Merci ![]()
Les clients utiliseront l’api RPC pour tout ce qui est écriture dans la blockchain, et l’api graphQL des indexer pour tout ce qui est lecture. @elois a fait un schéma expliquant tout ça ici.
Hasura expose des subscriptions pour toutes les tables (qui ont un accès public) :
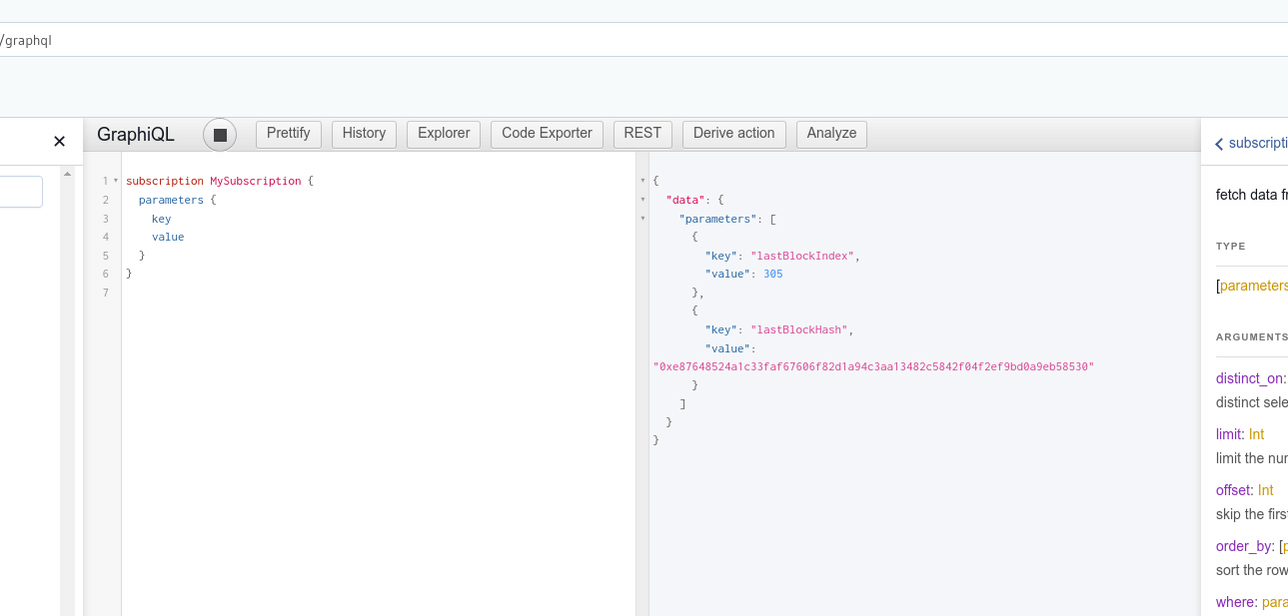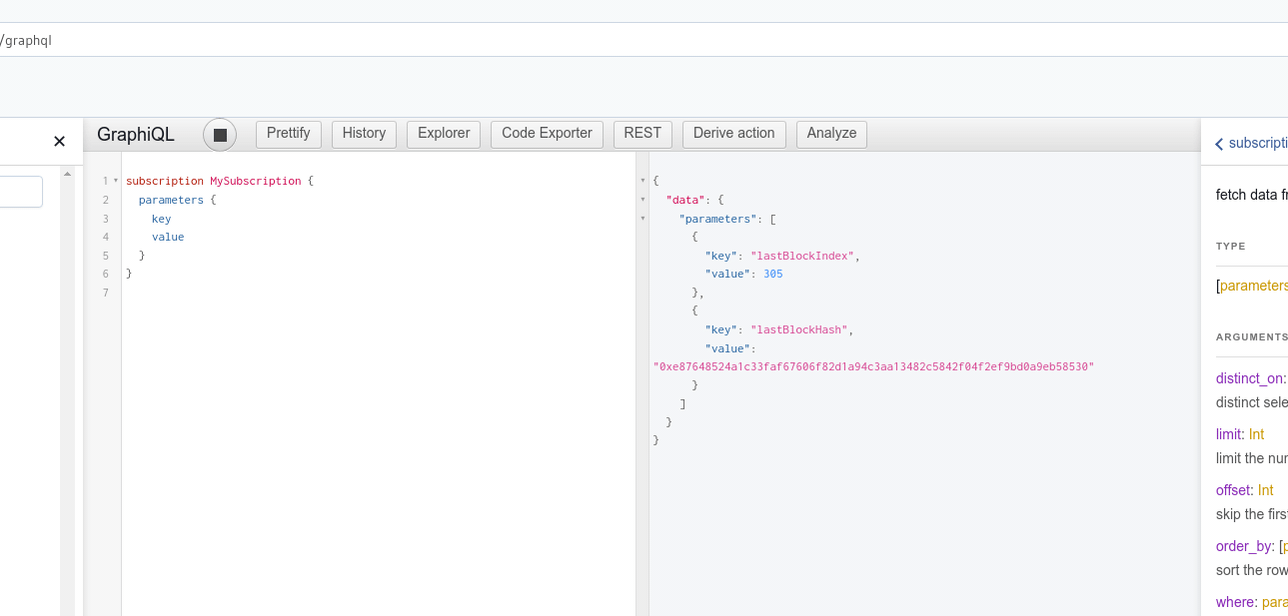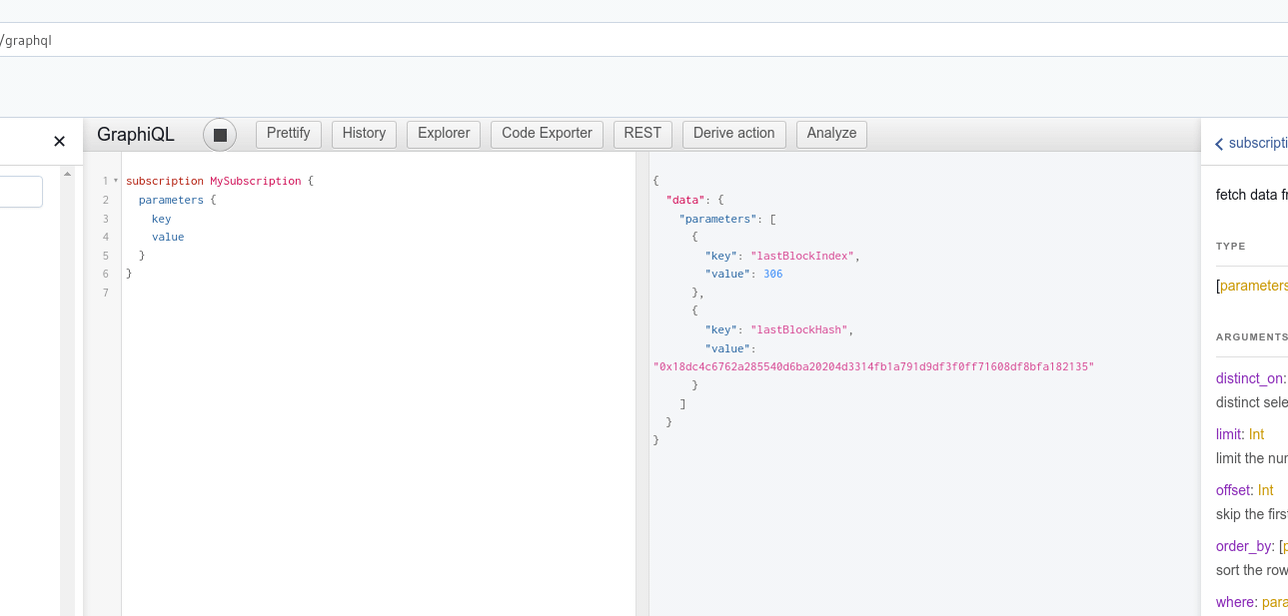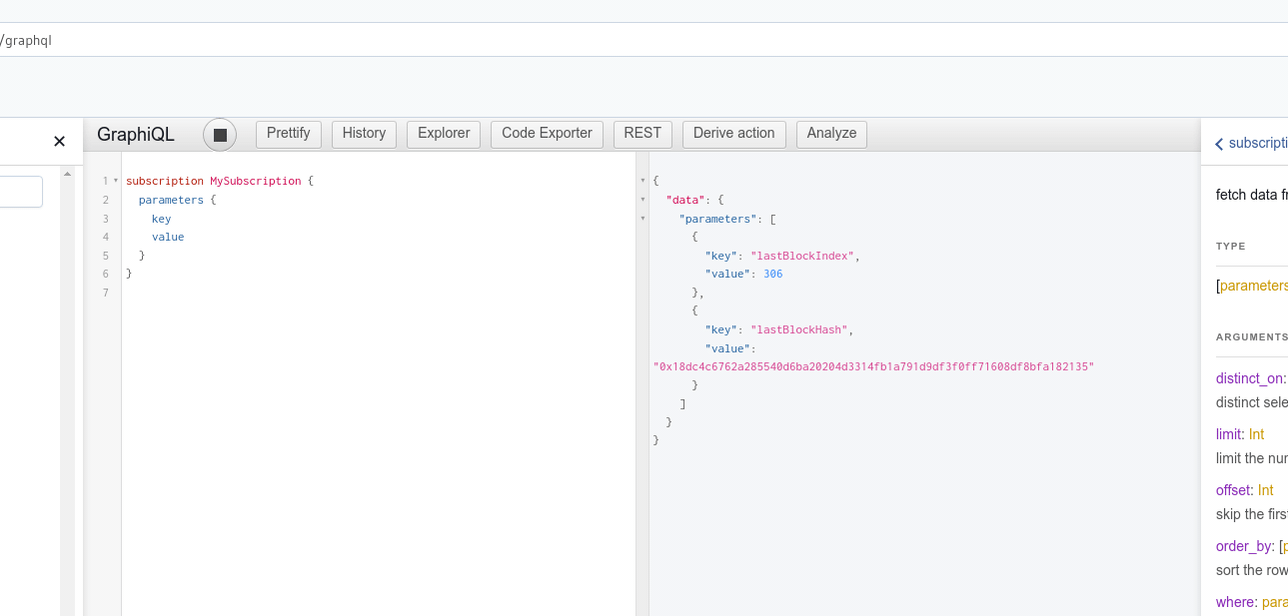
Il y a cet article qui explique comment ils tiennent 1 million de connexions !
Pour l’instant je n’index pas les blocs, je les décode pour extraire les extrinsics, lire les données et les charger dans la bdd. ETL quoi ![]()