Actually we can work with 32 bits integers, so you can divide memory consumption by 2.
But since we need to also have the original WoT to travel across it, actually you can multiply by 2.
So yes, 100MB for 1.000.000 people, that’s good ![]()
Actually we can work with 32 bits integers, so you can divide memory consumption by 2.
But since we need to also have the original WoT to travel across it, actually you can multiply by 2.
So yes, 100MB for 1.000.000 people, that’s good ![]()
I’ve made some tests with C++.
In a WoT of 1.000.000 members with an average of 16 links per member, testing that someone reachs all the members takes about 20ms in the worst case (where no path exists).
So in a naive test it would cost max $20 \times 1.000.000 = 5,5$ hours to make the test of a member against the WoT. Complexity would be $O(n^2)$.
In a smarter test, like @Arcurus mentioned, we do not repeat the process of testing the member against each member but remember the reached members instead (or the boolean ‘success’). So the complexity is roughly $O(n)$. This takes more RAM ($4 \times N$ bytes, so 4MB RAM in our test).
In such case, testing the member against the whole WoT takes between $40$ and $60$ ms on my laptop, so let’s consider 100 ms for our example.
Considering members have to renew every 6 months, this makes 2 million tests over a year. I do not consider new borns (which represent 2% a year) because they are included in the 2 millions since 2% also die each year.
Given our target of 10min/block, this makes 52596 blocks / year, so 2 million tests on these 52596 blocks gives approx. 38 WoT tests / block, so $38 \times 100 = 3,8$ seconds per block.
That’s a great news 
I have to say these measurements are made in optimal conditions, because my arrays are well represented so I don’t need any extra sort/find on them, and this will depend on a preceding work on uCoin side to represent its data. But that’s possible, without any doubt.
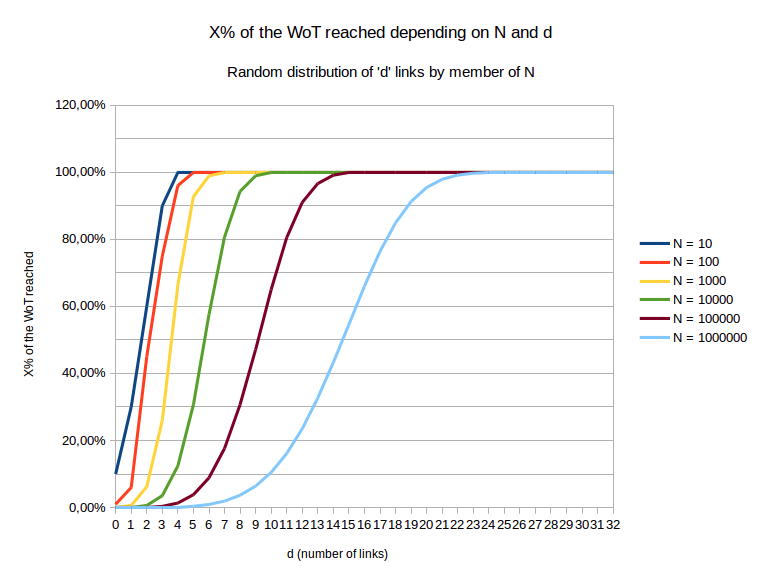
Fun fact linked with my statistical distance rule: in my tests, certifications are randomly issued but with exactly 16 certs per member. In the end of my test, I finally see that a member only reach 66% of the WoT under these conditions. 
Will you develop the wot processing as a dynamic library ? I guess JavaScript can be quite slow compared to C.
is in your example the O(n^2) algorithm faster as the O(n) algorithm for 1.000.000 Members?
but so or so, the complexity should be manageable ![]()
is java script in our times compiled? if so how fast it is compared to c?
practically if you really check the identity of someone you must be in contact with this person (personal known, meeting, at worst video chat…).
→ therefore the effort the check the identity both way is nearly the same as checking it one way if you do it properly.
also it seems to be logic, that real trust is always both way. so no, there would be no two meaning, there is just one meaning, that is trust, which is both way.
I don’t see why trust should always be reciprocal. Reciprocal trust will be stronger than unilateral trust because we would have two paths instead of one anyway. Perhaps we could give more weight to reciprocal trust without making it mandatory?
Counting only reciprocal trust might even increase the risk as it strenghtens the need for reciprocity. Reciprocity and trust are linked constructs, but they can have different determinants.
Let’s say a stranger certifies you. If only reciprocal trust links are counted for the WoT, you might feel a stronger need to trust back, although you might not have trusted this stranger if reciprocity was not mandatory for WoT.
In this situation, we have not increase the trustworthiness of the trustee, but we have artificially increased trust propensity by giving extra incentives for reciprocity. This is why I think that counting only reciprocal certifications in the WoT will not improve the trustworthiness of members but only their trust propensity. However, I do agree that reciprocal trust relationships might be good indicators of trustworthiness.
Trustworthiness have other determinants that are not captured by reciprocity: might the trustee be technically able to cheat the system by creating duplicate accounts? Has the trustee enough integrity to not cheat the system? Has the trustee an intrinsic desire to do good? Reciprocity has nothing to do with these criteria.
Although these criteria can also be influenced by social mechanisms (such as the “similar-to-me effect”, social identification etc…), I think trust propensity is even more so. Trust propensity is not only dispositional (e.g. personality) but also strongly influenced by social mechanisms (e.g. I don’t know this person but he is a friend of a friend so I will trust him more).
My 2 cents from a psychological perspective…
Here is a good review paper on the topic.
Sorry but I can’t follow the rest of the discussion because it’s going too much in the mathematical domain and I have to refresh my knowledge a bit. But I think the main goal of the system is to detect individuals in the lower right quadrant of this paper p.14 (1003) : low trust/high distrust. The high trust/high distrust quadrant is sorted out by the recertification mechanism (not re-issuing the certification). There might also be risk in the low trust/low distrust quadrant when people certify friends of friends or others they don’t really know but feel obliged to trust.
3rd edit (is there a badge for this??): I think the WoT is limited by the fact that blockchain makes all relationships public. I can see who certified me and who didn’t. I can ask those who didn’t why they didn’t, therefore putting pressure on them to certify me back although I might not be trustworthy. It is like doing a trust game but telling out loud to the other participant that we trust him or not instead of keeping it in one’s head.
This problem is exemplified in the TV show “split or steal”: https://www.youtube.com/watch?v=p3Uos2fzIJ0
Yes, this Node.js addons. I write C/C++ code, and call it like normal JS code. I already use it for PoW, signatures and sig verification in uCoin. The module is called naclb.
The O(n) is faster than the O(n^2), it takes respectively ~50 ms and 5,5 hours to process.
Looking at IO: writing 128MB file takes ~$150$ms on my laptop (SSHD), reading is about 130 ms.
This is pure C++, no JS at all.
Also, I think @scith completely summed up my thinking about 2 ways certifications.
@cgeek is there any conclusion yet how you want to proceed with the WoT rules?
to sum up:
scalability seems not to be a big problem so we can focus on the problem with the WoT itself.
At this moment I would prefer a clear rule like you need X% of the sentries then to have some statistical stuff that is more difficult to understand.
I think we will just use the X%.
But now I plan the following:
sigWoT parameter (the threshold to be considered a sentry) will be replaced by some formula (likely to be $d_{min}$ formula above, with a little tweak) to have a value adapted to the size of the WoT.I still need the find this little “tweak” and publish results here, I will do it tomorrow (only 2 graphs, easy, don’t worry).
So yes, we move on.
I’ve made some simulations and put the results in a LibreOffice Calc: Statisitcal_distance_simulations.ods (52.3 KB)
We can see the X% reached in the WoT for a given member, depending on d the average number of links per member and N the size of the WoT:
Few comments:
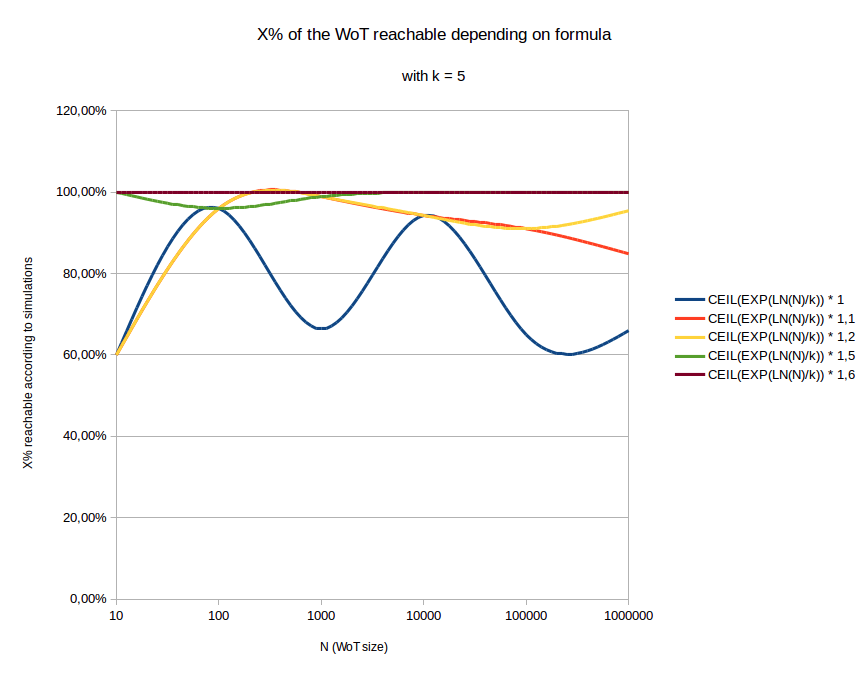
So I’ve taken back my d_{min} = \exp{(\frac{\ln{(N)}}{k})} function, and see what simulation case it matches:
Comments:
CEIL function to match my simulation results, which use discrete values d = 0..32The lower p the better here: because this allow more members to be part of the distance rule by being sentries.
If I had to choose p value right now, I would choose p = 1.2.
But maybe we can find a better function than \exp{(\frac{\ln{(N)}}{k})}.
For now, I will develop uCoin based on this conclusions: we have to choose parameters for %X and p.
sorry, i got lost with the second graph. what is $p all about?
why not use a certain Y% of min sentries to reach with your outgoing certification to be a sentry?
This would be easy to understand.
just saw that… that means if I certified someone I can only renew the certification after 5 years?
Why?
p is just an adjustement coefficient, a proportionnal adjustement like you can find in PID.
You can see in the 2nd graph it has successively values p = 1, p = 1.1, p = 1.2, p = 1.5, p = 1.6. Because I know the formula without p (or with p = 1, which is the same) is not enough to have a sentry reaching enough of the WoT.
What I am proposing is how to define a sentry: it would be defined by the fact it has issued at least [formula] certifications instead of just [constant] certifications.
And obviously we can have this formula being p \times d_{min}, with p = 1.2 would be enough.[quote=“Arcurus, post:30, topic:668”]
just saw that… that means if I certified someone I can only renew the certification after 5 years?Why?
[/quote]
This is just security: you have to be certified by other people. Otherwise its too easy to cheat on the long run, isn’t it?
why?
im not sure if this will bring really more security. time will show.
This is the blue curve: it oscillates between 60% and 95%. This means someone will be considered a sentry even if statistically he cannot reach more than this percent of the WoT. This woud be blocking for newcomers, even with the X% rule.
sorry, im little bit confused. how can it oscillate between 60% and 95% if the x% rule requires for example to reach 3/4 = 75% of the sentries?
if he percent to join is below or the same as this x% it should be at all times still possible to join or?
lets say you become a sentry if you reach 3/4 of the other sentries. and you can join if 2/3 of the sentries reach you.
then it is not only statistically proofed, that it is to all time possible to join, it is per rule proofed.
so what is the benefit to have an statistical proof? which is no proof at all…
This sentence is a non-sense: you try to define sentry concept based on sentry concept. It does not work!
What I am trying to do since post#28, which is something different than my post#1 however linked by some formula, is to change the rule on how is a sentry defined.
Because we previously defined sentry (actually this is the current meta_brouzouf rule) saying “a sentry is a member who currently has at least 3 certifications from him”. You can replace 3 by any constant.
But this is a problem, because it doesn’t have the same meaning to be a sentry with 3 certifications in a WoT of 20 members than in a WoT of 100.000 members. We have to make this 3 a dynamic variable, and this is where my d_{min} \times p comes in.
This does not change the fact that we will have the X% rule, which will be based on the sentries. But we have to define what is a sentry first.
Is it what was confusing?
ok, so why not simply define a sentry as one which outgoing certifications reach Y% lets say 3/4 of the members in k steps?
Because it is way easier to define a sentry being “a member who has at least Y(N) certifications”, both computationaly and humanly.
You don’t really bother of the Y function as a human, you just want to remember the values which are:
N Y(N)
10 2
100 4
1000 6
10000 8
100000 12
1000000 20
This is super easy to understand.
lol, yea much better then graphs ![]()
It would be great if someone could formalize on ucoin wiki the new distance rule proposed by cgeek. He already has so much work to do that this could be great if this was done by someone else ! 
yea would be great, but lets first wait for @cgeek to define it finally.
the X% rule for distance is easy to explain, the forumla I am not sure, maybe good to use a picture similar to cgeeks last post once it is set…
buy the way, haven’t found any description of the old rules either in the wiki, maybe because they have been self explainable up to now?