@tuxmain a implémenté la requête permettant d’obtenir les fiches de peer et les HEADs, j’aurais préféré qu’un autre contributeur y arrive, mais @HugoTrentesaux et @vit n’ont malheureusement pas poursuivi l’exercice après l’atelier ![]()
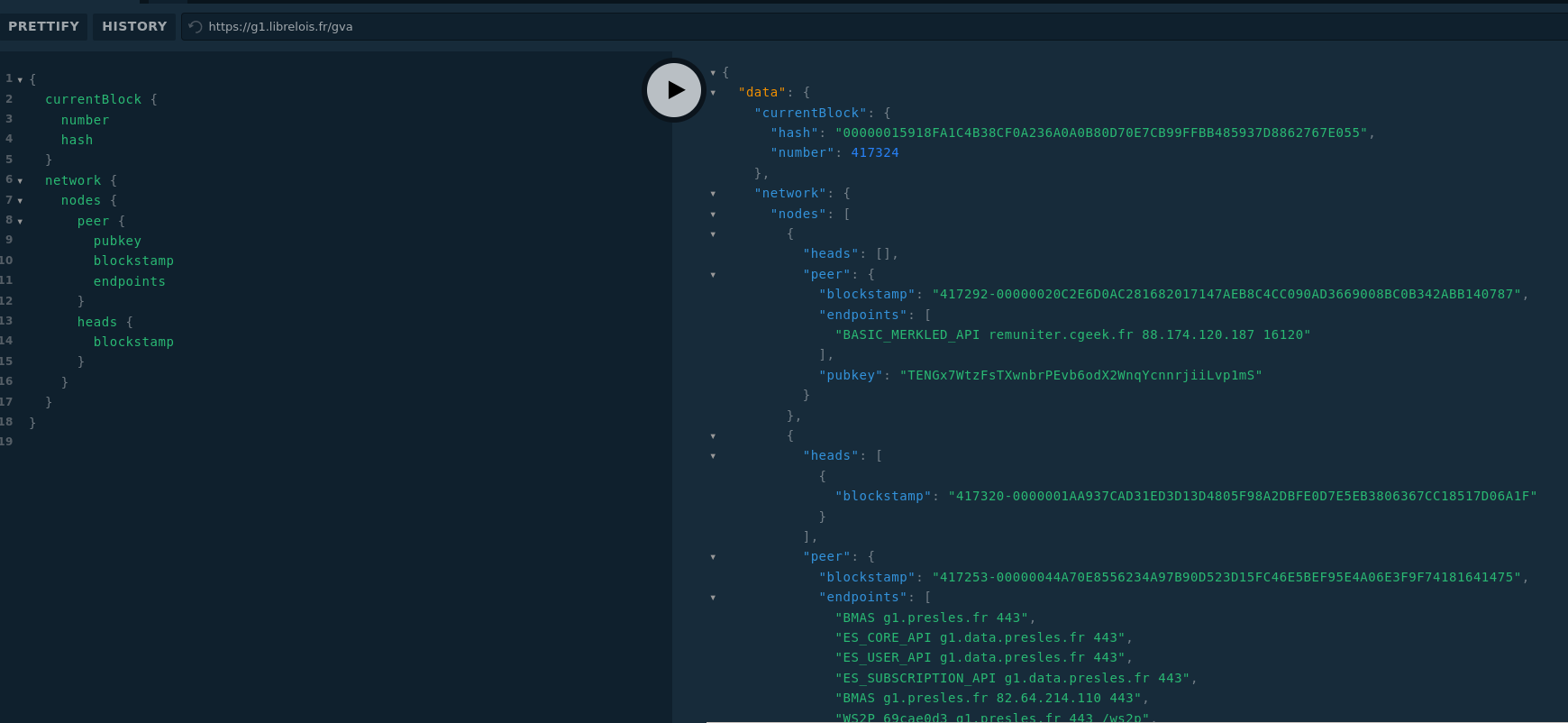
C’est possible dans l’API de graphql de wotwizard
Bravo @tuxmain , gestion des fork au démarrage de Gecko imminente.
Pendant le hackathon, @1000i100 à passé une journée en peer programming avec moi pour implémenter la requête GVA « endpoints », cette requête vous retourne tout les endpoints connus pour l’API demandée :
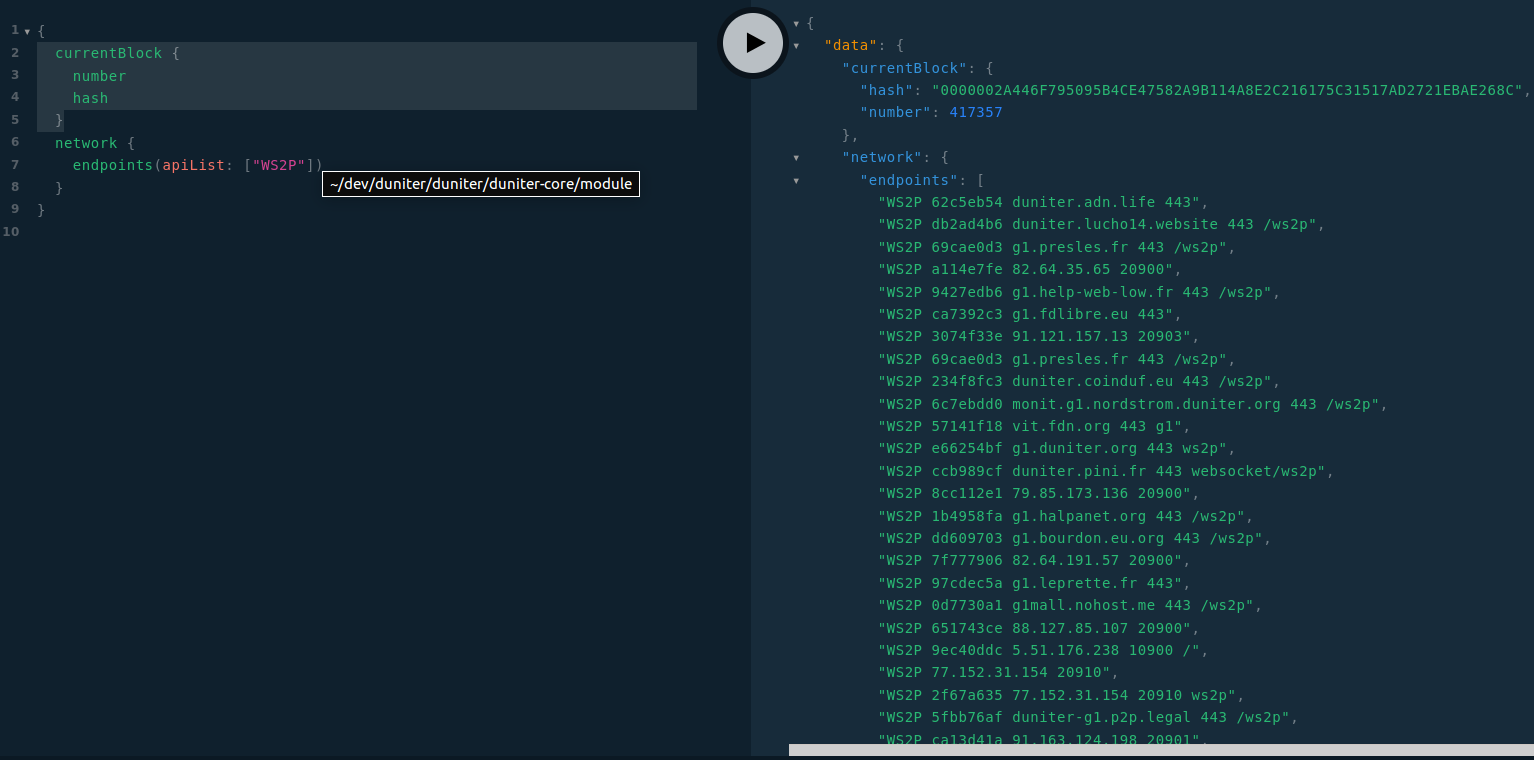
Et du coup, je vois que tu as fait le changement pour mettre endpoints dans network.
aurais-tu le commit de ce changement que je vois comment tu as fait ?
Merci !
network_db.peers_old().iter(.., |it| {
Je vois à plusieurs endroits peers_old. Pourquoi old ?
Pour différencier de la future collection peers qui stockera le nouveau format de fiches de peer, notamment sans les peer partagés et sans les champs obsolètes.
Ca s’annonce bien tout ca ! ![]()
Ajout du champ receivedTime pour les transactions en mempool: il s’agit de la date et heure de première réception du document transaction par le nœud Duniter.
À la demande de @kimamila, cette information à également été ajoutée dans BMA, dans le champ time, ce champ valait null pour les transactions en attente, il contiendra désormais la date de réception du document 
À noter que le champ time contenait déjà la date d’écriture en blockchain pour les transactions écrites en blockchain.
Il semblerait que le code de Cesium n’est même pas besoin d’être modifié, car la date et heure de la transaction est le résultat de l’expression time || blockstampTime
Quant à GVA, il y a déjà depuis plusieurs mois le champ writtenTime pour les transactions en blockchain 
Aujourd’hui j’ai réalisé quelques tests de ce nouveau champ receivedTime et il semble fonctionner. J’ai également testé la bonne valorisation du champ time dans BMA pour les transactions en attentes, là aussi ça semble bien fonctionner 
Énorme !
Ça veut dire qu’on va pouvoir s’appuyer sur des blocs plus ancien pour émettre les TX, et limiter au maximum les risques de pertes de TX a cause de fork.
La prochaine version de Cesium va être sympa (commentaires chiffrés, scan réseau en tâche de fond, TX lié au bloc HEAD - 100) !
Faut juste que je trouve du temps pour la finir mais notre bébé va mieux (après des soucis les premiers mois). Je vais pouvoir sortir la tête de l’eau.
Je suppose que c’est une typo : written time
Une requête importante pour plein d’outils est les certifications (liste des certifications d’une identité et toutes les certifications).
@elois penses-tu que je peux m’en occuper ? Il me semble que tous les ingrédients sont là. 
Je pense ajouter des champs issued et received à GvaIdtyDbV1. (ou issued_certs ou certs_issued, j’hésite toujours entre l’avantage du préfixage et le respect de la grammaire anglaise)
Oui tu as les compétences pour. Par contre il faut qu’on prenne bien le temps de réfléchir à quel schéma de DB, et pour cela il faut partir du besoin. Je te propose de commencer par écrire les requêtes graphql que le client doit pouvoir faire, en précisant bien quelles données il doit pouvoir obtenir.
C’est seulement à partir d’une description non-ambigue du besoin qu’on pourra réfléchir à un schéma de DB optimisé pour ce besoin ![]()
Des outils comme la wotmap et la worldwotmap ont besoin de la liste de toutes les certifications actives :
query {
certifications() {
issuer # pubkey
receiver # pubkey
}
}
Des clients comme Cesium ont besoin des certifications d’une identité, avec leur numéro de bloc d’écriture, et date d’écriture ou date d’expiration :
query {
certificationsOfIdty(pubkey: String) {
issued {
recipient # pubkey
block_number # ou blockstamp ?
written_time # ou expire_time, ou les deux
}
received {
issuer # pubkey
block_number # ou blockstamp ?
written_time # ou expire_time, ou les deux
}
}
}
Les différents moyens que je vois :
- ajouter des champs
issuedetreceiveddansGvaIdtyDbV1, contenant la liste des certifications. Il faudrait juste les ajouter dans la requêteidtyet créer une requête paginéeidties. - pareil, mais en stockant non pas les certifications, mais leur hash. Les certifications seraient stockées dans une autre db, par hash.
Comme il faut pouvoir retrouver les certifications d’une identité, je ne vois pas comment faire autrement sans refaire un index par clé publique, et dans ce cas-là on peut utiliser gva_identities.
Avoir les certifications avec les identités rend aussi les choses plus simples pour wotmap et worldwotmap.
Ok donc on doit pouvoir :
- Parcourir toutes les certifications
- Parcourir toutes les certifications émises par une clé publique donnée
- Parcourir toutes les certifications reçues par une clé publique donnée
- Pour chaque certification, avoir comme information: émétteur, receveur, numéro de bloc de création, numéro de bloc d’écriture (toutes dates pouvant être récupérées où calculer à partir de ces données).
De plus, il faut penser aux besoins d’indexation et de revert. On doit donc pouvoir mettre à jour une certification (renouvellement) sans en créer une nouvelle. On doit également pouvoir supprimer une certification lorsqu’elle expire (car cet event n’est pas déclaré dans les blocs).
En vue de ces besoins, voici comment je modifierai la DB :
- Ajouter une collection
certificationsdont la clé estissuer || targetet la valeur une struct du genre:
GvaCertDbV1 {
created_on: BlockNumber
written_block: BlockNumber
}
- Ajouter une collection
certs_by_expireavec comme cléU64BEet comme valeurVec<(Pubkey, Pubkey)> - Ajouter un champ
certifiers: Vec<Pubkey>à la structGvaIdtyDbV1.
Et c’est tout, je te laisse réfléchir à pourquoi c’est suffisant pour répondre correctement à tous les cas ![]()
Pour gagner de la place on peut remplacer la clé par un id en u64, sled permet de générer un id garanti unique, il faut juste que je ré-expose cette fonction
Au lieu d’avoir 6 clés publiques par certification on aurait alors 4 id et 2 clés publiques. Soit 4 x 8 + 2 x 33 = 96 octets par certification au lieu de 5 x 33 = 165 octets par certification.
Ce qui donne :
- Ajouter une collection
certificationsdont la clé estU64BEet la valeur une struct du genre:
GvaCertDbV1 {
issuer: Pubkey,
receiver: Pubkey,
created_on: BlockNumber,
written_block: BlockNumber,
}
- Ajouter une collection
certs_by_expireavec comme cléU64BEet comme valeurVec<u64> - Ajouter les 2 champs
certifiers: Vec<u64>etcertified: Vec<u64>à la structGvaIdtyDbV1.
Ok, juste une question : pourquoi certs_by_expire ? pour WotWizard ?
Edit: ou c’est parce que l’expiration de la certification n’est pas dans le bloc ?
donc pour ajouter une certification, il faut d’abord vérifier en parcourant les certifications listées dans le champ certified de l’issuer qu’il n’en existe pas une ayant les mêmes issuer et receiver ; si oui, la modifier, si non, la créer.
Oui c’est ça, je l’ai dit plus haut :
Exactement, bien vu ![]()
Donc le champ certified ne sera pas un Vec mais un HashSet ![]()