Dans le contexte d’une appli mobile, on fait confiance une fois pour toutes à l’appli qu’on télécharge, et ensuite on l’utilise pour signer des documents. Mais dans le contexte d’une extension navigateur, on peut se connecter à des sites variés auxquels on ne fait pas nécessairement confiance. L’extension navigateur a donc comme mission de nous afficher ce qu’on est en train de signer pour qu’on puisse vérifier qu’on ne nous fait pas signer autre chose que ce qu’on prétend nous faire signer. Par exemple, un site qui nous ferait signer une transaction de 1000 Ğ1 alors qu’on avait cliqué sur un bouton pour donner 1 Ğ1.
Donc il faut que les documents à signer puissent être reconnus par l’extension navigateur. Ce n’est pas le cas des documents de révocation, de changement de clé, et de liaison de compte qui sont des formats binaires custom. Donc un site qui prétend nous aider à télécharger notre document de révocation pourrait en fait nous faire signer ce qu’il veut sans que ce soit facile de faire la différence pour l’utilisateur.
Pour Duniter v2, la plupart des documents sont des extrinsics encodés au format SCALE, sauf ceux que je cite plus haut. Et pour les Datapods, je suis parti sur un format concaténé binaire custom déduit de manière rigoureuse à partir des données de la demande d’indexation, mais je me rends compte que c’est un problème car l’extension Duniter-connect ne sait pas les interpréter et les wrappe donc dans des balises <Bytes></Bytes>, ce qui rend la signature invalide, car elle ne correspond pas au document.
Il vaudrait donc mieux choisir un format texte lisible directement par l’utilisateur, ou affichable de manière compréhensible et non ambigüe par l’extension, et qui puisse être déduit de manière reproductible des données de demande d’indexation quel que soit le format dans lequel elles sont stockées.
Je précise ce point : s’il s’agit d’un document json, par exemple, il faut définir l’ordre des champs, les éventuels blancs (saut de lignes, espaces, tabulations…) pour que les même données donnent toujours le même payload quelle que soit l’implémentation. D’où ma préférence pour un template bien défini, qui n’a pas besoin d’être parsé s’il est lu par un humain, qui a besoin d’être parsé si on veut l’afficher de manière esthétique dans une interface, et qui peut être regénéré sans ambiguïté.
Et ce n’est pas forcément facile. Par exemple, si on veut signer on document disant qu’on change d’image de profil, il n’est pas forcément possible d’afficher l’image à l’utilisateur, et afficher un hash n’est pas suffisant, puisque ça pourrait être le hash d’une autre image (par exemple la même image mais avec une watermark publicitaire, ou la même image mais contenant un virus en stéganographie).
Un format que l’extension peut parser facilement : le json, et pour son affichage pour l’humain, sa version en Yaml ?
En effet le Yaml, n’est autre qu’une représentation “humaine” d’un json. L’avantage du json est qu’il est analysable par une application et lisible en Yaml par un humain.
Ce qui serait signé serait le json. S’il est converti en Yaml juste pour affichage, il peut même être brut sans espace ni saut de ligne pour l’extension (no pretty).
Je ne comprends pas bien la problématique, mais si un client veut me faire signer un truc que je ne veux pas, et que c’est lui qui m’affiche ce que je suis en train de signer, il peut toujours me tromper.
Il faudrait plutôt que ce soit le client qui se signe, et que duniter puisse vérifier cette signature pour s’assurer que le client est bien dans la whitelist.
Je ne sais pas si je me fais bien comprendre.
Au moins pour les documents blockchain, est-ce possible d’utiliser Yaml pour les humains, et de signer la représentation unique dans le format custom ? Parser correctement ces formats compliqués (Yaml, nombres décimaux, baseN) demanderait d’ajouter des dépendances au runtime, par rapport à un format custom simple ou du SCALE.
Si on signe des documents ASCII, on risque d’avoir des problèmes et incompréhensions à cause par exemple de Windows qui changerait des nouvelles lignes, ou espaces en fin de lignes lors de copier-coller que les gens feront inévitablement. Certes on peut toujours signer un format canonique, mais un jour un dev de client oubliera de transformer le document en forme canonique parce qu’en général c’est déjà le cas, et il aura un bug plus tard. Si on oblige à signer une forme non-ASCII, on n’aura pas ce problème.
De toute façon l’utilisateur doit faire confiance à son client s’il y tape sa clé privée. Dans le cas d’une page web frauduleuse, le client n’est pas la page web mais l’extension de navigateur. La page web demande à l’extension de signer un document, et l’extension doit pouvoir montrer à l’utilisateur ce qui est signé, sans qu’il puisse y avoir ambiguïté.
Duniter ne peut vérifier le client utilisé, comme un client peut toujours mentir (Gecko pourrait faire semblant d’être Cesium). L’important est que le client soit libre et puisse avoir la confiance de l’utilisateur en termes de sécurité, de fiabilité et de loyauté.
Une whitelist des émetteurs de documents à signer serait trop peu pratique. L’intérêt de l’extension est de pouvoir signer n’importe quoi sur des sites marchands même sans devoir leur faire confiance.
Il n’y a pas de nécessité que le payload signé soit transmis tel quel. On peut juste transmettre des infos qui permettent de reconstruire le payload et la signature du payload. Donc pour vérifier, pas besoin de parser un payload, simplement de reconstruire le payload connu à partir des arguments. Il faut juste que cette reconstructions soit indépendante des plateformes.
Par exemple, on peut fournir les données en SCALE, ce qui permet à Duniter de les décoder sans dépendance, mais le payload peut être un texte reconstruit à partir des données suivant un template. Et si ce template est un format comme json ou yaml, ça permet à une extension navigateur de l’afficher de manière “jolie” sans avoir à connaître au préalable tous les formats de documents possible.
Le yaml est trop ambiguë je pense (espaces ou tabs, espaces en trops, sauts de ligne Windows ou linux) pour être signé’ c’est seulement le json qu’on en sort qui est signé (un json sans espace ni saut de ligne).
L’ambiguïté qui pose problème n’est pas que plusieurs documents peuvent être parsé dans un objet identique, mais qu’un même objet peut être sérialisé de plusieurs manières différentes. Donc le yaml convient à partir du moment où il est “sérialisé” suivant un template bien précis (ordre des champs, sauts de ligne, guillemets, espaces…) qui peut être reproduit facilement d’un langage à l’autre par simple concaténation de strings ASCII.
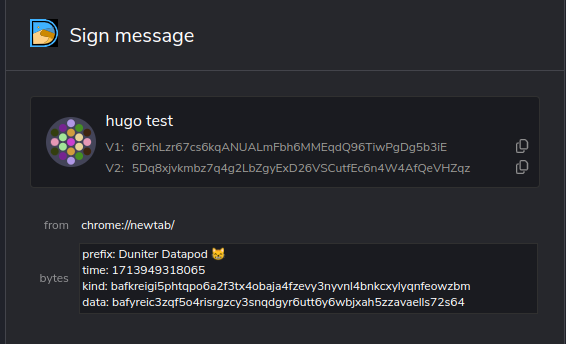
Euh unicode apparemment, vu que l’extension duniter connect m’affiche bien les smiley en plus du document :
Pour info, voici mon payload actuel :
// build payload to sign
export function buildStringPayload(ir: IndexRequest) {
let payload = `prefix: Duniter Datapod
time: ${ir.time}
kind: ${ir.kind.toV1()}
`
if (ir.data)
payload += `data: ${ir.data.toV1()}
`
return payload
}
En effet ils ont bien fait les choses, quand j’insère des caractères invisibles (espaces de largeur nulle, bidirectionnel right-to-left) je n’ai que l’affichage en hexa.
L’inconvénient est que les accents français ou d’autres caractères comme l’arabe ne passent pas. Donc cette méthode n’a d’intérêt que pour des formats ne contenant pas de texte brut venant de l’utilisateur.
On pourrait s’éviter de reconstruire un Yaml ou JSON dans le runtime en signant le SCALE.
De toute façon on ne demandera pas aux utilisateurs de lire du Yaml, les clients afficheront tout ça d’une manière plus jolie, donc devront comprendre ces formats. Signer du SCALE gênera tout au plus les développeurs travaillant sur de nouveaux formats qui ne seront pas encore compris par les clients.