Je continue à réfléchir sur ce point dans l’espoir de trouver une solution simple et élégante. Le sujet Partager facilement un fichier de configuration pour changer les endpoints par défaut m’a donné des idées. J’aimerais bien récapituler les objectifs que l’on cherche à atteindre par ordre d’importance.
- connecter automatiquement l’utilisateur lambda à un nœud bien synchronisé, avec un bon uptime, et une faible latence, et cela en un temps et une consommation de ressources raisonnable
- ne pas avoir à recompiler l’app et distribuer une mise à jour pour changer la liste des endpoints
- ne pas fournir une liste de endpoints de manière centralisée
- récolter automatiquement des endpoints une fois en place sans intervention nécessaire de la part de l’hébergeur du service, à la manière de duniter v1
Maintenant, je reprends ces points en sens inverse et cherche à en tirer des conclusions.
Récole automatique des endpoints
Dans Duniter v1, cette récole automatique passait directement par la couche réseau p2p une fois un endpoint BMA / WS2P défini dans un fichier de configuration :
"endpoints": [
"BMAS g1.trentesaux.fr 443",
"WS2P 23456abc g1.trentesaux.fr 443 /ws2p"
],
"nobma": false,
"ipv4": "127.0.0.1",
"port": 10900,
"remoteipv4": "78.199.27.8",
"remotehost": "g1.trentesaux.fr",
"remoteport": 443,
"ws2p": {
"uuid": "23456abc",
"privateAccess": true,
"publicAccess": true,
"preferedOnly": false,
"privilegedOnly": false,
"upnp": false,
"host": "127.0.0.1",
"port": 20900,
"remotehost": "g1.trentesaux.fr",
"remoteport": 443,
"remotepath": "/ws2p",
"maxPrivate": 10,
"maxPublic": 10
},
Ici, rien ne garantit que ma configuration est bonne. Je pourrais mettre n’importe quoi, quand même être connecté au réseau, mais que ce qui est déclaré dans ma fiche de pair pointe vers un autre nœud. Donc ça fait une base donnant beaucoup de endpoints mais sur lesquels il faut faire un gros filtre si les utilisateurs ne gèrent pas bien leur config (par ex reverse proxy).
Pour l’instant nous n’avons pas de telle méthode de récolte de endpoints de manière décentralisée dans Duniter v2. Nous pourrions en implémenter une, mais ça me semble un peu compliqué parce qu’il faut toucher à la couche réseau qui n’est pas pensée pour être customisée et qui est relativement bas niveau.
Une autre option serait d’utiliser un ou plusieurs endpoints centralisés comme ceux de la télémétrie. Ils pourraient être indiqués dans les chainspecs, à côté de la télémétrie, et si le nœud reçoit un paramètre “public rpc url”, il fournit ce paramètre au serveur extérieur. Comme ça, pas besoin d’intervention de l’utilisateur autre qu’un paramètre, ce qui peut être configuré automatiquement dans Yunohost par exemple.
On note que toute action de publication en blockchain nécessite les clés de l’utilisateur et donc une action de sa part, donc plus contraignant.
Constituer une liste filtrée de manière non centralisée
Pour répondre au critère de la connexion en un temps raisonnable, il convient de fournir à l’utilisateur une liste filtrée, c’est-à-dire à laquelle on a déjà retiré :
- les endpoints injoignables
- les endpoints sur le mauvais réseau ou désynchronisés
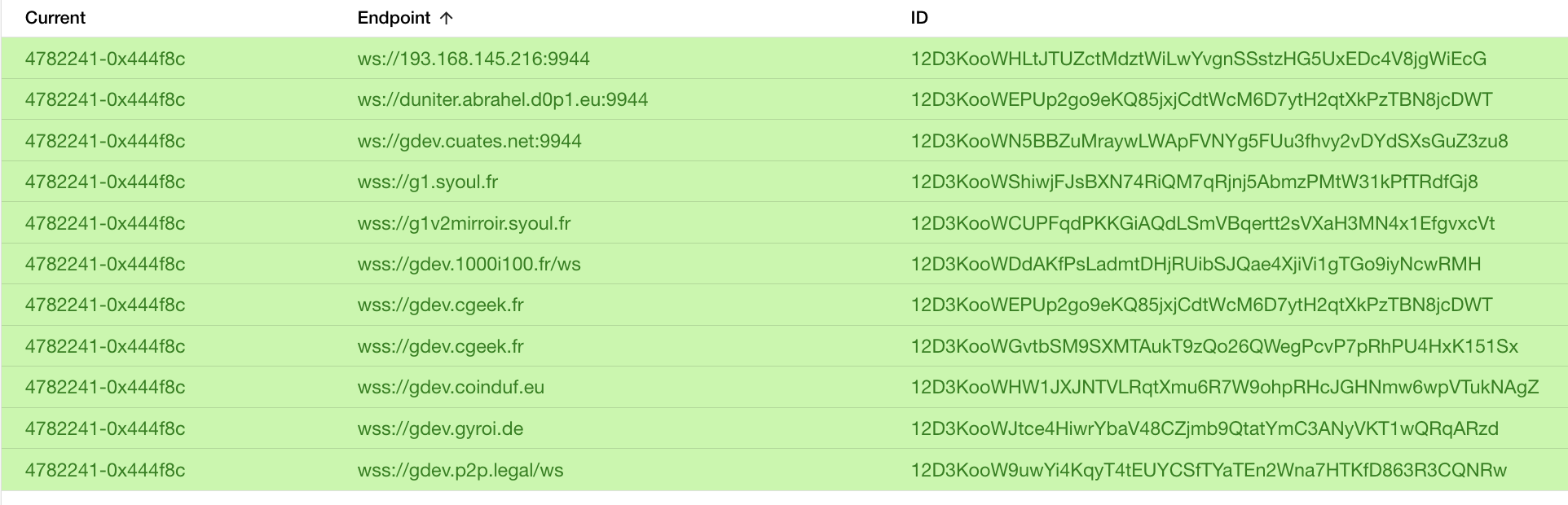
Ce travail doit pouvoir être réalisé par plusieurs instances de “tri” car on ne veut pas que le contrôle de cette liste soit centralisé. Il faut pouvoir récupérer le résultat de ce tri auprès de plusieurs instances, en s’attendant à avoir des résultats légèrement différents de l’une à l’autre.
Ne pas avoir à recompiler l’application
Pour ne pas avoir besoin de recompiler l’application, il faut que les serveurs de bootstrap hard-codés dans l’application soient en mesure de fournir d’autres endpoints pour récupérer la liste de pairs, ce qui permet de faire une découverte du réseau de proche en proche sans se limiter à une liste prédéfinie.
Connecter automatiquement l’utilisateur
Une fois les étapes précédentes établies, voici comment un client peut procéder :
- (uniquement à la première connexion) remplir son local storage avec les nœuds de découverte du réseau hardcodés
- récupérer des listes préfiltrées de serveurs de liste et de endpoints auprès des noeuds présents dans son storage
- effectuer un scan réseau sur les endpoints connus
- se connecter à un endpoint (rpc, graphql, serveur de liste…) ayant bien répondu au scan réseau
À chaque redémarrage ou reconnexion de l’application, refaire un scan réseau pour mettre à jour les listes, et re-récupérer des listes préfiltrées. Le premier scan réseau peut se faire avec la liste des endpoints déjà triés dans le localstorage pour un démarrage rapide. Un deuxième scan réseau peut être lancé en arrière plan pour mettre à jour les listes.
Voilà un ensemble de souhaits de fonctionnalités assez large et complet. Pour l’instant, rien n’est implémenté :
- récolte automatique des endpoints
- constitution de listes pré-filtrées côté serveur
- exposition de liste pré-filtrées et récupération par le client
- scan réseau côté client et sélection automatique des endpoints utilisés pour la session
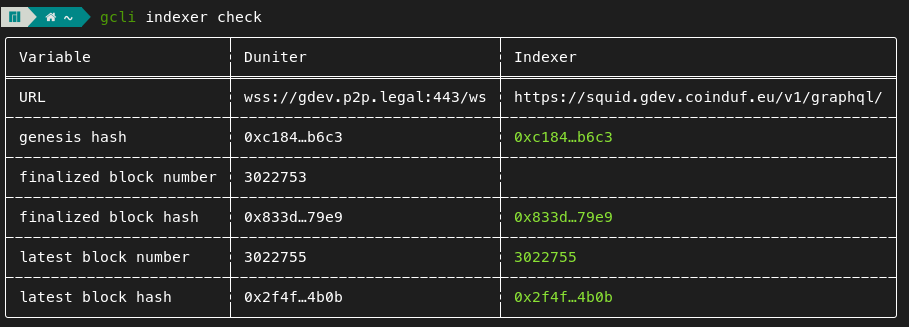
Seul le check de synchro entre le endpoint rpc et l’indexeur existe (gcli, duniter panel). La prochaine étape est donc de fournir une solution généraliste pour éviter de réinventer la roue pour chaque type de endpoint (rpc, graphql, serveur de liste, datapod…).