@kimamila a émis certaines remarques à propos de ma proposition de datapods que je reformulerais ainsi :
même si le mode “purement décentralisé pair-à-pair” (pubsub/ipfs) est idéal, une alternative “décentralisée uniquement côté serveur” (http côté client) serait souhaitable pour permettre le développement de clients sans embarquer de nœud ipfs (par exemple pour des applis autres que javascript)
le format de signature standardisé que je propose dans les datapods (prefix+time+kind+cid) impose de savoir calculer un cid (“multiformats” et autres), ce qui contraint à avoir des dépendance, on pourrait accepter d’autres formats de signature comme Cesium+
les données “v1” devraient être importées en l’état, sans conversion au niveau du stockage, même si une conversion peut être faite a posteriori pour servir les données de manière uniformisée
Il ne me reste plus qu’à implémenter ça
Mais pour l’instant je suis reparti sur Duniter qui avait besoin d’un peu de travail. Et il faut aussi régler la migration des données v1 historiques dans Duniter-Squid.
Accepter plusieurs formats c’est obliger les clients à implémenter tous ces formats, au moins partiellement. (si le commentaire a été envoyé depuis un client qui préfère l’autre format, il faut pouvoir le décoder et le vérifier)
L’idéal serait que les seules dépendances du codec soit un hash standard et une signature standard, ainsi chaque langage pourrait avoir sa bibliothèque client datapod très légère (sans compter la partie réseau). Il y a moyen de ne pas calculer de cid et de se contenter d’un SHA2, quitte à reconstruire le cid à partir de ce hash ?
Disons que si le développeur de Cesium développe son propre format qui convient à Cesium, ça forcera les autres client qui utilisent les données de Cesium et veulent vérifier la signature ou soumettre un document à implémenter ce format.
Et si un autre développeur veut développer une autre application, comme Ğchange ou Ğecko, il aura le choix entre reprendre les formats existants pour se mettre en compatibilité ou développer son propre format pour les documents qui concernent a priori uniquement son usage jusqu’alors. Par exemple pour un format chiffré de préférences d’application (affichage des prix en DU / Ğ1 par ex).
Le cid permet d’utiliser le format de hash qu’on veut, c’est juste que le cid-v1 demande d’expliciter :
multihash : l’algo de hash utilisé (par défaut sha2-256 je crois)
multibase : la base utilisée pour encoder ce hash (par défaut base32 je crois)
Coller un cid comme bafybeifmxpb2zuqfcj64swjle24eicb4mph4humrtsr3yb23ra6iww4ksq dans https://cid.ipfs.io/ pour l’inspecter.
Mais il faut quand même savoir ce qu’on hashe, et c’est le but du champ multicodec.
Je suis favorable à l’utilisation du cid avec multiformats, mais pas contre gérer les formats legacy comme celui de Cesium+.
Ma proposition est que l’App puisse publier ses données via une mutation GraphQL du datapod.
Cela ne dit rien que le choix du(des) datapod(s) à qui on envoie les données. Cette solution peut donc être aussi considérée comme “totalement décentralisée”. C’est juste de moyen de sélection des pairs qui change : libp2p, scan réseau maison, etc. plutot que forcément via noeud local ipfs (qui lui aussi va faire une sorte de scan réseau).
Je n’ai rien demandé de ce côté. Tu as du mal comprendre.
Cela ne me pose pas de problème d’utiliser ces librairies (cid, dag-cbor, etc) pour les nouveaux documents.
Je constatais juste qu’il fallait que j’importe ces lib. Mais elles sont légères, et surtout n’impacte pas les performances (contrairement à avoir un noeud IPFS local, sur un smartphone)
L’avantage ici est :
de pouvoir continuer de mettre à jour les profils v1 dans IPFS (pour les utilisateurs qui feraient la bascule avec un délai, en continuant un temps d’utiliser G1v1 par exemple)
d’avoir des documents non modifiés, intègres et vérifiables sans tiers de confiance.
de suivre le processus de migration : en effet, les App V2 pourrait gérer la migration automatiquement vers le nouveau format. On saurait ainsi combien d’utilisateurs (avec profils) ont basculés en G1v2
L’inconvénient est :
plus lourd en stockage, notamment du fait de l’image (avatar) en base64. Mais bon, on parle d’image de quelques pixels…
La encore, je ne crois pas avoir demandé cela.
Je n’ai pas besoin d’un cid maison. Le cid est la référence IPFS d’un fichier (profile, etc.). Ma demande est juste de laisser le fichier profile intact, plutot que de le reconstruire depuis un tiers de confiance qui va le resoumette à IPFS tout modifié, donc potentiellement tronqué et/ou falsifié.
le champ “kind” est devenu une string (plus nécessairement un cid) et vaut cplus_raw pour ces profils
le champ “signature” est nullable, ce qui signifie que la signature est intégrée directement dans la data, et pas dans la index request, le datapod sait importer ceci, mais pas vérifier une signature dans la data
il est possible de soumettre une demande d’indexation directement par HTTP POST (https://submit.datapod.coinduf.eu/) en utilisant un array json contenant
en première position le cid de la demande d’indexation (string)
ensuite les blocs composant la demande d’indexation et les blocs ipfs liés (data, images…) encodés sous forme de string base64
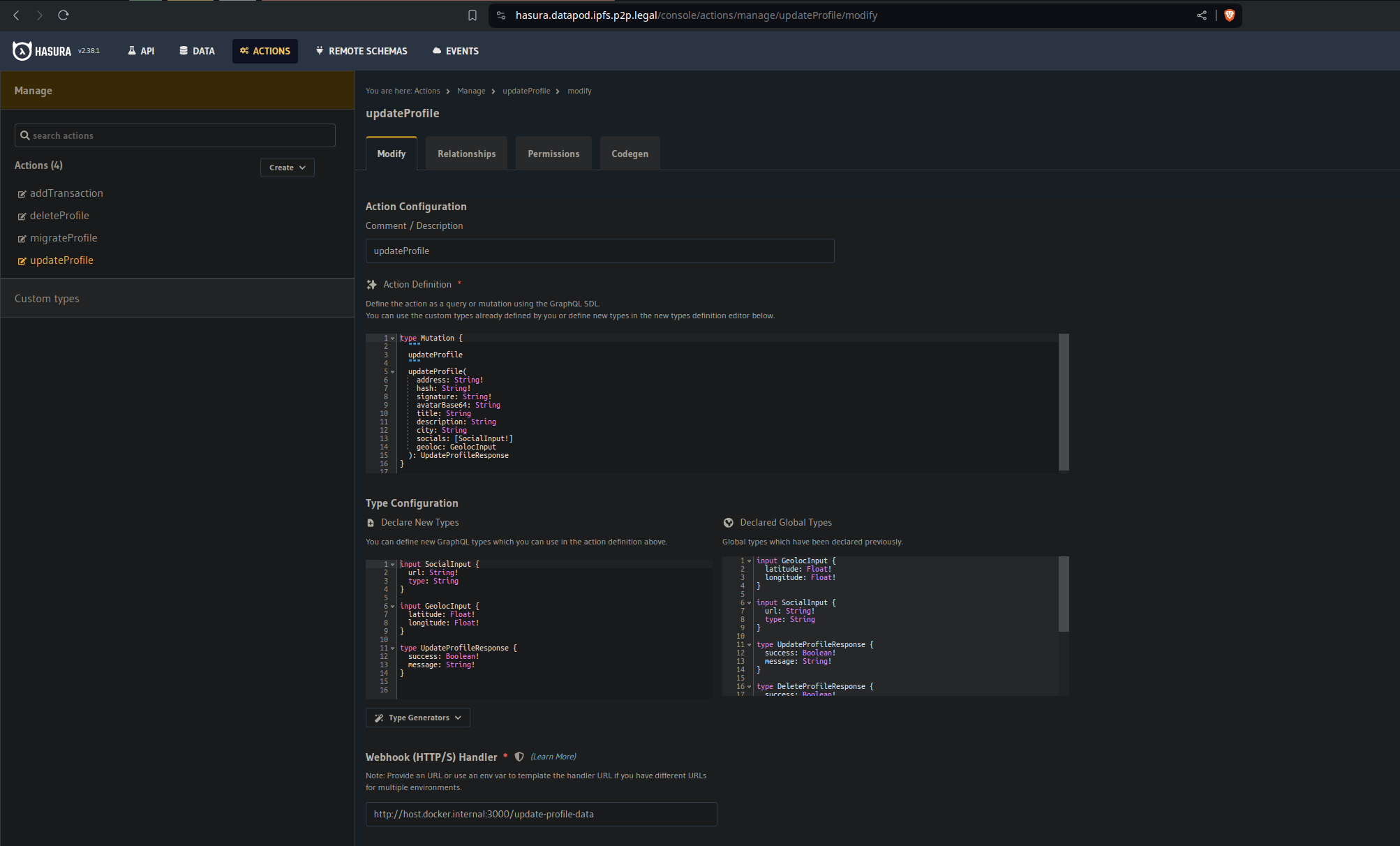
Je vois que tu as repris les actions Hasura que j’avais créé pour mon datapod: /console/actions/manage/updateProfile/modify
Je suppose que tu ne t’en sert plus ?
Penses-tu pouvoir ajouter des actions Hasura de manière à interfacer les requêtes HTTP POST de ton endpoint submit avec l’api graphql ? Ce serait vraiment bien de n’avoir qu’une seule API à gérer côté client pour les datapod.
Je pense que nous aurions besoin d’exemples précis de soumission de donnée via cette API, notamment sur si fait une mutation graphql
Incroyable boulo que tu fais là, ça annonce du lourd. Pour une fois ce n’est peut être pas moi qui va pouvoir tester cette API en premier pour debug, je risque de ne pas trop avoir de temps cette semaine (et j’avoue que après avoir implémenté Cs+ dans gecko, puis final rien, puis finalement mes datapod hasura/deno, puis finalement rien, je passe mon tour sur ce coup ci pour le moment ^^). Je m’en remet donc à @kimamila , mais aussi à chacun lisant ces lignes, lancez vous, testez cette API que ce soit en bash en python en Cobol, peu importe, posez des questions si vous ne savez pas comment faire, mais c’est nécessaire pour donner des retours à Hugo.
“n'a pas repris” ? Ce n’est pas facile de s’en servir puisque les données ne sont pas dans un format graphql, mais en blocs binaires ipld.
Oui, ce serait possible avec une implémentation côté serveur un peu plus sophistiquée. Je pense qu’il va falloir re-réfléchir à la question ensemble en visio.
C’est pour ça que j’ai fait une UI démo. Il faut comparer :
Oulah, j’ai enfin compris le premier message, ça m’a mis du temps !
Et d’ailleurs je me demande ce que tu signais dans ces mutations. Puisque si tu ne signes qu’une mutation et pas un document entier, on peut faire dire n’importe quoi. Par exemple :
Ah ok, donc c’est pas vraiment une mutation graphql qui va modifier une donnée existante, mais plutôt une opération que retransmet tout et écrase le document en entier. Pour moi l’intérêt d’une mutation graphql c’est que si tu veux modifier juste un champ, tu transmets juste ce champ.
Si tu veux modifier juste le titre, tu transmets une mutation sur le titre, mais tu signes le document complet (avec l’avatar), c’est bien ça ? Et donc le serveur pour vérifier si la signature du document est valide doit mettre à jour le titre dans sa version du document et vérifier la signature ? C’est l’idéal mais c’est quand même compliqué, surtout si on n’utilise pas de version standardisée du document. Mettons qu’on change seulement le titre, mais qu’on modifie l’ordre des champs dans la version qu’on signe (titre après champ). Comment le serveur va-t-il pouvoir reconstruire le document original ?
Je hash le document json avec les champs qu’il contient, quelques qu’il soient, je signe ce hash.
Le serveur reproduit le hash du document à partir des champs reçus. La seule contrainte est qu’en effet les champs doivent être dans le bon ordre attendu, ça doit juste être documenté.