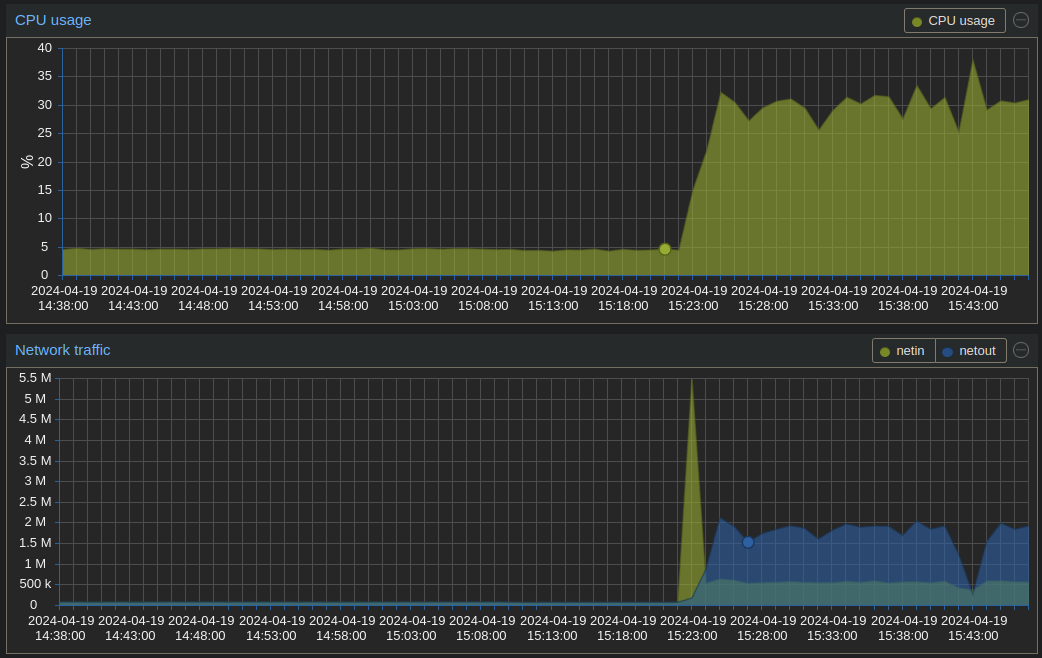
C’est tout frais, mais j’ai un nœud de datapod en prod qui a commencé à récupérer des données de mon nœud local et à indexer le contenu.
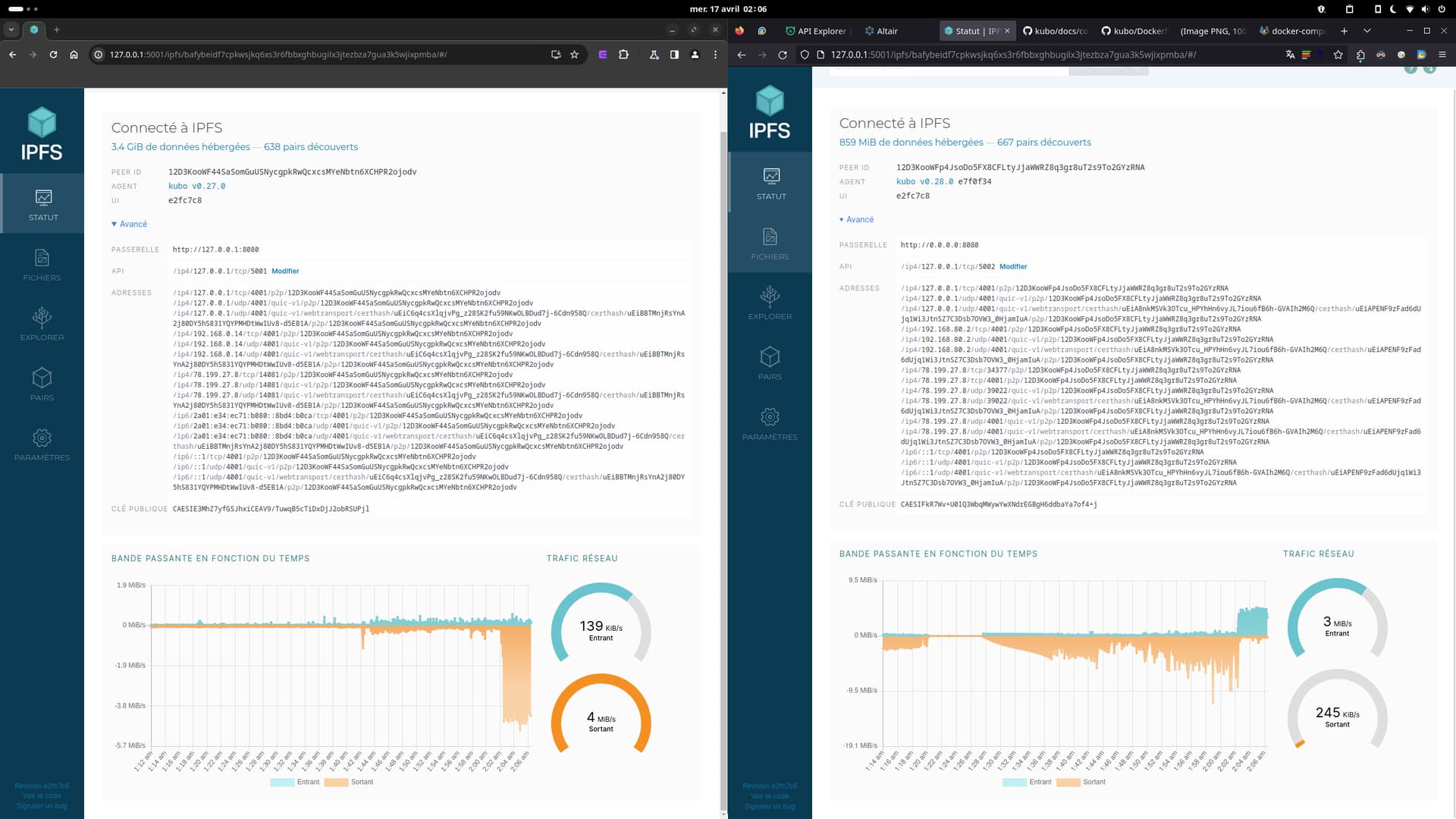
on voit à gauche le nœud “donneur” dont le traffic sortant augmente significativement avec la synchronisation et à droite le nœud “receveur” qui commence à faire rentrer les données
On peut faire la requête GraphQL suivante :
query LatestProfiles {
profiles(limit: 5, order_by: {time: desc}) {
index_request_cid
data_cid
pubkey
time
title
description
avatar
city
geoloc
socials
}
}
à l’adresse https://datapod.coinduf.eu/v1/graphql
Et cela donne la réponse :
{
"data": {
"profiles": [
{
"index_request_cid": "bafyreianxc6usy7r3j3moitp3lem7yabmqem24gziqbaherrwhcipyfluy",
"data_cid": "bafyreicrpavcfyx73cj645ys4wwmhzxjop73vfucpf7jk5kljnzjiqeqeq",
"pubkey": "91CgQG33EbJrnxQsxyqazJyrGubkDQTiJrgsDikqWLRe",
"time": "2020-05-03T16:17:00+00:00",
"title": "Fanch PERICAULT",
"description": "",
"avatar": "QmZikBMsVYUKnAB9VL3aF8TFAp8kDCQ5thTjbuWvghQzjP",
"city": "Mérifons, 34800",
"geoloc": "(43.6348588,3.2859861)",
"socials": null
},
...
Donc le nœud est en train de synchroniser (IPFS) et indexer (SQL) les données de 2020. Pour l’instant je n’ai pas fait l’optimisation de l’indexation par batch, il y a donc une requête SQL par profil, ce qui prend ~20 minutes pour tout indexer si je me souviens bien.
On peut visualiser le root node dans la passerelle publique : /ipfs/bafyreidhw7r3dmr3vno4i4ox4heb677xher42xci5kzkpsrx47tnenqldm/
et descendre l’arborescence jusqu’au premier profil Cesium + : /ipfs/bafyreif5fjgb3qgywmhjbgaf7ojieowjdvp3w624xzqrssp5y2egrm6exm/
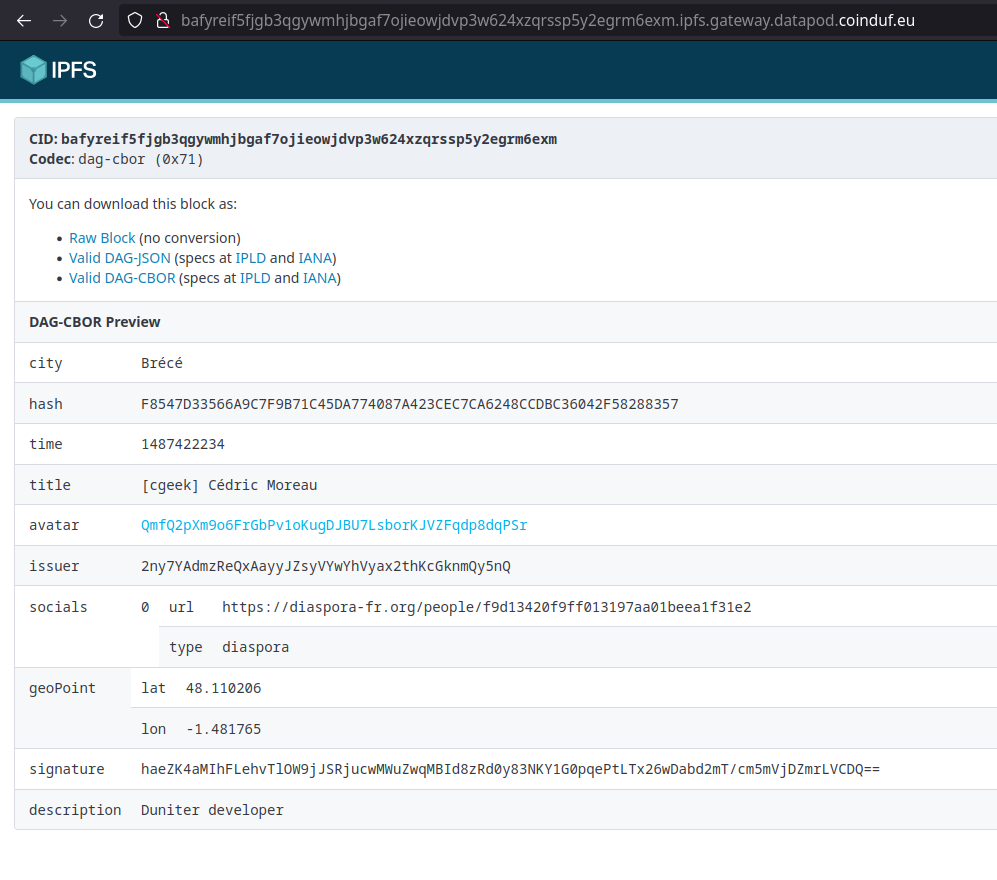
Et l’avatar associé : https://gateway.datapod.coinduf.eu/ipfs/QmfQ2pXm9o6FrGbPv1oKugDJBU7LsborKJVZFqdp8dqPSr
L’objectif de ma fin de semaine sera de stabiliser tout ça, mais pour les plus curieux, voici à quoi ressemble le docker-compose.yml de prod que j’ai utilisé.