Je découvre dans les primitives substrate les interfaces TransactionIndex “Interface that provides transaction indexing API.” et OffchainIndex “Interface that provides functions to access the Offchain DB.”. On dirait un angle mort de ma compréhension de substrate qui permettrait de demander des choses au client substrate non obligatoires car hors du storage on-chain. Peut-être qu’on pourrait les utiliser pour interfacer proprement les actions onchain et offchain. → c’est tout ce qui concerne les offchain workers (ocw), mais en terme d’architecture, si la blockchain n’utilise jamais ces données, ça n’est pas utile de passer par ça, et plus simple de développer une autre stack déconnectée comme les datapods.
Voici le call store de la pallet remark :
#[pallet::call_index(0)]
#[pallet::weight(T::WeightInfo::store(remark.len() as u32))]
pub fn store(origin: OriginFor<T>, remark: Vec<u8>) -> DispatchResultWithPostInfo {
ensure!(!remark.is_empty(), Error::<T>::Empty);
let sender = ensure_signed(origin)?;
let content_hash = sp_io::hashing::blake2_256(&remark);
let extrinsic_index = <frame_system::Pallet<T>>::extrinsic_index()
.ok_or_else(|| Error::<T>::BadContext)?;
sp_io::transaction_index::index(extrinsic_index, remark.len() as u32, content_hash);
Self::deposit_event(Event::Stored {
sender,
content_hash: content_hash.into(),
});
Ok(().into())
}
Si je comprends bien :
extrinsic_index permet de référencer précisément l’extrinsic commenté avec remark (donc par exemple le batch qui contient remark et des transfers)sp_io::transaction_index::index() est utilisé pour stocker le content_hash dans le stockage offchain (par contre je ne vois pas les cas d’usage)
Ce serait plus souple de forker remark pour plus de comptabilité avec le CID IPFS, et peut-être plus simple d’utiliser un wrapper plutôt que de reposer sur batch dont le sens est moins précis.
Mais dans un premier temps on pourrait se contenter d’utiliser batch et remark pour éviter de développer une nouvelle pallet. Mais comme seul un hash blake2_256 est publié, il faudrait le convertir en CID hors chaîne (ajouter multibase et multicodec).
Si on se contente de ça, on a déjà ce qu’il nous faut dans le runtime :
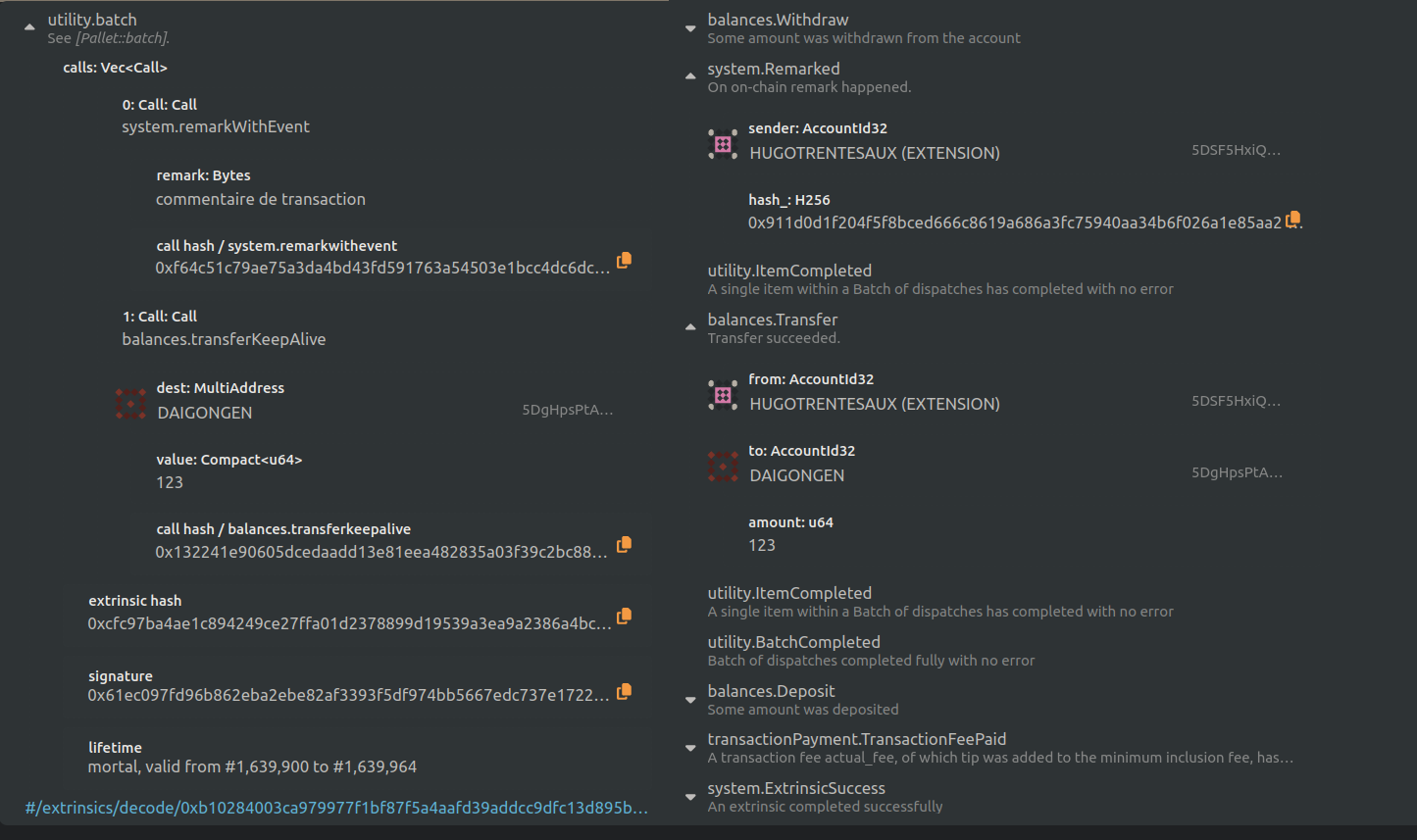
cf le bloc 1639903 où je fais un batch avec un commentaire de transaction :
Voici mon extrinsic :
- utility.batch
- system.remarkWithEvent(“commentaire de transaction”)
- balances.transferKeepAlive(Daigongen, 123)
Et je peux remplacer “commentaire de transaction” par un CID si je veux pouvoir demander la suppression de mon commentaire, ou juste utiliser moins de ressources blockchain pour un long message chiffré qui ne concerne de toute façon que moi ou mon destinataire.
L’événement publié est un hash blake2_256 : 0x911d0d1f204f5f8bced666c8619a686a3fc75940aa34b6f026a1e85aa2fe5ee0 qui correspond au hash de mon commentaire de transaction.
J’ai fait un deuxième commentaire pour faciliter l’ajout sur IPFS en utilisant un fichier qui finit par 0x0a : 1640537.
On voit que le hash est 0xfcbbe2e60bee2b1b0b7429997993d7e486df936c3b7d841f1ed5b932003cdc23. C’est un hash blake two 256.
On peut le convertir en CID comme ça :
import { CID } from 'multiformats/cid'
import * as multihash from 'multiformats/hashes/digest'
import { blake2b256 } from '@multiformats/blake2/blake2b'
const comment = 'commentaire de transaction' + String.fromCharCode(0x0a)
const commentBytes = Buffer.from(comment, 'ascii')
const commentHash = await blake2b256.encode(commentBytes)
const commentHashHex = Buffer.from(commentHash).toString('hex')
console.log(commentHashHex)
const hexHash = commentHashHex
const hashBytes = Buffer.from(hexHash, 'hex')
const mh = multihash.create(blake2b256.code, hashBytes)
const cid = CID.createV1(0x55, mh)
console.log(cid.toString())
On obtient bien le même hash, et le CID suivant : bafk2bzaced6lxyxgbpxcwgyloquzs6mt27sinx4tnq5x3ba7d3k3smqahtocg.
On peut donc retrouver le commentaire de transaction sur une passerelle IPFS :
 https://bafk2bzaced6lxyxgbpxcwgyloquzs6mt27sinx4tnq5x3ba7d3k3smqahtocg.ipfs.pagu.re/
https://bafk2bzaced6lxyxgbpxcwgyloquzs6mt27sinx4tnq5x3ba7d3k3smqahtocg.ipfs.pagu.re/
En faisant ça, le message est inscrit en blockchain pour toujours. Mais si au lieu d’un commentaire de transaction on met un CID, on peut ensuite faire disparaître la donnée. Ce serait quand même plus confortable de :
- préciser si le commentaire de transaction doit être interprété comme une donnée brute ou comme un CID (ou autre chose si on veut dans le futur). L’événement pourrait alors contenir soit le hash de la donnée brute, soit le CID directement.
- wrapper le call à commenter dans le commentateur plutôt que d’avoir recours à un batch
Mais pour éviter de prendre du retard, je vais déjà tenter une implémentation complète sur ce schéma, c’est-à-dire :
- dans duniter-squid pour collecter les hash annoncés et les convertir en CID pour graphql
- dans ddd-ui pour soumettre un commentaire de transaction sur IPFS en même temps qu’un transfert sur Duniter