J’ai passé un peu de temps à relire la doc de IPFS, Filecoin, et à réfléchir à la question. Je ne veux pas me lancer dans la conception et encore moins l’implémentation d’un système de stockage de données hors chaîne pour l’instant, mais je ne veux pas non plus me lancer dans une solution centralisée (V2s-datapod: Hasura with Deno middleware to store profiles) sans avoir pris le temps de prendre un peu de recul sur le sujet.
Il est évident que le DU et la toile de confiance nécessitent un consensus et méritent une blockchain, et Duniter v2 répond très bien à ce problème. Par contre, pour ce qui est des commentaires de transactions, des informations de profil, des annonces de vente, des messageries… Tout ça ne peut pas faire consensus pour différentes raisons :
- on peut ne pas tolérer sur sa machine d’héberger du contenu indésirable (malwares, trafic d’armes, trafic d’humains…) ni l’imposer à des gens qui ne souhaiteraient pas être dans l’illégalité
- on ne souhaite pas conditionner le stockage de données aux seules comptes connus et validés par des membres de la toile de confiance, c’est trop restrictif
- il est sain de permettre les désaccords sur les données, même si elles viennent de membres de la toile
On doit donc avoir un système sans consensus et qui permette le fork, tout en garantissant quand même un bon niveau d’utilisabilité. L’approche des datapods Cesium+ est intéressante, mais comme on le voit sur https://ginspecte.mithril.re/, il existe une différence importante entre le nombre de documents présents sur chacune des instances, sans qu’on ait de bonne explication de pourquoi :
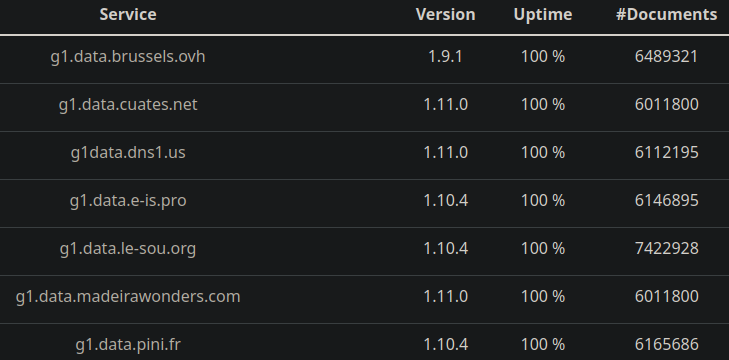
Il peut s’agir de problématiques de synchronisation réseau ou de modération par les responsables de l’instance non reconnues par les autres responsables d’instance.
Je distingue plusieurs étapes :
- l’acceptation (ou non) de la soumission d’une nouvelle donnée
- l’acceptation (ou non) de l’indexation d’une nouvelle donnée
- l’acceptation (ou non) du stockage d’une nouvelle donnée
- le référencement (ou non) d’une donnée
- le re/dé-référencement d’une donnée
- le re/dé-stockage d’une donnée
- la re/désindexation d’une donnée
Pour moi un protocole complet devrait répondre clairement à toutes ces étapes (et en plus à d’autres critères réseau) sans laisser de zones d’ombre, et fournir des mécanismes d’accord/accord partiel/désaccord entre des participants du réseau à toutes ces étapes.
Par la suite, je vais donner des exemples possibles de règles qui devraient être composables à l’envie par les participants du réseau.
- acceptation d’une soumission (essentiellement un rôle d’antispam)
- signature par une clé répondant à un critère interne
- clé présente dans une whitelist faisant partie des données
- contre-signature par un membre du réseau de confiance (par pour déléguer une des règles ci-dessous à un autre nœud du réseau)
- signature par une clé répondant à un critère externe
- clé associée à un compte Ğ1 ayant au moins x unités au moment de la soumission
- clé associée à un compte membre Ǧ1
- clé signée par un autre réseau de confiance (toile PGP, BrightId, UCAN)
- clé signée par un tiers de confiance (numéro de téléphone, service d’identité national…)
- signature par une clé répondant à un critère interne
- acceptation de l’indexation (reconnaître l’existence de la donnée, éventuel rôle politique, ou simplement limitation communautaire ou technique)
- clé absente d’une blacklist (par exemple un numéro de téléphone validé, mais connu pour du spam)
- clé présente dans une whitelist communautaire (par exemple si on souhaite isoler une communauté)
- clé présente dans une whitelist nécessaire pour répondre à des limitations techniques (par exemple pour produire un micro-index sur une machine avec peu de stockage)
- acceptation du stockage (rôle à la fois politique et technique pour garantir l’accès à la donnée)
- clé absente d’une blacklist (par exemple pour du contenu indésirable qu’on ne souhaite pas stocker)
- volume de la donnée trop élevé (quand la ressource en stockage est trop limitée)
- clé présente dans une whitelist d’intérêt (on peut tout à fait reconnaître l’existence de la donnée dans un index mais ne pas être intéressé par en stocker une copie)
- clé répondant à un critère externe (par exemple avoir payé pour le stockage de la donnée)
- référencement (rôle de rendre accessible la donnée sur une interface donnée)
- whitelist/blacklist (on peut souhaiter stocker une donnée mais ne pas la rendre disponible sur un interface pour tout un tas de raisons)
- re/déréférencement
- on doit pouvoir changer l’état de référencement sur des critères arbitraires
- re/dé-stockage
- on doit pouvoir changer l’état de stockage d’une donnée sur un critère arbitraire
- re/désindexation
- l’indexation ou la non-indexation ne doit pas être définitive, on doit pouvoir revenir dessus a posteriori par exemple suite à la modification d’une whitelist / blacklist / critère externe
Voilà donc la direction dans laquelle je voudrais aller mais qui me paraît totalement inatteignable aujourd’hui. Pour moi IPFS répond trop partiellement à la question du pinning et pas assez à la question des pointeurs avec IPLD. Filecoin répond à la question de la méfiance avec le preuves, mais n’est pas très intéressant dans un contexte de confiance.
Comme on veut sortir la v2 dans un temps raisonnable et avec commentaires de transaction et informations de profil, je suis prêt à assumer une infrastructure centralisée. Mais par exemple cela voudra dire que les admins de l’instance auront le dernier mot sur la gestion des données. Par exemple on pourra décider de supprimer des commentaires de transaction s’ils sont utilisés pour faire du harcèlement. Je pense qu’on retombera plus vite que certains ne le pensent dans des problématiques similaires à celles du forum monnaie libre dont sont exclus matiou et mlet. Mais tant qu’on n’a pas de bonne réponse à cette question ça me paraît le moindre mal et mieux que rien (ce qui n’est pas évident, certains préféreraient qu’il n’y ait rien).
Quelques liens pour la route :