Je m’aperçois que ce nouveau comportement va nécessiter d’implémenter la clique côté indexeur.
Et pareil pour le fait de passer de address à pubkey. Ce serait peut-être plus malin de sortir un fichier genesis complet pour ce genre de cas plutôt que de redévelopper dans chaque outil (indexeur, wotwizard…) la conversion pubkey→address et la génération de la clique. Pareil pour le treasury_funder, c’est une info en amont du genesis, mais une fois construit, elle n’a plus d’intérêt.
La méthode gen_genesis_data est justement faite pour standardiser la spec en sortie (Genesis Data) et abstraire les entrées (Genesis Input). Le concept de clique (Input) n’existe plus en sortie de cette méthode, pas plus que le treasury_funder, ni les pubkeys non plus.
Par ailleurs, juste avant la sortie (Data), un “hook” est présent pour préparer le fichier de l’indexeur via la variable d’environnement DUNITER_GENESIS_EXPORT qui indique où le déposer, et qui donc ne verra que des adresses, smithWoT, et le montant sur le compte de Tresorerie. Tous les concepts propres aux entrées (clique, pubkeys, etc. : Input), auront disparu au profit des concepts de sortie (Data).
J’ai l’impression que tu confonds les deux, peut-être parce que tu raisonnes encore un peu dans l’ancien mode de fonctionnement.
Plutôt utiliser DUNITER_GENESIS_EXPORT qui exporte un fichier qui vise les indexeurs et ne s’embarrasse pas des concepts qui leurs seront superflus liés au Storage.
C’est donc de ce format que je veux parler. Ça pourrait être la même chose que la sortie de build-spec débarrassée des champs inutiles, mais on peut aussi juste les ignorer.
J’ai commencé à expérimenter avec ça côté indexeur en tout cas.
interfaces typescript du genesis
interface Genesis {
runtime: any
identity: Identities
membership: Memberships
account: Accounts
cert: Certs
babe: any
parameters: any
balances: any
authorityMembers: InitialAuthorities
session: any
grandpa: any
imOnline: any
authorityDiscovery: any
sudo: any
technicalCommittee: any
universalDividend: any
smithMembership: Memberships
smithCert: Certs
treasury: any
}
interface Identities {
identities: Array<Identity>
}
interface Identity {
index: number
name: string
value: IdtyValue
}
interface IdtyValue {
data: IdtyData
next_creatable_identity_on: number
old_owner_key: string | null
owner_key: string
removable_on: number
status: string
}
interface IdtyData {
first_eligible_ud: number
}
interface Memberships {
memberships: Map<number, Membership>
}
interface Membership {
expire_on: number
}
interface Accounts {
accounts: Map<string, Account>
}
interface Account {
random_id: string
balance: number
is_identity: boolean
}
interface Certs {
applyCertPeriodAtGenesis: boolean
certsByReceiver: Map<number, Map<number, number>>
}
interface InitialAuthorities {
initial_authorities: Map<number, Array<any>>
}
Et autre question, je vois que pour l’instant tu as conservé les client-specs.json pour la gtest. Il faudrait peut-être aussi harmoniser cette partie ?
J’ai modifié mon message ci-dessus, le terme GenesisConfig est déjà utilisé par Substrate. Je participais à la confusion.
Quand j’ai présenté ce fichier (du moins, c’était la sortie de gen_genesis_data qui est très proche de la sortie de build-spec) à @ManUtopiK, sa réaction a montré qu’il s’attendait plus à un fichier comme celui anciennement généré par py-g1-migrator.
C’est pour ça que je pour l’instant j’ai laissé la possibilité de créer un fichier différent à destination de son indexeur.
On pourrait, oui. Il me semble que c’est un détail, je ne me suis pas trop penché dessus.
Je pense que Manu n’a pas trop suivi les évolutions côté Duniter et indexeur. Je vais m’occuper d’adapter l’indexeur au nouveau format parce que j’aimerais avoir un indexeur en place le plus rapidement possible après lancement du réseau. De plus, côté indexeur, ça n’a pas de sens de mélanger les données de certifications et d’adhésion dans une seule entrée identities, donc autant faire simple et rester proche de la sortie de gen_genesis_data (qui est identique au champ genesis de la sortie de build-spec.
Pour les client-specs, on peut laisser tomber complètement pour l’instant. On pourra toujours écraser les bootnodes en ligne de commande et on n’a pas vraiment besoin d’un fichier à part, on peut se contenter d’éditer les specs. Donc en finissant ta MR tu pourras juste copier-coller les commandes pour gdev_dev, gdev_live et gdev en remplaçant gdev par gtest et en ignorant les différences que j’avais introduit pour gtest comme les client spec.
D’après mes vérifications faites cette semaine, la sortie de gen_genesis_data ne devrait plus bouger. J’ai trouvé un bug hier (corrigé depuis), mais dans les grandes lignes le résultat me paraît correct et stable.
Je m’aperçois qu’avec le nouveau format il n’y a plus possibilité de distinguer les identités du genesis qui ne sont plus membres. Les inactive_identities semblent tout simplement ignorées. À mon avis, il faudrait conserver les identités non membres au genesis d’une manière ou d’une autre, pour que les pseudos soient toujours réservés et que la correspondance compte / identité soit toujours présente.
Et si on choisit de ne pas le faire côté duniter (possible mais à argumenter), il faudra au moins que ce soit possible côté indexeur.
[edit] j’ai l’impression que c’est un choix de ne pas avoir intégré les identités qui ne sont plus membre, mais du point de vue indexeur, c’est nécessaire d’avoir un idty_index, un pseudo et une addresse pour toute identité qui est à un bout ou un autre d’une certification.
Et c’est dommage de perdre soudainement la correspondance de milliers de comptes ayant des Ğ1 avec leur ancienne identité.
Donc il faudrait faire une liste des identités non membres et la sortir dans le fichier de l’indexeur. inactive_identities devrait aussi être un Vec<GenesisMemberIdentity>.
Autre option, ajouter une variante IdtyStatus::Disabled et ignorer ces identités au genesis.
Effectivement, mais c’est déjà le cas sur la branche master pour toutes les monnaies.
Le mieux que je puisse faire, pour rester cohérent avec do_remove_identity qui supprime les traces d’une identité expirée, c’est de ne conserver que le mapping pseudo → idty_index. Par contre, cette méthode ne conserve pas le lien avec le compte (et forcer ce point n’est pas simple).
Voici en tout cas le commit pushé sur ma branche, qui me permet par exemple de demander au Storage l’idty_index d’Inso, ce qui n’était pas permis avant.
Je viens de regarder le fonctionnement de Subsquid, concrètement cet indexeur fait de l’ingestion via l’API RPC. Ce qui signifie que si l’on veut disposer de l’owner_key d’une identité expirée de la Ğ1v1, alors il faut nécessairement une entrée dans le storage (au moins au bloc#0, car on peut imaginer que ces identités sont purgées au bloc#1).
L’indexeur de Manutopik quant à lui est capable d’intervenir en amont, via le fichier par DUNITER_GENESIS_EXPORT.
Je crois que nous n’avons pas trop le choix : il va falloir inclure ces identités dans le Genesis et les purger au bloc#1 afin de ne pas encombrer le Storage.
Allez, je l’ai fait. Petit changement, ce n’est pas au bloc#1 mais au bloc#2 que les identité expirées sont effectivement sorties (je ne comprends pas bien pourquoi ça ne fonctionne pas au bloc#1 directement, mais peu importe).
On a un peu plus de 5800 identités qui expirent au bloc#2, mais Susbtrate encaisse cela correctement (ça fait 4x5800 écritures dans le Storage, on sent que le bloc met plus de temps à être créé tout de même).
Sur un nœud archive, j’arrive bien à obtenir l’adresse d’Inso au bloc#1, et je ne la retrouve plus au bloc#2. C’est parfait, problème résolu @HugoTrentesaux
Bug sur les sufficients
Au passage, grâce au TU écrit pour l’occasion, j’ai vu que nous avions un bug sur les sufficients qui n’étaient pas incrémentés au Genesis. A priori, nous aurions eu un bug à la 1ère expiration de l’une des identités. Mais je suis étonné que cela ne se soit pas produit sur les ĞDev 500 et inférieures.
Alors, j’ai compris d’où ça venait : le champ sufficients associé à un compte était placé dans la pallet duniter-account et initialisé à 1 pour les membres. Donc lors d’une suppression sur la ĞDev (due à une révocation ou une expiration), effectivement il n’y a jamais eu de problème à décrémenter de 1.
Initialiser plutôt les sufficients dans la pallet identity
Néanmoins cette initialisation à 1 des sufficients dans pallet-account n’est pas idéal, puisque la seule pallet à incrémenter/décrémenter les sufficients est la pallet identity. Par principe de programmation (SSOT), le meilleur endroit est plutôt la pallet identity notamment au niveau du build du Genesis comme j’ai été contraint de le rajouter.
Ça permet aussi de tester la suppression de compte directement dans les tests de la pallet identity plutôt que de devoir tester le Runtime complet.
C’est amusant, j’en étais venu à une conclusion similaire, mais je m’étais fait rembarrer par elois :
Aujourd’hui je pense que les deux options se valent en terme d’avantages / inconvénients : ajouter les identités et le retirer au bloc 1 ou ne pas les ajouter mais les mettre dans un fichier à part à destination des indexeurs.
Merci d’avoir intégré ça à ta MR, ajouté des tests, et corrigé des bugs ! Perso j’assume totalement ce comportement de ménage programmé des identités v1. Ça permet d’éviter un effet de bord du genesis tout en restant compatible avec les règles du protocole.
Oui, il a utilisé un superlatif exagéré “très mauvais design”, c’est qu’il n’avait pas d’argument et que l’idée ne lui plaisait pas.
Mais en regardant objectivement : ce n’est pas possible autrement si l’on souhaite utiliser un indexeur générique comme Subsquid qui fait de l’ingestion RPC.
Mais oui, on s’en fiche complètement : le Storage sera élagué de ces données, et les nœuds archives ne vont pas subir de charge particulière pour si peu de données.
2023-10-31 13:53:15 prepared genesis with:
- 33659 accounts (8144 identities, 19903 simple wallets)
- 13766 total identities (8144 active, 5622 inactive)
- 7 smiths
- 1 initial online authorities
- 97727 certifications
- 42 smith certifications <-------- décidément, il est partout celui là ><
- 7 members in technical committee
Autre note : ce serait pratique que l’identité Alice du genesis en mode dev corresponde à la clé Alice “substrate” ("bottom drive obey lake curtain smoke basket hold race lonely fit walk//Alice") et pas Alice “Ğ1” (identité numéro 477).
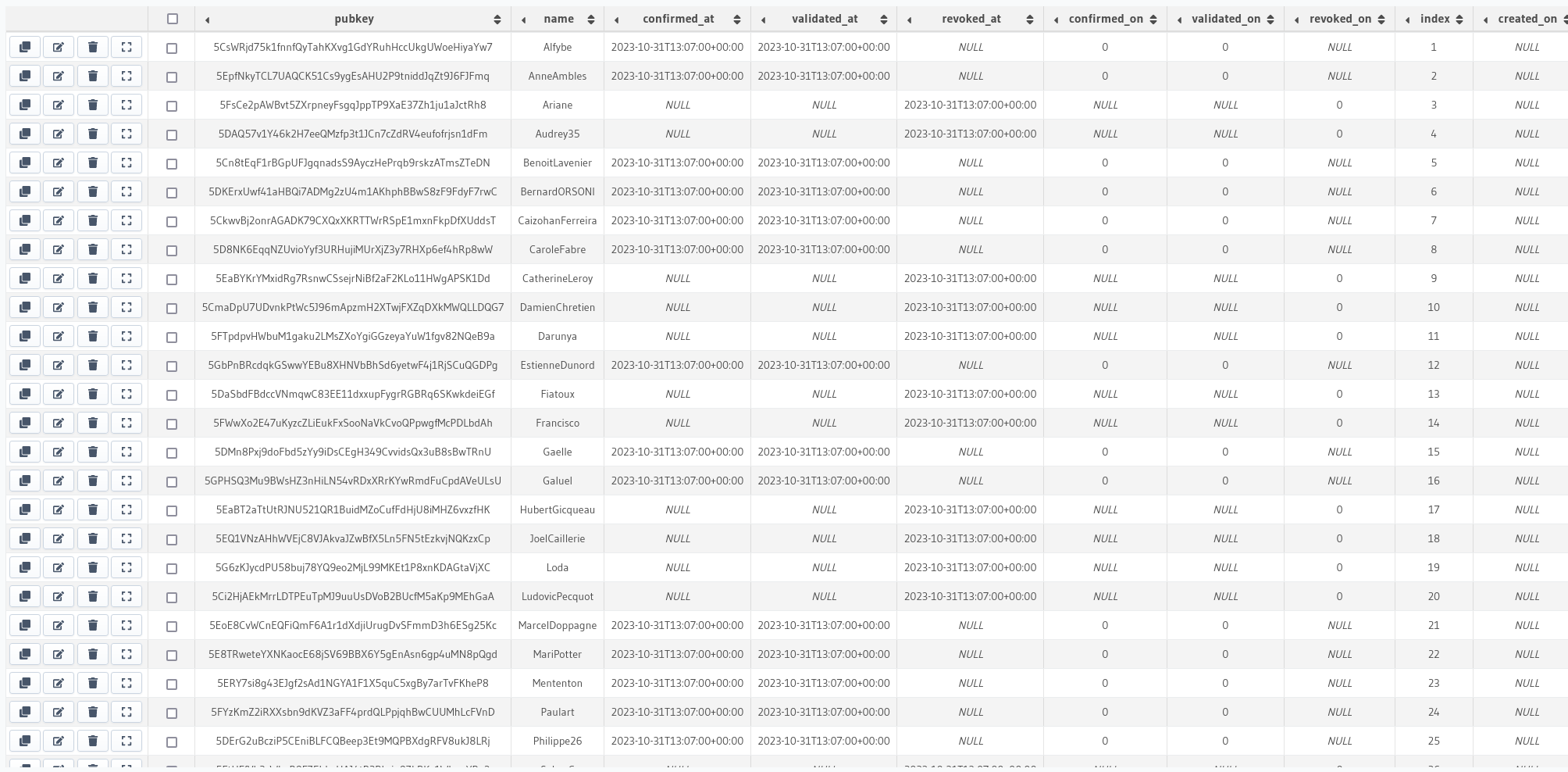
Petit aperçu des identités indexées à partir de la sortie de build_spec
Ça me fait penser qu’on pourrait aller un peu plus loin en utilisant les données historiques de la Ğ1 pour avoir la date de création et de révocation des identités pré-genesis. Mais c’est du bonus, pas du tout utile pour l’instant.
et les tests effectués pour generate_genesis_data ne sont pas effectués pour generate_genesis_data_for_local_chain. C’est normal, mais ça ne coûte pas grand chose de bouger les tests dans une fonction test_genesis_data qui s’exécute dans tous les cas.
Bien vu, j’avais aussi vu le soucis de placement de smith_certs_by_receiver mais le sujet m’est sorti de la tête entre-temps. Merci.
Puis-je te laisser regarder ? C’est dans la méthode make_authority_existqu’il faut regarder. A mon avis, il faut lui mettre un pseudonyme spécifique, par exemple préfixer par “Substrate”, ce qui donnerait “SubstrateAlice” en pseudonyme et obligerait make_authority_exist à créer un compte (avec les certifs, etc., tout est déjà codé normalement). Mais bien garder “Alice” pour dériver l’adresse.
Super on se rapproche du re-démarrage de la ĞDev, ça se sent