Traduction du ticket Profile disk use (#267) · Issues · nodes / rust / Duniter v2S · GitLab
Pour se donner un peu de visibilité sur l’espace disque nécessaire à un nœud Duniter (ce qui concerne surtout les nœuds archive et forgeron), j’ai extrapolé l’espace disque nécessaire pour un nœud en me basant sur les données du réseau GDev actuellement déployé.
Méthode
Afin de fournir une estimation des exigences de stockage, j’ai surveillé l’espace disque utilisé par un nœud archive (target/release/duniter --chain=gdev --blocks-pruning=archive --state-pruning=archive). J’ai enregistré le numéro du bloc importé ainsi que l’espace disque occupé par le nœud toutes les 30 secondes, en maintenant ce processus de manière régulière pendant plusieurs semaines.
Résultats
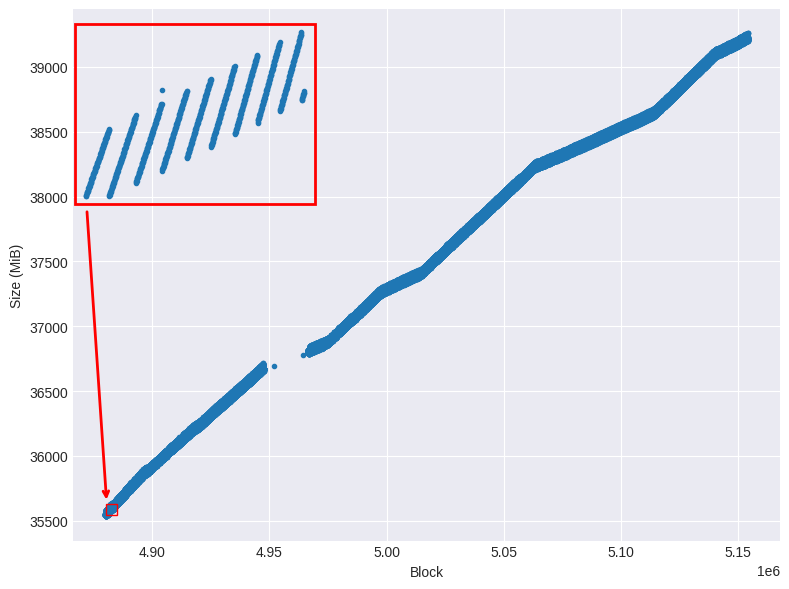
La Figure 1 illustre la relation entre le nombre de blocs importés et l’utilisation correspondante de l’espace disque. Les données montrent une augmentation non linéaire du stockage durant la période d’observation. À des intervalles de temps plus courts, cette augmentation se manifeste par des paliers discrets.
Figure 1 : Nombre de blocs versus utilisation de l'espace disque pendant la période observée.
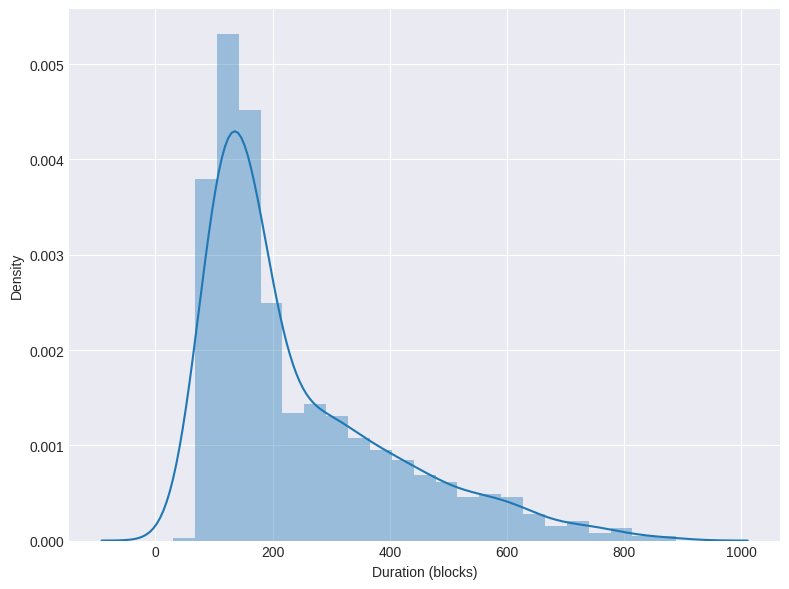
La Figure 2 illustre la distribution de la durée de ces paliers en nombre de blocs. La durée des paliers est fortement variable, avec une prédominance notable autour de 100 blocs (soit environ 10 minutes).
Figure 2 : Distribution des durées des paliers.
La Figure 3 présente l’évolution de l’utilisation de l’espace disque du nœud, montrant à la fois les données mesurées et la courbe ajustée. Pour modéliser la croissance, les données ont été ajustées à l’aide d’un polynôme de second degré sans terme constant, la fonction continue la plus simple qui suppose que l’espace disque au bloc zéro est proche de zéro et qui représente de manière adéquate le comportement observé. Cette fonction met en évidence l’accélération des besoins en stockage à mesure que la blockchain évolue.
Figure 3 : Évolution de l'utilisation de l'espace de stockage depuis le démarrage du nœud, ajustée à l'aide d'un polynôme de second degré.
Prédiction
Je n’ai pas encore mené d’investigation détaillée sur l’augmentation par paliers du stockage. Bien que ce phénomène n’ait pas d’impact direct sur la croissance globale de la taille du stockage, sa cause reste incertaine. Il est probable qu’il résulte soit d’une suppression différée des fichiers au niveau de la base de données/système, soit d’une compression quasi-périodique des structures de données intermédiaires au niveau du nœud. Pour mieux comprendre d’où provient ce comportement, l’enregistrement de données provenant d’un nœud fonctionnant avec RocksDB pourrait apporter plus éclaircissements.
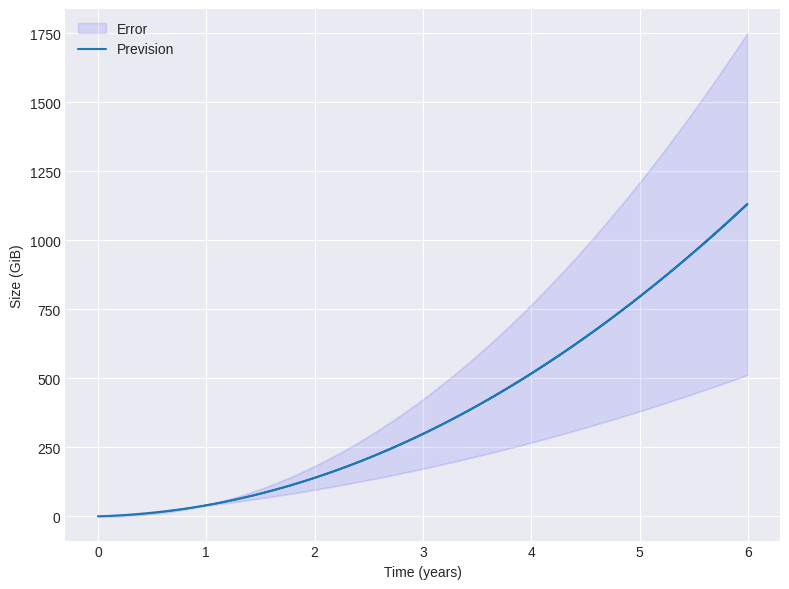
Sur la base des résultats observés, il est évident que l’utilisation de l’espace disque suit une tendance non linéaire. Les données collectées, bien que limitées, peuvent être ajustées à l’aide d’un polynôme de second degré. La Figure 4 présente l’utilisation projetée de l’espace disque selon cet ajustement polynomial, accompagnée des marges d’erreur calculées à partir de la matrice de covariance de l’ajustement. Cela permet d’obtenir une prévision préliminaire des besoins en stockage, tout en soulignant l’incertitude inhérente du modèle et au jeu de données restreint.
Figure 4 : Prédiction de l'utilisation de l'espace disque.
Les observations du réseau Polkadot indiquent qu’un nœud archive nécessite environ 2 765 GiB de stockage après 4,71 ans de fonctionnement (source : stakeworld.io, Polkadot wiki). En revanche, notre réseau reste largement inactif, avec une croissance du stockage principalement due aux opérations nécessaires pour forger des blocs vides et assurer les fonctions de base du réseau, telles que les DUs et les certifications.
Compte tenu de ces conditions, notre prédiction de 500 ± 250 GiB de stockage après 4 ans (bien que reposant sur des données limitées) semble plausible par rapport à des réseaux très utilisés comme Polkadot. Cette estimation fournit un repère approximatif des futurs besoins en stockage, notamment lorsqu’elle est comparée à des réseaux de longue durée tels que Polkadot et Kusama, où un niveau d’activité plus élevé contribue de manière significative à la croissance du stockage.
Conclusion
Les données actuellement disponibles fournissent un modèle avec un pouvoir prédictif modéré pour les 2 premières années, mais limité au-delà. Cependant, elles offrent une estimation raisonnable, notamment lorsqu’elles sont combinées avec les tendances de stockage des nœuds Polkadot. Ces données suggèrent qu’au cours des 3 à 4 prochaines années, les besoins en stockage ne dépasseront probablement pas 1 TiB. Cela s’inscrit plutôt bien dans les tendances actuelles de taille et de prix des SSD pour des exigences matérielles modestes.
Pour affiner ces prédictions, une surveillance continue de l’utilisation de l’espace disque d’un nœud sera essentielle, surtout à mesure que l’activité du réseau augmente. L’augmentation du volume des transactions, en particulier avec le stockage on-chain des commentaires de transactions, pourrait avoir un impact significatif sur les besoins futurs en stockage. En mettant régulièrement à jour le modèle, nous pourrons fournir des prévisions plus précises à mesure que le réseau et ses dynamiques évoluent.