Cela fait quelques jours que je travail sur une stack Hasura avec Deno en middleware (et un soupçon de rust) dans le but de stocker toutes les données offchain de Duniter v2s.
Pourquoi Deno ? Parcequ’il permet d’interpréter du TypeScript sans avoir à passer par une étape de transpilation.
Voici une instance en prod: https://gdev-datapod.p2p.legal
Mot de passe: come_on_this_is_demo
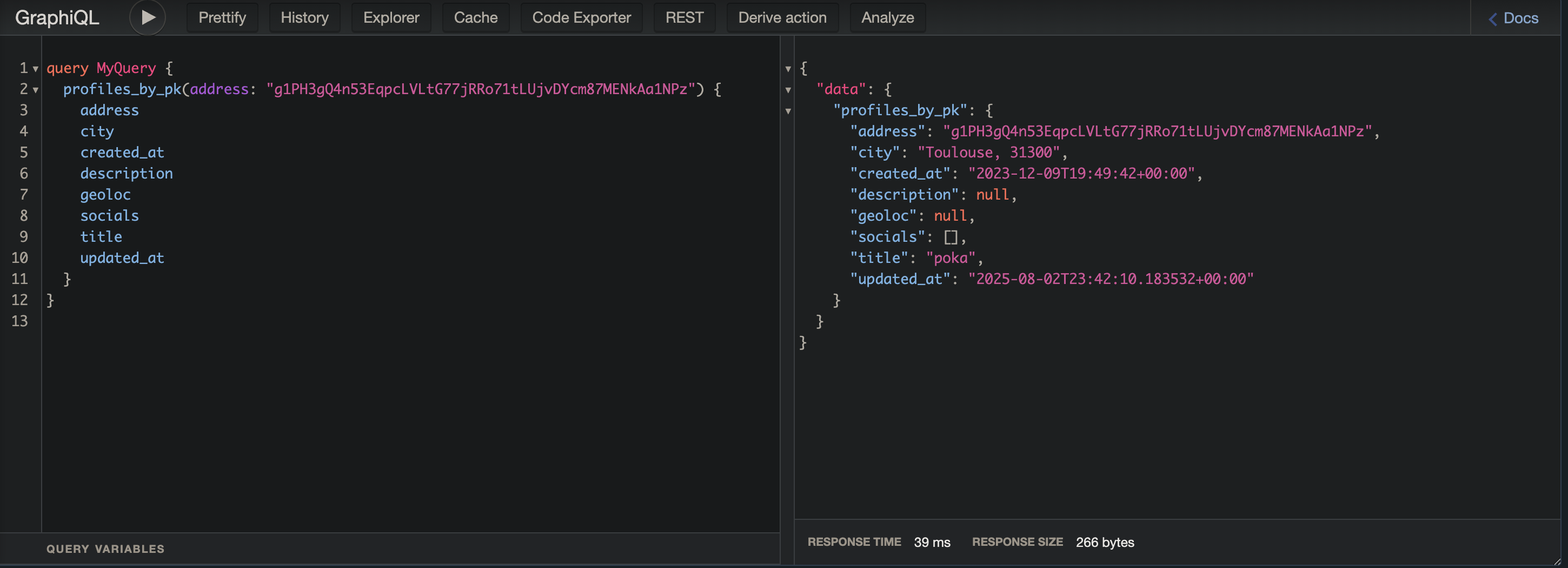
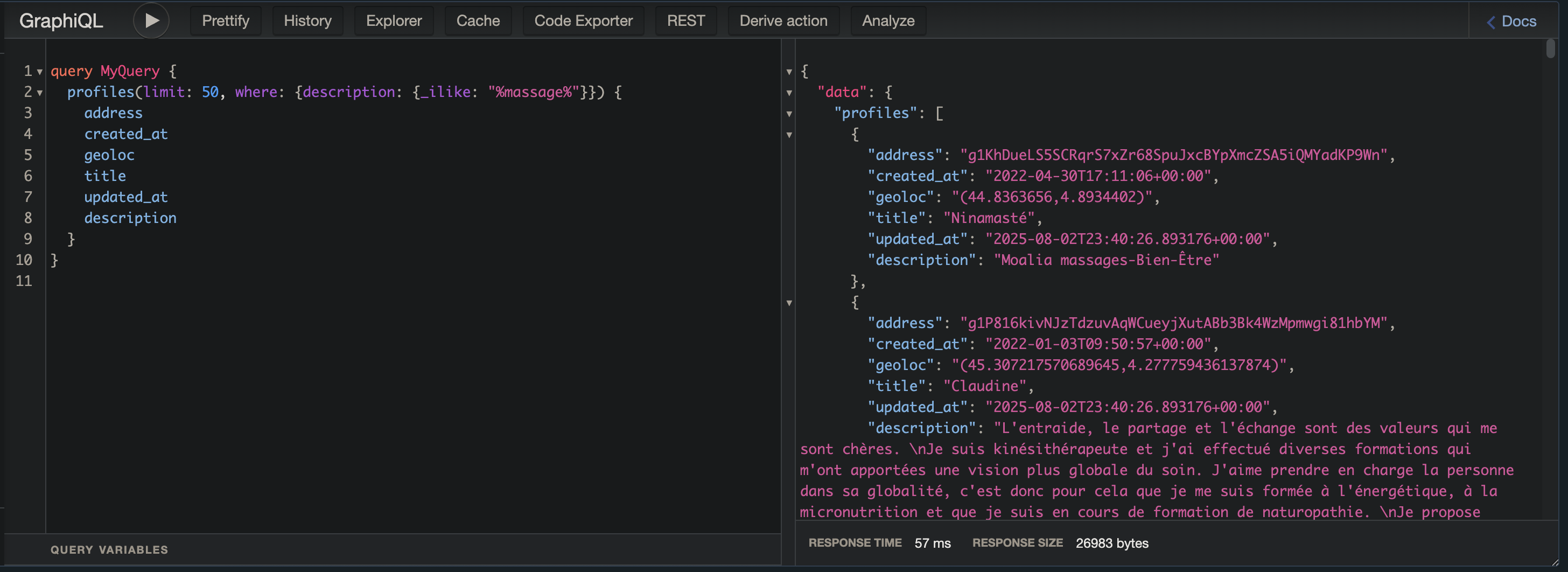
Vous remarquerez que toutes les données de profiles CS+ sont présentes.
Vous trouverez dans la doc à droite le schema pour la mutation d’update de profile:
updateProfile(
address: String!
avatarBase64: String
city: String
description: String
geoloc: GeolocInput
hash: String!
signature: String!
socials: [SocialInput!]
title: String
): UpdateProfileResponse
updateProfile
J’ai globalement repris le même fonctionnement que les pod cs+ pour cette partie d’upload.
Sauf qu’ici, les datapods sont capables de vérifier les signatures ed25519 et sr25519, de manière transparente.
J’ai passé un certain temps à adapter cette stack pour qu’elle soit facilement installable et switchable du mode dev au mode prod ![]()
J’ai pour celà fait certains choix différents de ceux de Manu pour l’indexer (je n’utilise pas l’image spécial d’hasura-migration-tool par exemple pour la migration des metadatas, j’ai fait mon propre script d’init de l’image. J’ai aussi essayé de faire au plus simple sur le merge des composes, même si je trouve ça toujours un peu chiant d’en avoir plusieurs mergés, avec le script load.sh ça passe).
Pour le mode prod, vous n’avez besoin que de 4 fichier dans un dossier, et de docker:
$ tree -a
.
|-- .env
|-- docker-compose.prod.yml
|-- docker-compose.yml
`-- load.sh
Que vous trouverez sur le git.
Et de lancer la commande:
./load.sh log #pour voir les logs, optionnel
En mode dev cependant vous aurez bien sûr besoin de cloner l’ensemble du dépôt, puis:
./load.sh dev
Laïus au sujet des pods Cs+
Avant ça, j’ai commencé à intégrer la gestion des pods Cs+ Ğ1v1 dans Ğecko gdev. Cela fonctionne très bien pur la lecture des avatar des comptes pré-migration, il suffit de convertir à la volée les pubkey ed25519 en ss58, mais le soucis est pour l’écriture: Ğecko génère des clés sr25519, donc les signatures ne sont pas reconnu par les pod Cs+, et les clés ne sont de toutes façon pas les mêmes…
j’ai retourné le problème dans tous les sens, et hormis le choix de ne générer que des clés ed25519 pour les nouveaux comptes, je n’ai pas de solutions simple pour utiliser ces pod cs+ v1 avec v2s.
Après avoir écris le script de migration des données Cs+ en TypeScript, puis en python, j’ai finalement décidé de l’écrire en Rust pour des raisons de performances (TS était plus lent que python pour la même implémentation à mon grand étonnement…).
Tout est dans le même dépôt, et correctement Dockerisé.
Précision importante
Cette stack est pensée pour être très simple à bootstraper et performante, je suis très satisfait du résultat actuel à ce sujet pour le moment.
Mais il faut garder un chose en tête: Il s’agit d’instance totalement centralisé.
J’ai exploré des pistes pour faire les faires évoluer en instances décetralisés et fédérés, j’ai des pistes avec la réplication postegres (d’ailleurs je sais que @aya travail dessus à son boulo), mais je ne pense pas que ce soit une bonne idée de partir dans cette direction.
Je pense que nous visons tous une implémentation de vraies worker offchain pour Duniter v2s, avec gestions de frais et/ou quota sur les données, probablement basé sur IPFS comme le recommande l’équipe substrate et semble se diriger toutes les solutions à ce sujet.
Ces datapods sont donc une proposition, à vous de voir si vous voulez partir sur une solution centralisé de ce type pour la migration, le temps que des workers offchain soient implémenté, ou partir sur autre chose.
Ca m’aura à minima permis de me faire la main sur Deno, Rust, et Hasura.