En voyant passer un message disant que @ManUtopiK allait refaire un subsquid (la partie indexation seulement, l’api Graphql étant assurée par Hasura), je me suis rappelé de ce terme de ETL.
En fait, un indexeur (comme subsquid) c’est deux parties :
La partie extraction depuis une base de données Substrate, transformation, et chargement dans une base de données relationnel (c’est du ETL en fait)
L’API de requête sur la base de données d’arrivée
La première partie c’est la phase ETL :
Extraction des données de la base de données Subtrate (Extract)
Transformation des données (Transform)
Chargement des données dans la base de données relationnelle (Load)
Je pense qu’on peut jeter un œil sur ce genre de logiciels, maintenant bien rodés, qui adresse un problème connu depuis de nombreuses années. Si ça peut nous éviter des efforts.
Ah dommage. Comme il fonctionne en plugins, je pensais qu’on pouvait faire un plugin Substrate avec un flux de données (stream) en entrée.
Il faut qu’il puisse fonctionner en mode statique (blocs archivés) et en mode flux (stream) pour suivre les blocs effectivement. Et aussi vérifier la synchro entre les deux.
Il y a des subtilités pour un indexeur substrate qu’on risque de ne pas trouver dans un ETL classique, c’est la synchronisation entre la base de données en entrée et celle en sortie. Dans les premières versions de Talend, on parlait de migration de base de données, source vers sortie, mais pas vraiment de contrôle ou de maintient d’une synchronisation entre les deux.
L’idée c’est surtout de donner des idées à Manutopik.
J’ai utilisé Apache Camel (framework Java) ces 3 dernières années, alors oui il est possible de l’utiliser au sein d’un indexeur mais bon vu la complexité d’utilisation (il faut monter en compétences sur le framework, coût non négligeable, et le débugging est difficile) je ne le conseille pas.
Nous l’utilisions au sein de mon équipe principalement en mode discret, c’est-à-dire plusieurs fois par jour à des horaires précis pour livrer du contenu à un client. Mais il est tout à fait possible de l’utiliser en mode continu, aucun problème.
Question toute bête sur l’indexer à venir:
Si l’indexer commence au bloc 20 000, tous les événements qui se sont produits avant le bloc 20 000 sont perdus à jamais ?
Si l’indexer est down pendant 4 heures, tous les événements déroulés pendants ces 4h sont perdus à jamais ?
Non, j’enregistre l’index du dernier bloc traité.
Au démarrage, j’index depuis le bloc 0.
Si le server est down et repart 4h après, je repart depuis le dernier index traité.
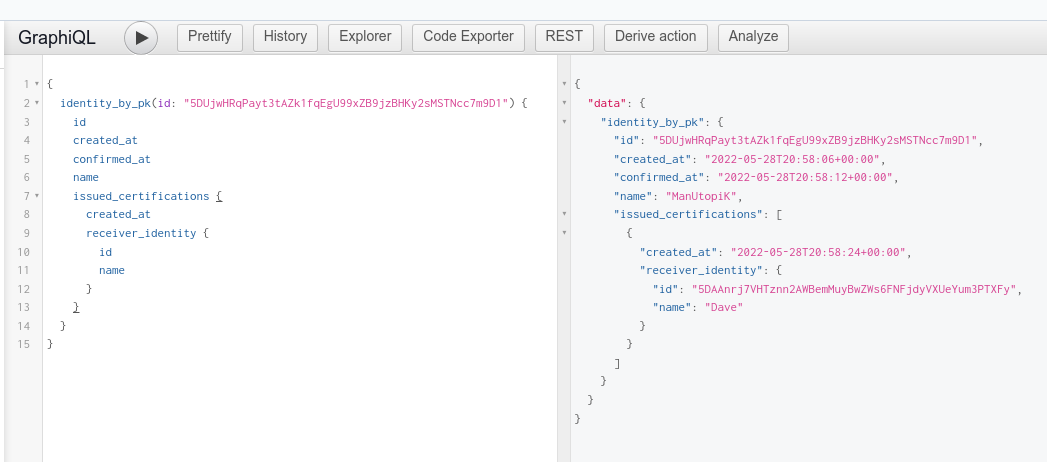
Ça fonctionne avec ma blockchain locale que je créé manuellement bloc par bloc, et j’enregistre les identités et certifications :
Par contre, j’ai testé avec gdev et je n’arrive pas à obtenir les anciens blocs : UnknownBlock, State already discarded for BlockId::Hash, 0x83ab84588a2d6f26138b451cf3f437364edcf59e18e5915331e3c3d3a3795230
Je pense pouvoir répondre : c’est parce que ton nœud est « juste » un Full Node, il faudrait que tu le lances avec l’option --pruning archive (en supprimant la BDD avant avec une commande purge-chain au préalable).
Ah mais oui. J’essayais directement avec le ws d’éloïs. N’importe quoi. Il faut que je tape sur mon noeud qui est en mode miroir. Je retente et je vais essayer avec ton option.
Merci !
En fait, les clients ont juste besoin d’une API type BMA (en terme de contenu) et GraphQL (pour la forme).
Ensuite, n’importe quel outil pourra se synchroniser dessus, retriturer les données, etc.
@ManUtopiK est-ce que des websocket permettront de s’abonner à un flux ?
Est-ce que les blocs seront dispo en juin,cavec toutes les données du bloc, quelque part ?
Et enfin, as tu moyen de publier un accès à ton indexeur, même si tu fais des raz souvent. C’est pour qu’on puisse tester au fur et à mesure, en mode PoC.
Merci
Les clients utiliseront l’api RPC pour tout ce qui est écriture dans la blockchain, et l’api graphQL des indexer pour tout ce qui est lecture. @elois a fait un schéma expliquant tout ça ici.
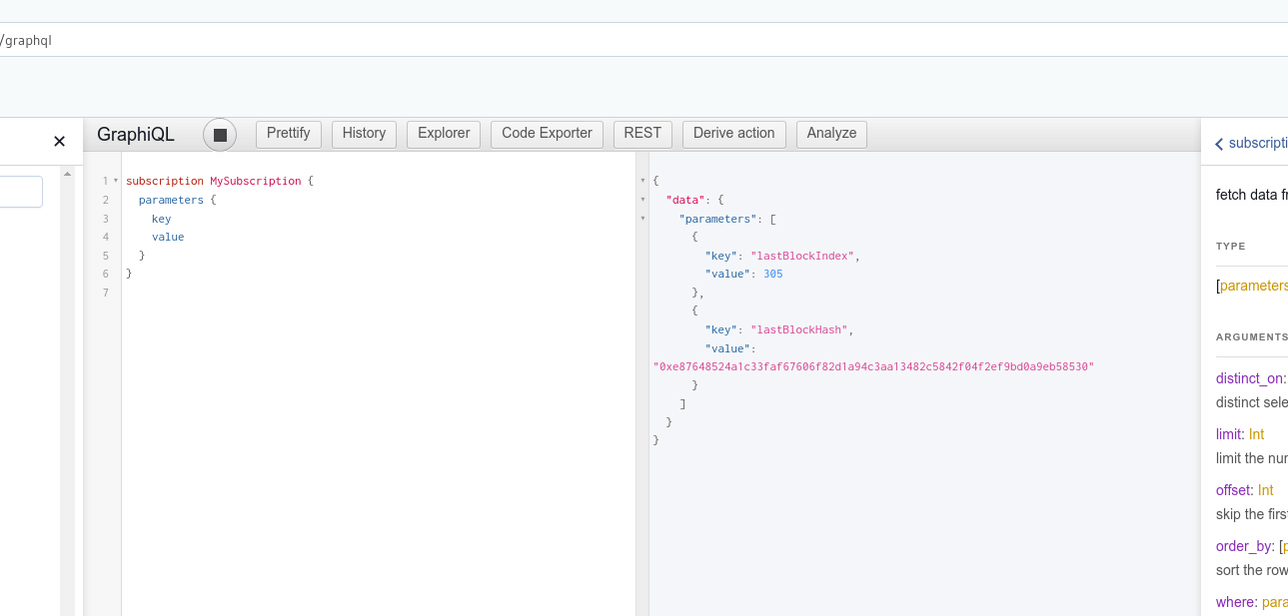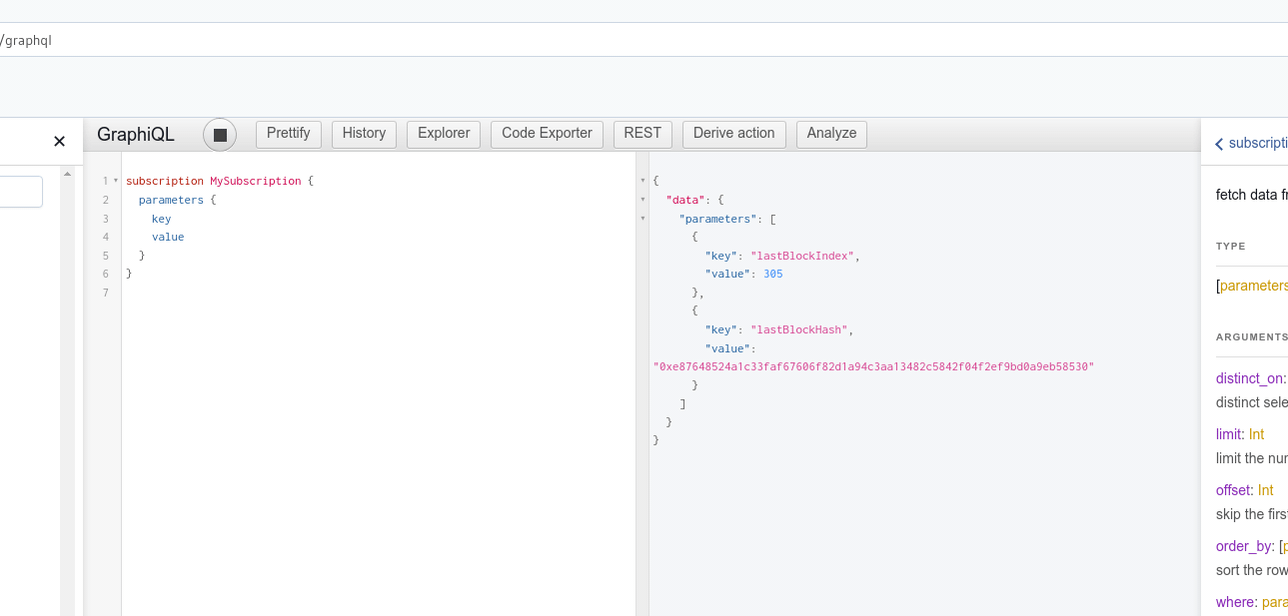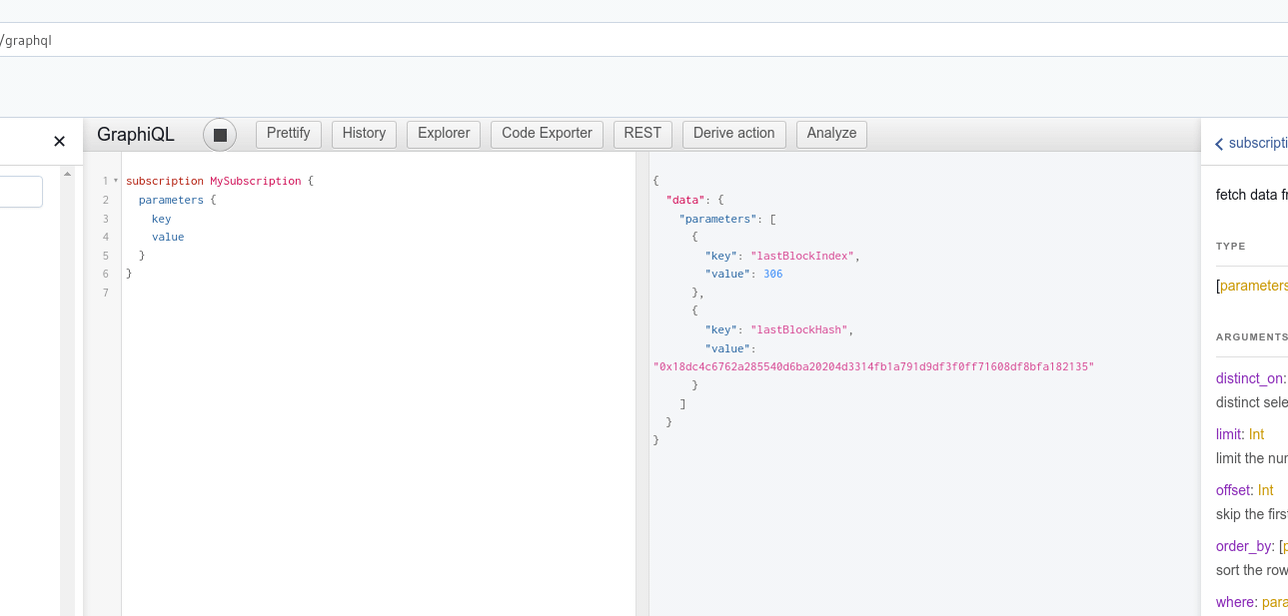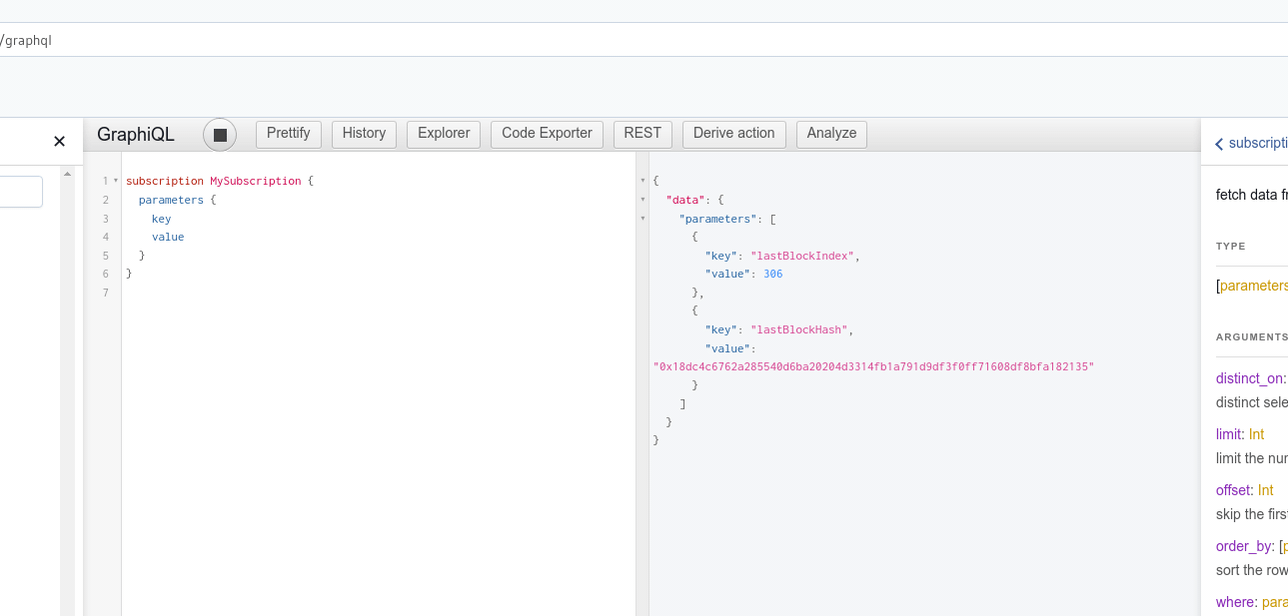
Hasura expose des subscriptions pour toutes les tables (qui ont un accès public) :
Il y a cet article qui explique comment ils tiennent 1 million de connexions !
Pour l’instant je n’index pas les blocs, je les décode pour extraire les extrinsics, lire les données et les charger dans la bdd. ETL quoi
Pour la continuité des outils de la G1, je réfléchis à produire des blocs JSON proches de Duniter v1.
Penses tu qu’ajouter ce format en sortie de l’API soit possible ?
Évidemment les hash ne seraient plus bons, mais on pourrait imaginer que l’indexeur les recalcule et les signe avec sa propre clef (en as t’il une ?).
Ainsi, il agirait comme une autorité de confiance, donnant accès aux blocs.
Il n’y aurait pas de hash du précédent bloc non plus. A moins de simplement recopié ceux de Substrate, et les signatures, même si les client de cette API ne pourrait pas le vérifier.
Du style de ce format : https://g1.cgeek.fr/blockchain/block/530491 ?
En théorie c’est possible car il est possible de créer des “vue” en postgresql permettant d’aggréger des données de plusieurs tables. Hasura créé automatiquement les queries graphql pour ces vues.
Après je ne sais pas du tout si c’est pertinent et possible avec substrate…
Je propose une autre solution qui me parait plus simple à réaliser: remplir la DB postgresQL avec les données passées de la Ğ1, avec dex je peux faire ça, j’extrais la DB de duniter v1 en une fois et j’écris le tout dans la nouvelle DB. Une sorte d’ETL qui ne servira qu’une fois en prod, mais faut d’abord maturer le schema de la DB postgres