J’ai l’impression dans Gvu de faire le calcul différemment, d’une façon qui me semble intuitivement plus optimisée coté complexité calculatoire mais moins coté complexité mémoire.
Insipiré des concours d’algo sur LeekWars
Voila la fonction que j’utilise : (a partir de la ligne 174)
et quand je fais tourner le script, le calcul de distance m’a l’air d’être quasi instantané, bien loins des 30s dont parle @elois dans le même topic.
Bref, mon approche vous semble-t-elle intéressante ? Viable avec la monté en taille de la WoT ? (mais la proportion décroissante des membre référents dans celle-ci au fur et à mesure que le seuil pour l’être augmentera) ?
@1000i100 le plus simple serait que tu intègre des tests unitaires calculant la distance sur des données aux résultats connues, je peut te fournir les données connues pour tel bloc afin que tu t’assure que ton calcul obtient bien les résultats attendues !
Après nano a conçu un nouvel algo de calcul de distance basé sur les itérateurs fonctionnel de Rust et optimisé a mort et le temps de calcul est passé de 30 à 10 secondes sur mon pc de développement !!
En fait 30s c’était le temps de calcul sur mon pc perso qui n’est pas une bête de course, évidemment que c’est beaucoup plus rapide sur un bon serveur
Je viens de vérifier : pour calculer la qualité d’un membre, mon algorithme met entre 6 et 7 ms (5,7s pour 873 membres). Pour le degré de centralité, c’est un peu plus lent : 13 à 14 ms. Je pourrais faire les mesures pour la règle de distance si cela intéresse quelqu’un.
Toutefois, j’utilise des ensembles d’entiers implémentés par des suites d’intervalles. C’est très rapide pour quelques centaines ou milliers de valeurs, mais les performances chuteront au delà.
@gerard94 a noter qu’il est possible de calculer la qualité et la distance en même temps, c’est ce que fait le module worb rust, il suffit de fournir la taille de la bordure (les référents à 5 pas), et cette même bordure est la différence entre qualité/connectivité et distance
Oui, tout à fait. À un pas près, c’est le même calcul. Pour le degré de centralité, une première partie du calcul doit être faite sur l’ensemble du réseau (algorithme de Floyd–Warshall), mais le reste peut être fait indépendamment pour chaque membre. J’avais trouvé d’abord un algo un peu plus lent et compliqué en cherchant tous les plus courts chemins à partir de chaque membre par une recherche en largeur d’abord. Ça marche pas mal. Et il permet éventuellement de définir autrement le degré de centralité en comptant le nombre de chemins les plus courts passant par un membre donné, au lieu de ne compter que les extrémités de ces chemins, comme tu le fais.
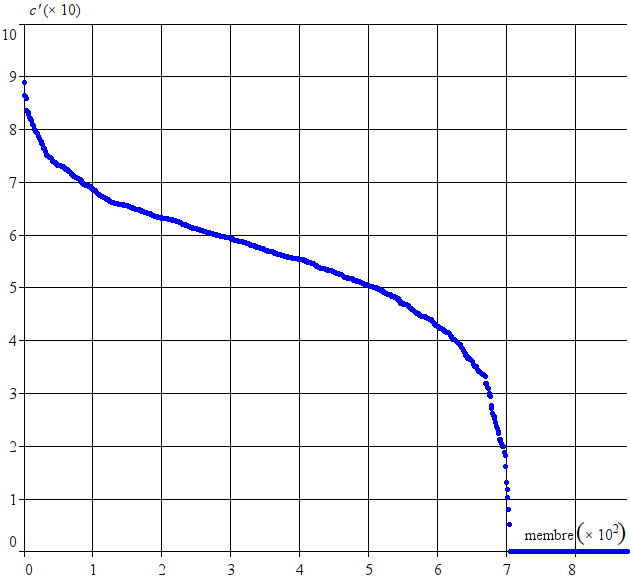
J’aime bien aussi, si c est le degré de centralité d’un membre, calculer la quantité :
c’ = 100 * ln(1 + c) / ln(1 + (n - 1) * (n - 2))
Je prends le log de c pour obtenir une échelle de valeur plus régulière. J’ajoute 1 dans le log car c peut être nul, et (n - 1) * (n - 2), où n est le nombre de membres, est la plus grande valeur possible de c. On peut appeler c’ le “niveau de centralité”, et c’est une valeur assez bien répartie entre 0 et 100.
Merci j’ai essayer justement y a 2 semaines de definir une centralité relative pour que la grandeur soit humainement parlante et je suis partie sur le taux de couples orientés en pourmillèmes mais ce n’est pas satisfaisant, je vais probablement me servir de la quantité que tu propose pour g1-monit v2