With the Ğ1v1, the need for an off-chain storage mechanism appeared clearly for data like:
transaction comments
profile data (contact info, profil picture, …)
messaging
marketplaces (ğchange, airbnjune…)
The v1 approach was mixed and unsatisfying:
transaction comments went in the main blockchain
profile data and messaging went to Cesium+ pods with documentation and performance issues
Ğchange ads went to Ğchange pods (copy of C+ pods) with moderation issues in addition
airbnjune and other went to centralized services (lack of easy to use decentralized platform)
All of this came with a deteriorated user experience that we do not want to have in v2 ecosystem. The options for v2 datapods depend on the features we want, for example:
cost (in Ğ1?) for data storage depending on the size of the data
free storage without limits (spamming issues)
moderation (ability to whitelist / blacklist ads, conversations…)
When we finish typing and plugify de Indexer with @ManUtopiK , we will add Cs+ dump complete profiles, and mecanisme to check users signature and profiles updating.
This can be achieve same way for transactions comments (field already exist in indexer, and comments are here from py-g1-migrator).
I think it could be a good option for Ğ1v2 migration. Free, no quotas, centralized.
Then we could think of a better approach later?
V2S indexer then will be organisze by optionnals pluggins.
You can boot it only for blockchain indexing (v1 or v2 or both), or just for datapod, or both.
I also think that Indexers can do many things easily with rock solid (postgreSQL, node.js) and well known technologies (it means more devs and contributors).
Indexers has a tremendous power to deliver machine or human exploitable blockchain information.
So it is a good candidate to store more information, as a powerful complement to blockchain information.
It is centralized only for off-chain information, but (may be) this can be solved with a federation mechanism as a plugin (pub-sub or another protocol).
For a client software, it will be more simple to connect to only two API (RPC node and GraphQL indexer), sometimes on the same domain, as a strong couple of synchronized and trustful information.
It’s still necessary to protect against storage spam, at least by applying a quota to all accounts, a more restrictive quota to non-member accounts, and requiring that the account exists (i.e. satisfies existential deposit).
I think we should define a protocol, to allow data exchange between data Pods.
It could be better (and more safe) to have more than only one implementation.
I like the Idea to use events, to publish document updates, without the content !
Why not use the existing protocol of a Substrate blockchain? This way we can have the consensus on the documents without having to define our own wonky protocol. And this could benefit to other substrate projects which mean we can get contributions.
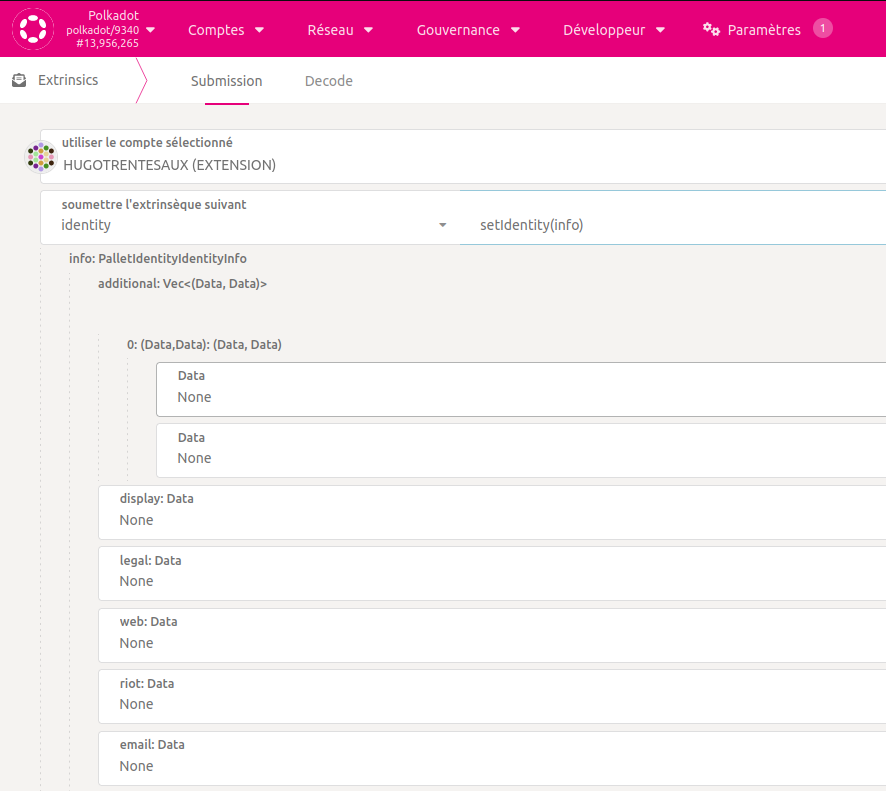
Yes we had a talk about events emitter on substrate with Hugo. We can use it to spawn user profile changes from special extrinsic, to send an event from blockchain, and listen this event on datapods (hasura indexer and Cs+).
So this extrinsic just have to spawn an event, nothing to store on onchain storage or nothing else.
Apparently, this mecanic already exist on Duniter v2s for some cases, but not use already if I understand.
Then all indexer kind will listen same blockchain events, and apply them as they want.
No need common protocol for datapod if the common protocol is just duniter customs extrinsics for profiles changes.