Pas besoin de 2 explorateurs graphiQL en fait !
Avec les “remote schemas”, on peut avoir le schema de squid dans le schema de l’indexer :

https://5d08-86-250-213-140.ngrok.io/graphql est le endpoint de mon squid, mis dans un pipe ngrok : ngrok http 4350.
L’indexer et squid ne sont pas dans le même container. Il y a peut-être moyen de passer par le network du docker-compose… Je suis passé par ngrok pour faire vite.
Résultat : le endpoint de l’indexer présente les 2 apis :
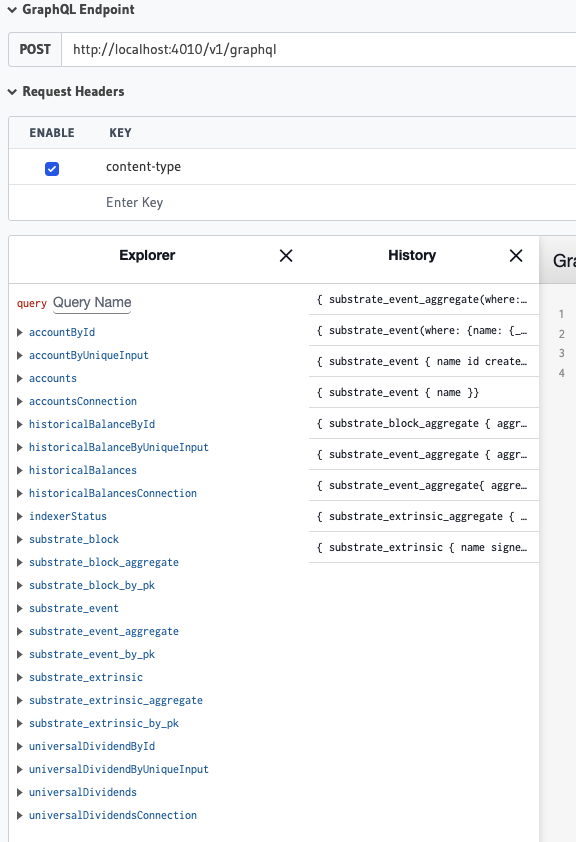
C’est mal de faire ça ?
Je n’ai pas bien saisi l’intérêt de l’indexer je pense. Juste dispatcher sur des squids en microservices ?
Si l’indexer doit rester privée, pourquoi ce n’est pas squids qui contient Hasura ?
Ce serait plus logique d’utiliser Hasura en front (pour profiter des actions, remote schemas, events, cache…) plutôt que l’api de squid construite avec typeorm. De plus, la console d’Hasura est pas trop mal (pas complètement nocode, mais ils y travaillent je crois) pour créer des tables, ajuster les permissions et créer des relationships entre les tables.
Si je veux un nœud pour créer ma propre logique applicative, je vais certainement devoir créer des tables. Hasura permet de créer des relations graphql avec des remotes schemas.
Par ex, je créé une table products dans Hasura :
id: uuid! # primary key de ma table products
createdAt: timestamp!
...
ownerId: ID! # id substrate d'un account
En ajoutant la relation accountById.id = products.ownerId, on injecte le type account de squid dans le type owner de notre table. Et on peut faire une requête graphql :
query products {
id
createdAt
...
owner {
id
balance
historicalBalances
}
}
Ainsi en une requête, je liste mes produits avec les données de la ğ1 de chaque propriétaire de mes produits. C’est carrément plus simple !
Bon, il faut que je prenne le temps de comprendre tout ça un peu mieux. Mais l’intégration d’Hasura dans la stack est bizarre je trouve…