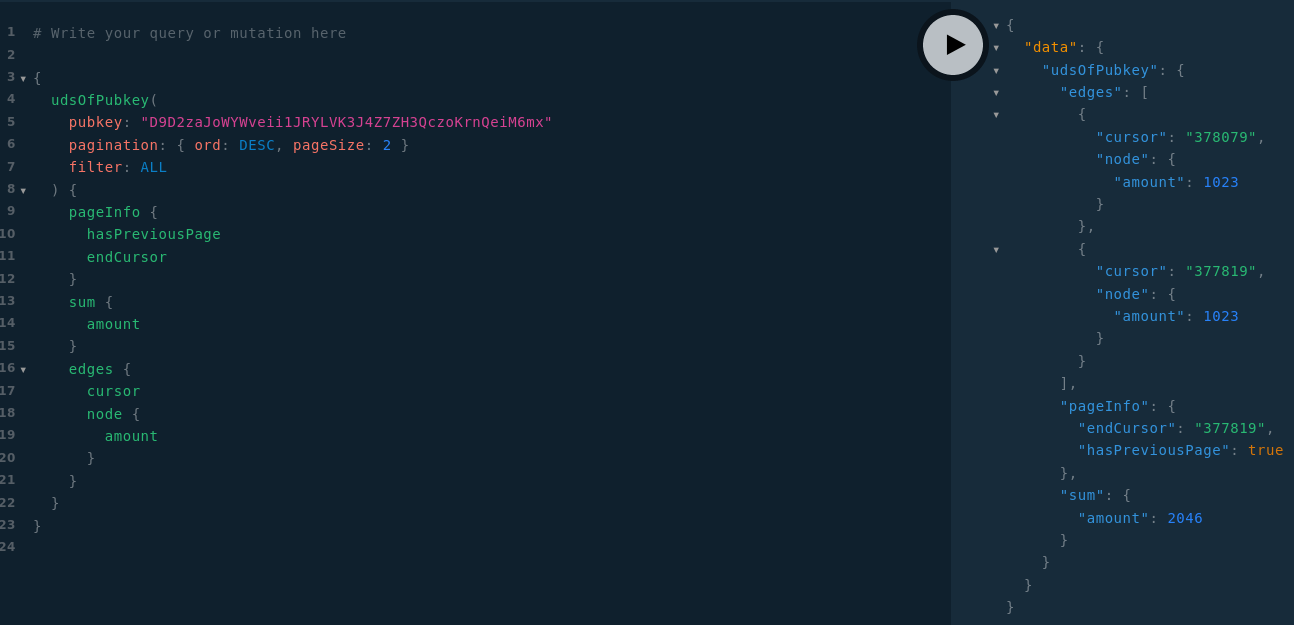
Exemple : récupérer les 2 derniers DU créé
Évidemment j’ai choisi 2 pour l’exemple mais il suffit d’augmenter pageSize pour avoir des pages plus grande.
Comment passer à la page suivante ?
Si vous parcourez les données dans l’ordre décroissant, il faut récupérer la valeur du champ endCursor et la placée dans le champ cursor en input 
Si en revanche vous parcourez les données dans l’ordre croissant, c’est le champ startCursor qu’il faut utiliser.
Enfin le champ hasPreviousPage vous indique s’il y a une page précédente (donc une page suivante pour vous si vous parcourez les données dans l’ordre DESC). Et si vous parcourez les données dans l’ordre ASC il faut utiliser hasNextPage à la place).
3. Récupérer des sources jusqu’à un certain montant
Les requêtes udsOfPubkey et utxosOfScript acceptent désormais un paramètre d’entrée amount, si ce paramètre est renseigné la requête va cesser son parcours de la DB dès que le montant demandé est atteint ou dépassé.
Cela permet à ceux qui le souhaitent de pouvoir continuer à sélectionner les sources eux-mêmes.
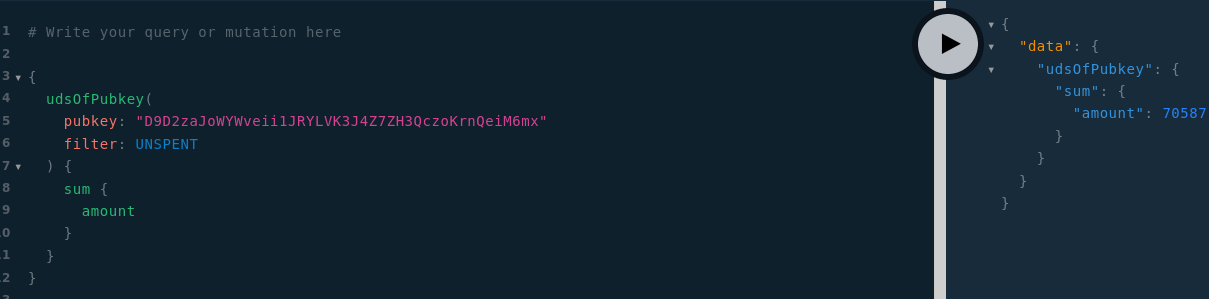
4. Champ sum sur les requetes udsOfPubkey et utxosOfScript
Les requetes udsOfPubkey et utxosOfScript exposent désormais un champ sum indiquant la somme des montants des sources de la page (avec gestion des bases).
Cela permet par exemple de calculer la somme de tout les DU d’un compte (attention requête lourde si le compte à beaucoup de DU). Je sais par exemple que tous les DU que j’ai créé représentent 13741,69 Ğ1 :
Et que mes DU non-consommés représentent 705,87 Ğ1 :
Est-ce que c’est clair au niveau du système de pagination ? Vous avez des questions ?