Je ne suis pas tout à fait d’accord. Un site statique, c’est juste un site compilé qui ne bouge pas et qui est servi comme un ensemble de fichiers par un serveur web standard comme nginx ou apache de manière très rapide parce que c’est une chose que ces programmes savent très bien faire.
Un moteur de recherche est un programme assez sophistiqué qui interprète des mots voire des phrases pour diriger un utilisateur qui n’a aucune connaissance du contenu disponible vers la page qui répondra à sa question.
Par exemple, le moteur Algolia utilisé pour le site de documentation de Vuejs et de Vuepress est très pratique et pas du tout overkill à mon avis car il permet à un utilisateur néophyte de trouver une information sans avoir aucune connaissance préalable sur la structure du site.
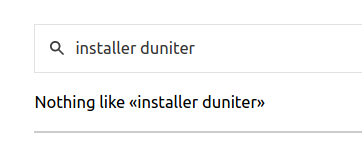
Un cas d’application pour le site de Duniter est une personne qui cherche comment installer un serveur Duniter mais a la flemme de parcourir le site (trois étapes : wiki > forger-des-blocs > installer ). Il va alors dans la barre de recherche et tombe sur ça :
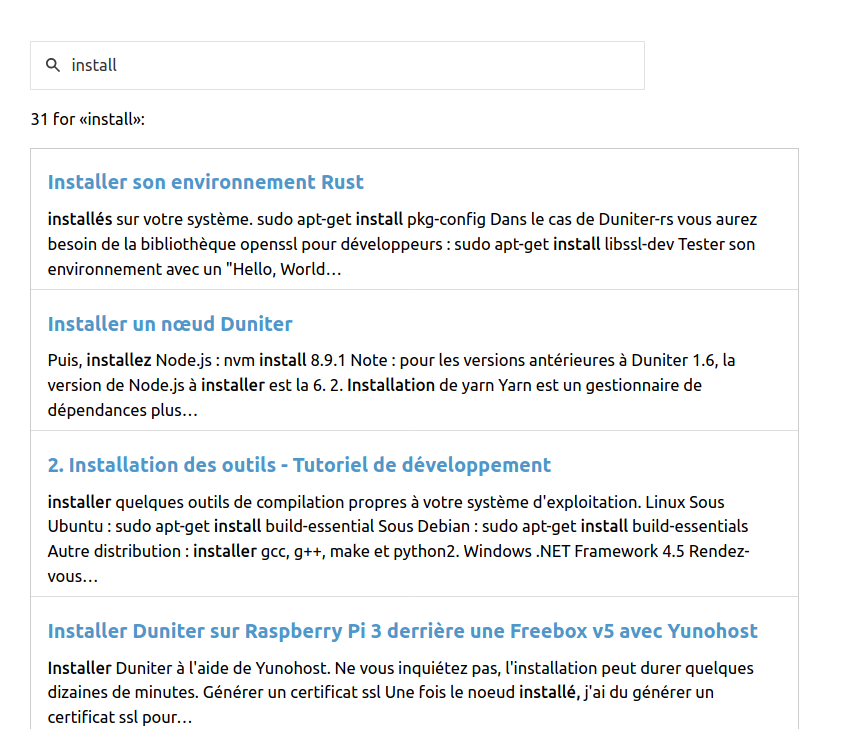
Alors que s’il tape juste “install”, il tombe sur plein de résultats :
Il y a clairement un problème, et c’est lié au fait qu’on n’utilise pas un outil assez sophistiqué pour l’analyse de la langue. Il faut donc un programme sophistiqué, et comme je ne veux pas que ce programme sophistiqué tourne sur la machine de l’utilisateur car je ne veux pas lui envoyer un index lourd de tout le site et un code lourd pour chercher quelque chose dedans, je veux qu’il puisse contacter un serveur qui réponde à cette question compliquée à sa place.
Par idéologie logiciel libre, je ne veux pas utiliser Algolia, je cherche donc un logiciel équivalent que je puisse faire tourner sur un serveur (même third party, mais sous mon contrôle). Par exemple, si je code un truc comme ça et que je connecte la fonctionnalité de recherche du site de Duniter à un service qui tourne sur mon serveur, c’est du third party, mais c’est du third party sous mon contrôle et en logiciel libre sous licence AGPL et qui respecte les RGPD.
Donc mon avis là dessus c’est que ce n’est pas overkill, c’est juste une réponse complexe à un problème complexe de la même manière qu’un site statique est une réponse simple à un problème simple. Par contre, ce n’est pas aussi urgent que le reste donc je me contente de l’existant pour l’instant.
@elois, je veux bien ton avis là dessus aussi si tu as le temps 
 fini
fini ) donc ça ne me dérange pas de fournir le code ET l’image pré-générée ailleurs à chaque modification.
) donc ça ne me dérange pas de fournir le code ET l’image pré-générée ailleurs à chaque modification.