Squid remplace Hydra qui n’est plus maintenu.
J’ai réussi à faire fonctionner l’indexer de Squid avec Duniter-v2s en m’inspirant des dockers compose qu’ils donnent dans ce dépôt : GitHub - subsquid/squid-archive-setup: Squid Archive setups for various chains
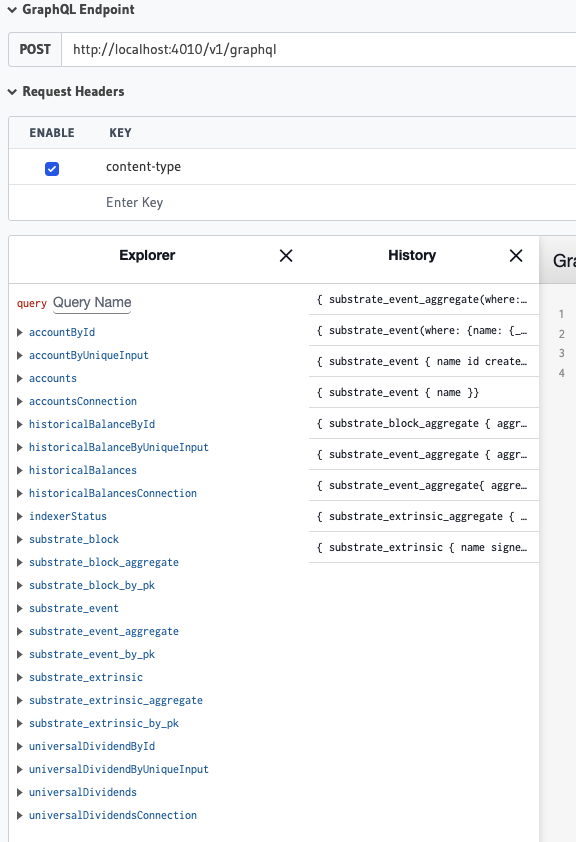
J’ai commité dans le dépôt de Duniter-v2s un docker compose qui permet lancer un nœud duniter-v2s avec un indexer Squid fonctionnel :
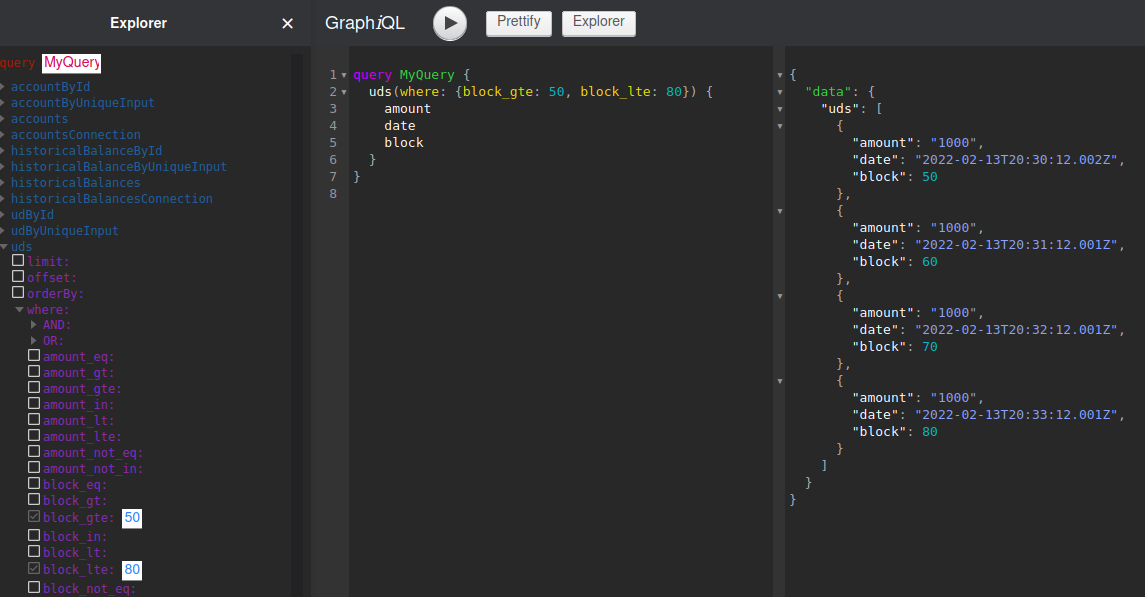
L’API GraphQL de l’indexer est alors accessible à l’adresse localhost:4010/console.
C’est une API brute , commune à toute blockchain substrate, et difficile à utiliser.
- L’étape suivante est de générer des définitions typescript: https://docs.subsquid.io/recipes/generate-typescript-definitions
- Puis définir les schémas GraphQL métier que l’on veut: Define a Squid Schema - subsquid
- Puis mettre tout ça dans un nouveau dépot git basé sur ce template: GitHub - subsquid/squid-template: Squid project template
- Enfin créer une (ou plusieurs) image·s dockers de ce processor pour que ceux qui souhaitent fournir l’API métier puisse intégrer ce qu’il faut à leur docker compose.
@ManUtopiK, @kimamila et @1000i100 j’aimerais bien que vous puissiez travailler là-dessus, tout autre développeur typescript est bienvenue ![]()
Je peux vous aider pour le setup et fournir les explications nécessaires, on peut se faire des visio pour ça, tant que c’est le week-end ça me va ![]()