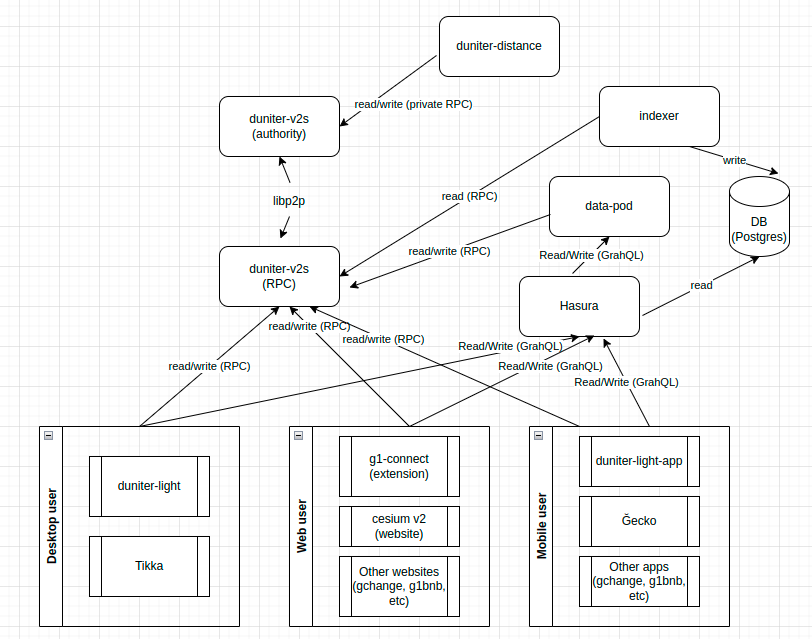
Le passage à la Ğ1v2 est l’occasion ou jamais de remettre à plat notre architecture technique générale.
Je propose ici l’architecture technique générale qui me semble être la plus pertinente, sachant qu’elle nécessite le développement de nombreuses briques techniques que je ne peux pas développer moi-même, une telle architecture ne pourra donc voir le jour que si vous êtes suffisamment nombreux à contribuer à sa concrétisation.
C’est une proposition d’architecture découpée en micro-services, je pense que c’est important pour plusieurs raisons:
Chaque micro-service est plus simple à développer, car son scope est limité.
Chaque micro-service peut avoir sa propre stack technique, ça permet d’avoir des contributeurs différents sur chaque micro-service.
Si un micro-service se retrouve abandonné, c’est plus simple à reprendre par d’autre, voir recoder de zéro, car c’est un “petit” projet.
Voici un schéma que je viens de faire sur draw.io:
La source du schéma au format xml: archi-g1v2 (2.6 KB)
Principe 1: limiter à 2 APIs pour les wallet/apps/websites: l’idée est d’utiliser Hasura pour fusionner 2 services (indexer et data-pod), au sein d’une même API. Je compte sur l’aide de @ManUtopiK là-dessus, et de tout autre personne qui maîtrise Hasura.
Principe 2: light client: duniter-light/g1-connect contiendra un smoldot embarqué et exposera une API RPC locale. L’idée est que les wallet/apps/websites puisse utiliser cette API RPC locale de la même façon qu’il utiliserait une API RPC “classique” d’un nœud duniter-v2s, donc pas besoin de développement spécifique coté wallets/apps. Les website en revanche, auront du dev spécifique à faire pour utiliser l’extension Ğ1-connect dès qu’ils ont besoin qui l’utilisateur signe quelque chose avec sa clé privée.
Principes 3: Des websites sécurisées grâce à l’extension ğ1-connect. L’idée est de faire en sorte que cesium et ğchange puisse redevenir des simples sites web, mais aussi que d’autre site web (g1bnb, g1covoit, etc) puisse facilement interagir avec la blockchain de manière sécurisée. Ainsi il n’y aurait plus besoin d’avoir une extension pour chaque service (ce qui était pour moi un mauvais design), mais une seule extension et des sites web pour chaque service (wallet, place de marché, g1bnb, g1covoit, et tout autre type de ğservice imaginable). Pour le développement de cette extension, je compte sur l’aide de @ManUtopiK, mais également d’autres contributeurs js j’espère, @1000i100 peut-être ?
Liste des micro-services
duniter-v2s: gère la blockchain, expose l’API RPC de subtrate, qui permet de lire l’état courant et de s’abonner aux changements d’état futurs (mais pas passés).
duniter-distance: programme qui évaluera la règle de distance et retournera le résultat à duniter-v2s, interaction avec duniter-v2s via l’api RPC privée d’un nœud forgeron. Je compte sur @tuxmain pour développer ce programme.
indexer: programme qui récupéré l’intégralité de chaque bloc via l’API RPC et qui indexe le contenu du block dans une base de données PostgresQL. Le but est uniquement d’organiser les données de manière à répondre aux besoins des wallets et autres outils (comme tracer l’historique des opérations sur un compte). J’avais proposé d’utiliser squid pour ça mais ça peut être aussi un truc qu’on développe nous-même, par exemple @gerard94 pourrait faire ça en Go, à discuter bien sur. Ce qui est certain c’est que je ne pourrais pas développer moi-même cette brique-là.
data-pod: brique technique la plus complexe, il s’agit d’abord de concevoir tout un protocole pour le stockage décentralisé des données hors-blockchain. Mais dans les grandes lignes, ce programme serait en charge de publier sur la blockchain les clés et hashs des données, afin de prouver leur authenticité et de se synchroniser avec les autres data-pod. Il serait également en charge de conserver un merkle tree complet afin de fournir les merkle proof aux walles/apps/websites qui le demande (nécessaire pour pouvoir vérifier l’authenticité d’une donnée). À noter que les données seraient stockées et servies d’une manière non-indexée, il faut avoir la clé de la valeur qu’on veut. En l’état je ne vois pas qui d’autre que moi pourrait développer cette partie, il faut d’abord rédiger le cahier des charges, qui sera très complexe (plus que pour tous les autres micro-services), et ensuite on verra si quelqu’un se sent de l’implémenté.
À noter que le contenu d’un bloc inclus les déclarations d’ajouts/modifications/suppressions de données au niveau des data-pod (uniquement les clés et les hashs des valeurs dont c’est léger),ce uqi permet à l’indexer d’indexer également certaines données des data-pod.
Hasura: le but est de configurer un serveur hasura qui expose la DB postgresQL et qui fusionne dans son API GraphQl, l’api du data-pod, afin de limiter le nombre d’API pour les wallet/apps/websites.
De mon côté je dois déjà m’occuper de duniter-v2s, et de duniter-light desktop et mobile, c’est déjà un boulot titanesque.
J’aimerais qu’on discute de cette proposition d’architecture lors des RML, en qu’on l’améliore ensemble Si on fait un travail collectif pour définir les différents cahiers des charges, ça va visibiliser les besoins en développements, ce qui est essentiel, car il y a développeurs qui cherchent à aider mais qui ne savent pas par où commencer ou qui n’ont pas conscience de quels sont les besoins
Y’a-t-il besoin d’écrire en blockchain pour prouver l’authenticité ? (spontanément je vois d’autres manières, du coup j’aimerais bien un exemple pour comprendre pourquoi ce choix)
Synchroniser, idem, il n’y a que certains contextes ou la blockchain est nécessaire, sinon le p2p gère ça aussi.
Enfin, si le data-pod est le plus complexe des services, n’y a t’il pas le risque de réinventer ipfs ?
Dans la même idée que la migration substrate, ne serait-il pas pertinant d’utiliser une techno comme ipfs avec une surcouche ou un service maison pour adapter à nos spécificités (comme la toile de confiance).
A-t-on dans la communauté des personnes qui se sont penchées sérieusement sur IPFS et qui sont capables d’en parler clairement ? (c’et peut-être ton cas @elois mais nous n’en avons que peu parlé)
Concevoir et faire fonctionner un système décentralisé à consensus global est très difficile, donc deux c’est encore pire.
On a déjà un système décentralisé à consensus global: la blockchain Ğ1. Il me semble idiot de ne pas l’utiliser et d’en créer un autre à côté.
Bien sur il existe des systèmes distribués sans consensus global, mais ils sont alors plus complexes pour l’utilisateur, car il ne voit pas les mêmes données selon d’où il regarde.
Pour moi l’un des besoins c’est justement qu’on voit les mêmes données d’où qu’on regarde, sinon ce n’est pas grand public.
“le p2p” ça n’existe pas, ce n’est pas une implémentation mais un concept. Justement on a déjà une implémentation p2p: substrate.
Non ça n’a rien à voir.
Arrêtez avec IPFS svp, IPFS est une usine à gaz qui fait beaucoup trop de choses dont on a pas besoin, qui vient notamment avec une couche réseau p2p qui ne nous sert à rien puisse qu’on a déjà une couche réseau p2p.
De plus, le consensus global strict apporté par la blockchain permet une synchronisation des données plus rapide que le consensus mou de IPFS, qui n’apporte pas vraiment un consensus global au sens strict.
Enfin utiliser IPFS nous forcerait à gérer 2 couches réseau p2p différentes avec des consensus différents, ce serait bien plus complexe à utiliser et à maintenir.
Aussi, je vois plusieurs avantages à utiliser notre blockchain pour la synchronisation, avantages qu’on aurait pas avec IPFS:
La possibilité de nommer des modérateurs via la gouvernance on-chain.
La possibilité de rémunérer les hébergeurs de pod et d’appliquer des frais/quotas aux utilisateurs en fonction de la taille de leurs données.
Comme dit plus haut, le fait d’avoir un consensus global strict sur l’état des données permettant une meilleure expérience utilisateur.
Moins d’activité réseau (donc plus écolo), car on réutilise une couche réseau déjà là plutôt que d’en ajouter une autre.
Permet une intégration native avec notre toile de confiance.
Ce sera probablement plus fluide d’en parler de vive voix si tu as d’autres choses à préparer d’ici aux RML16, ce qui me semble très probable.
La peur centrale que j’ai, c’est qu’en ayant un système de stockage de données décentralisé qui ne requière pas strictement une blockchain, mais pour qui c’est pratique d’en utiliser une, on encombre à la longue cette blockchain et qu’il devienne d’autant plus urgent de mettre en place des mécanismes permettant de n’avoir que la fin de la blockchain sur chaque nœud en raréfiant les archives devenant trop volumineuse, et donc en fragilisant leur intégrité. Peur commune avec les blocks de 6 secondes d’ailleurs.
Le fait que ce ne soit que des hash qui soit stocké en blockchain me rassure ceci dit.
Oui je suis très en retard, on en parlera de vive-voix
Substrate est déjà désigné de base de manière à ne pas avoir besoin de garder les anciens blocs. Par défaut, un nœud substrate ne va garder que les 256 derniers blocs finalisés, soit environ 30min de blockchain !
Je propose une version extrêmement simplifiée de ce schéma avec des couleurs. L’idée est d’en faire un support visuel si on doit expliquer la migration v2 à des profils non techniques.
Je n’ai pas encore intégré les data pods, parce que je n’ai pas encore de vision assez claire de leur fonctionnement. Je complèterai plus tard.
miroir (expose une API RPC à destination des clients)
archive (nœud miroir conservant tout l’historique du storage pour permettre l’accès à n’importe quel bloc)
les composants de l’indexeur (version simplifiée du schéma du readme)
les composants du client
Par rapport au client, il y a plein de possibilités :
se connecter à un light node ou à un noeud miroir de confiance
utiliser des bibliothèques métier pour faciliter la connexion aux API
avoir une architecture monolithique (appli mobile) ou modulaire (extension navigateur comme Ğ1-companion et UI sous forme de site/appli web)
Par la suite, j’aimerais détailler le schéma de chaque client (Ğcli, Ğecko, Tikka, Ğ1-companion…) pour montrer les différentes approches possibles. Pour l’instant l’idée est surtout de montrer l’utilité des différents rôles de Duniter.